La technologie de reprise après sinistre associe systèmes de sauvegarde, infrastructure répliquée, environnements de secours, procédures de restauration, outils de supervision et plans opérationnels pour rétablir les services métier après une défaillance majeure. Elle aide les organisations à se remettre d’événements tels qu’une panne matérielle, une corruption de données, un rançongiciel, un incendie, une inondation, une coupure électrique, une interruption de service cloud, un effondrement réseau, une suppression accidentelle ou une perturbation complète de site.
Son objectif n’est pas seulement de « sauvegarder les données ». Une conception complète doit remettre les applications, bases de données, serveurs, systèmes d’identité, plateformes de communication, routes réseau, accès utilisateurs, politiques de sécurité et flux opérationnels dans un état exploitable. C’est pourquoi la reprise après sinistre relève à la fois de l’architecture technique et de la continuité d’activité.
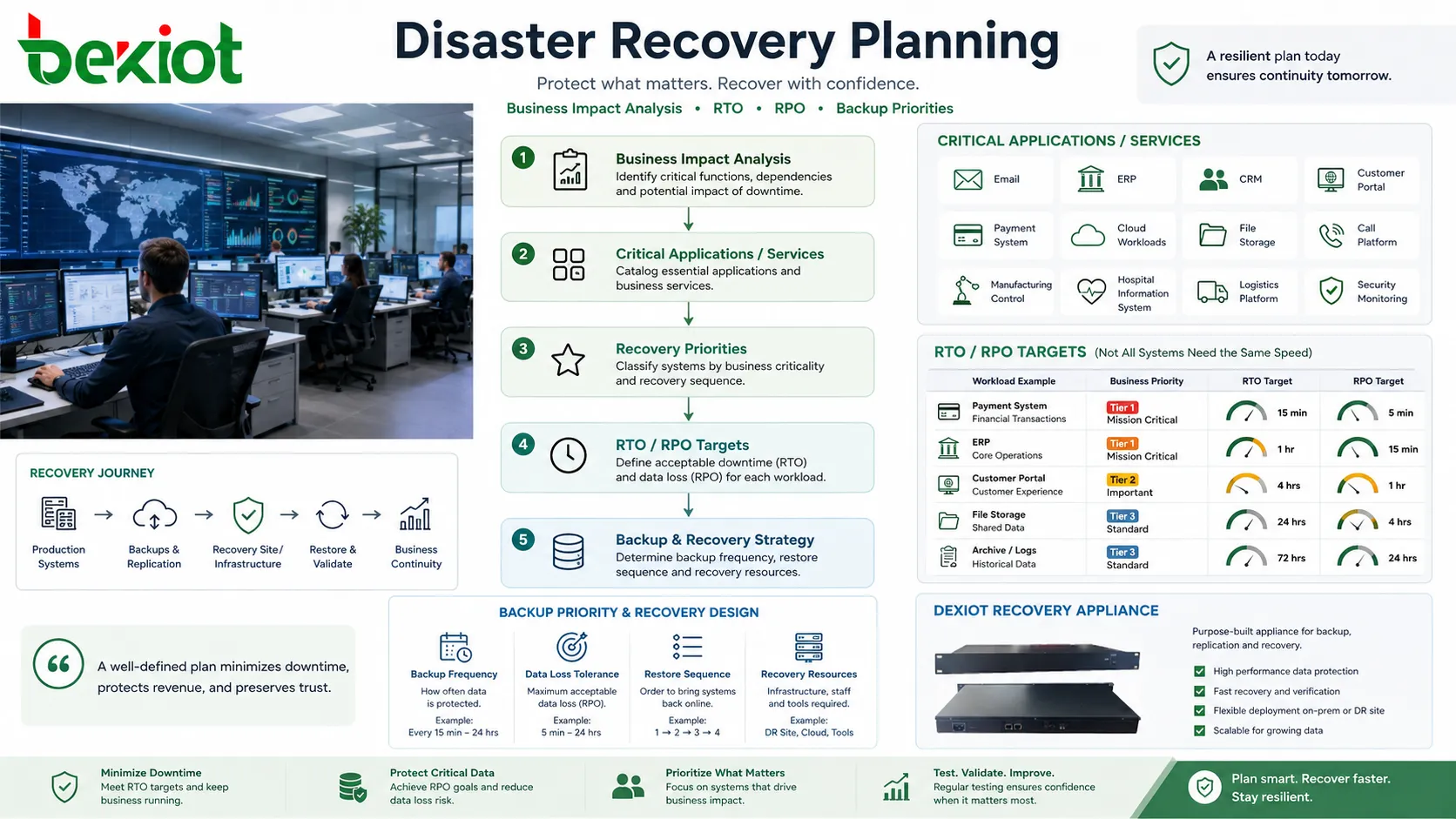
Commencer par l’impact métier
Un plan fiable commence par l’identification des services réellement critiques. Messagerie, ERP, CRM, portails clients, systèmes de paiement, charges de travail cloud, stockage de fichiers, plateformes d’appels, systèmes de contrôle de production, systèmes d’information hospitaliers, plateformes logistiques et supervision de sécurité peuvent avoir des priorités de reprise très différentes.
Tous les systèmes n’ont pas besoin de la même vitesse de reprise. Un système transactionnel public peut devoir revenir en quelques minutes, tandis qu’un système d’archivage peut tolérer plusieurs heures. Traiter toutes les charges comme également urgentes augmente les coûts et la complexité. Sous-estimer des charges importantes augmente le risque métier.
Deux notions sont souvent utilisées pendant la planification. Le Recovery Time Objective, ou RTO, définit la rapidité avec laquelle un service doit être restauré. Le Recovery Point Objective, ou RPO, définit la perte de données acceptable, mesurée dans le temps. Par exemple, un RPO de 15 minutes signifie que l’organisation doit pouvoir restaurer les données à un point situé au maximum 15 minutes avant la panne.
Les couches essentielles de la technologie
Couche de protection des données
La première couche technique protège les données. Elle peut inclure sauvegarde complète, sauvegarde incrémentielle, sauvegarde différentielle, snapshots, protection continue des données, sauvegarde immuable, export de base de données, versionnement du stockage objet et réplication hors site.
Une bonne protection doit offrir plusieurs points de restauration. Si la sauvegarde la plus récente contient des données corrompues ou chiffrées, l’organisation peut devoir revenir à une version propre plus ancienne. C’est particulièrement important lors d’un rançongiciel ou d’une suppression accidentelle.
Couche de reprise du calcul
Les données seules ne suffisent pas. Les applications ont besoin de serveurs, machines virtuelles, conteneurs, systèmes d’exploitation, environnements d’exécution, middleware, licences et fichiers de configuration. La couche de calcul définit où les charges de travail s’exécuteront lorsque l’environnement principal échoue.
La capacité de calcul de secours peut être préparée dans un autre centre de données, une région cloud, un cluster de secours, une plateforme virtualisée ou un environnement de reprise managé. Plus l’environnement est prêt, plus la reprise peut être rapide.
Couche de continuité réseau
Après la restauration des systèmes, les utilisateurs et les autres systèmes doivent pouvoir les atteindre. Cela nécessite routes réseau, mises à jour DNS, accès VPN, règles de pare-feu, répartiteurs de charge, plans d’adressage IP, certificats, politiques NAT et accès distant sécurisé.
La reprise réseau est souvent sous-estimée. Une application peut fonctionner sur le site de secours, mais rester inaccessible parce que les enregistrements DNS, tables de routage, chemins d’identité ou règles de pare-feu n’ont pas été mis à jour.
Couche identité et accès
Utilisateurs, administrateurs, applications et comptes de service ont besoin d’authentification et d’autorisation après une panne. Si les services d’identité sont indisponibles, de nombreuses applications restaurées resteront inutilisables.
Services d’annuaire, systèmes MFA, autorités de certification, outils d’accès privilégié, coffres de mots de passe et plateformes SSO doivent être intégrés à la planification. Un site de secours sans contrôle d’identité opérationnel peut devenir un problème de sécurité et d’exploitation.
Couche d’orchestration opérationnelle
La reprise exige des actions dans le bon ordre. Les bases de données peuvent devoir démarrer avant les applications. Les règles réseau peuvent devoir changer avant la connexion des utilisateurs. Le stockage doit être monté avant le lancement des services. La supervision doit confirmer que le système restauré est sain.
Les outils d’orchestration automatisent ces étapes. Ils peuvent démarrer des charges, appliquer des scripts, mettre à jour des configurations, déclencher un basculement, valider les dépendances et générer des rapports de reprise. L’automatisation réduit les erreurs humaines pendant les incidents stressants.
Déroulement habituel du processus
Détection et confirmation de l’incident
Le processus commence lorsque des outils de supervision, des utilisateurs, des administrateurs ou des systèmes de sécurité détectent un événement anormal. Il peut s’agir d’une panne serveur, d’une erreur de base de données, d’une interruption de stockage, d’une alerte rançongiciel, d’un crash applicatif, d’une perte d’alimentation de site ou d’un problème de région cloud.
L’équipe doit confirmer si l’événement nécessite une reprise complète, une restauration partielle ou une réparation locale. Toute panne ne doit pas déclencher un basculement complet. Un petit problème applicatif peut être résolu plus vite que l’activation d’un environnement secondaire.
Décision et activation
Une fois l’incident confirmé, le personnel autorisé décide d’activer ou non le plan de reprise. La décision doit tenir compte de l’impact métier, de la durée d’indisponibilité attendue, du risque de sécurité, de l’impact client, de l’intégrité des données et de la possibilité de restaurer rapidement le site principal.
Une autorité de décision claire est essentielle. Si personne ne sait qui peut approuver le basculement, l’organisation peut perdre un temps précieux pendant un incident grave.
Restauration des données ou basculement de réplication
L’environnement de reprise a besoin de données utilisables. Si le design utilise des sauvegardes, l’équipe restaure les données depuis un point choisi. Si le design utilise la réplication, la copie de secours peut être promue pour un usage actif.
Le choix des données est critique. Restaurer la copie la plus récente n’est pas toujours correct si la corruption ou le malware a déjà atteint cette copie. Les équipes peuvent devoir identifier le dernier point propre de reprise.
Redémarrage des services et ordre des dépendances
Les applications sont redémarrées selon leurs dépendances. Bases de données, stockage, services d’identité, middleware, serveurs applicatifs, interfaces web, API et intégrations peuvent nécessiter une séquence définie.
Ignorer cet ordre peut créer des pannes difficiles à comprendre. Une application restaurée peut sembler cassée simplement parce que la base de données, le serveur de licences, la file de messages ou l’enregistrement DNS n’est pas prêt.
Validation avant remise en service
Avant le retour des utilisateurs, l’équipe doit valider le bon fonctionnement de l’environnement restauré. Cela peut inclure tests de connexion, contrôles de cohérence des données, tests transactionnels, tests d’appel, vérifications API, génération de rapports, revue de sécurité et confirmation de supervision.
Ce n’est qu’après validation que l’environnement de reprise doit être considéré comme le service de production actif. Une reprise rapide mais non vérifiée peut créer perte de données, failles de sécurité ou confusion utilisateur.
La reprise après sinistre fonctionne mieux lorsqu’elle n’est pas traitée comme une simple tâche de sauvegarde, mais comme le redémarrage coordonné des données, systèmes, réseaux, identités, utilisateurs et processus métier.
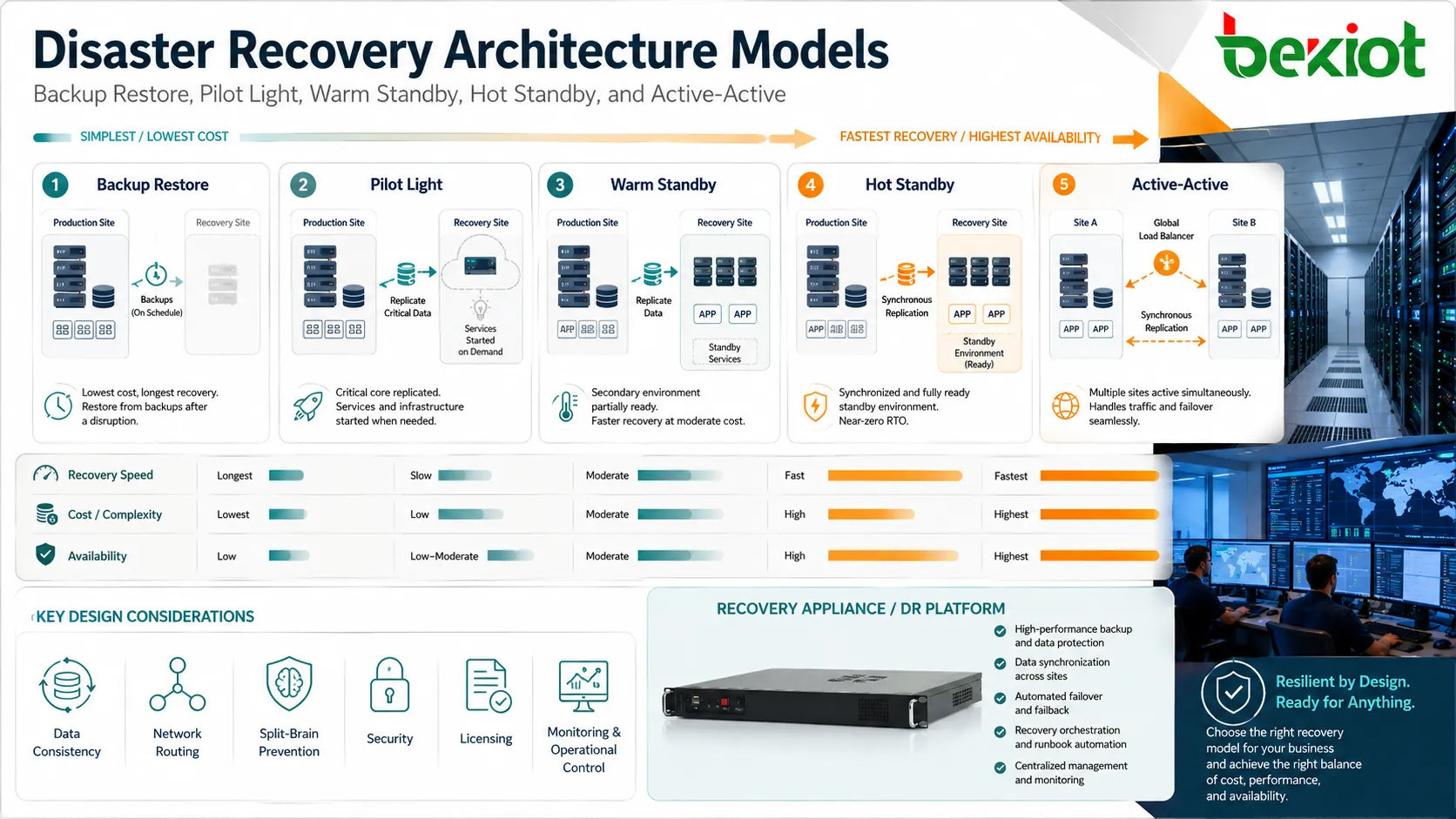
Principaux modèles d’architecture
Sauvegarde et restauration
Le modèle le plus simple stocke des sauvegardes et les restaure au besoin. Il est généralement moins coûteux, mais plus lent, car serveurs, applications, données et configurations peuvent devoir être reconstruits ou restaurés manuellement.
Ce modèle peut convenir aux systèmes non critiques, petites entreprises, charges d’archivage ou applications acceptant une indisponibilité plus longue. Il doit tout de même être testé, car des sauvegardes non testées peuvent échouer en situation réelle.
Environnement pilote minimal
Une conception de type pilot light maintient en service un environnement de reprise minimal. Les composants centraux comme bases de données, fondation réseau, services d’identité ou modèles de configuration peuvent déjà exister, tandis que les serveurs applicatifs ne sont mis à l’échelle que pendant la reprise.
Cette approche équilibre coût et vitesse. Elle est plus rapide qu’une reconstruction complète, mais moins chère que l’exploitation permanente d’un double environnement complet.
Secours tiède
Un environnement de secours tiède maintient davantage de systèmes prêts à l’avance. Les données peuvent être répliquées régulièrement et les services applicatifs installés et partiellement actifs. Pendant un incident, l’environnement est étendu, promu ou reconfiguré pour recevoir le trafic de production.
Ce modèle est utile lorsque l’indisponibilité doit être réduite, mais qu’un site secondaire totalement actif coûte trop cher.
Secours chaud ou actif-actif
Les conceptions les plus rapides gardent un environnement secondaire synchronisé en continu et prêt à servir les utilisateurs. Dans les architectures actif-actif, plusieurs sites peuvent traiter du trafic réel en même temps, avec équilibrage de charge et réplication entre sites.
Ces modèles réduisent l’arrêt, mais exigent une conception rigoureuse. Cohérence des données, routage réseau, prévention du split-brain, licences, sécurité, supervision et contrôle opérationnel deviennent plus complexes.
Fonctionnalités techniques importantes
Planification automatique des sauvegardes
Les calendriers automatiques réduisent la dépendance aux opérations manuelles. Les systèmes peuvent créer des sauvegardes horaires, quotidiennes, hebdomadaires ou continues selon le RPO requis.
Les calendriers doivent être alignés sur le comportement des charges. Une base de données qui change chaque minute nécessite une stratégie différente de celle d’une archive documentaire statique.
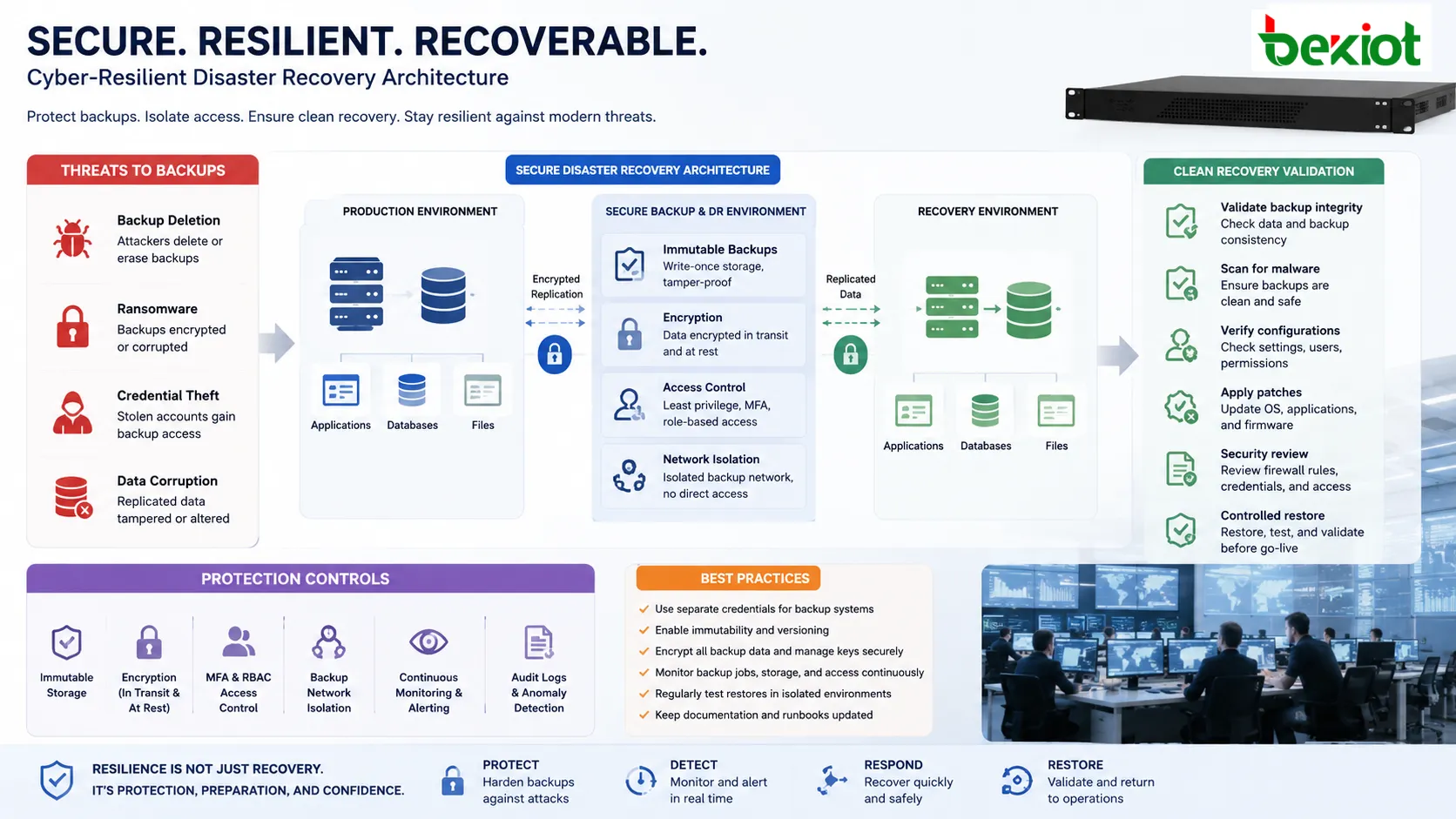
Copies immuables et hors ligne
Les sauvegardes immuables ne peuvent pas être modifiées ni supprimées pendant une période définie. Les copies hors ligne ou isolées sont séparées de l’environnement actif. Ces protections sont importantes contre les rançongiciels, menaces internes, suppressions accidentelles et comptes administrateur compromis.
Un plan qui stocke toutes les sauvegardes dans le même environnement compromis peut échouer au moment où il est le plus nécessaire.
Réplication et synchronisation
La réplication copie les données de l’environnement principal vers un autre emplacement. Elle peut être synchrone, lorsque les écritures sont validées des deux côtés avant la fin, ou asynchrone, lorsque les changements sont copiés peu après leur apparition.
La réplication synchrone peut réduire la perte de données, mais nécessite des liens à faible latence et peut affecter les performances. La réplication asynchrone est plus flexible à distance, mais peut perdre des changements récents si le site principal tombe soudainement.
Protection consciente de l’application
La protection consciente de l’application comprend la charge sauvegardée. Bases de données, systèmes de messagerie, machines virtuelles, serveurs de fichiers et applications d’entreprise peuvent nécessiter des étapes spéciales pour garantir des sauvegardes cohérentes.
Par exemple, copier des fichiers de base de données pendant qu’ils changent peut ne pas produire un point de restauration propre. Les snapshots applicatifs et la gestion des journaux de transactions peuvent améliorer la qualité de reprise.
Automatisation de la reprise
L’automatisation peut démarrer des machines virtuelles, attacher du stockage, mettre à jour des règles réseau, exécuter des scripts, ajuster DNS, vérifier les services et produire des enregistrements d’incident. Elle réduit le travail manuel et rend la reprise plus répétable.
La reprise manuelle peut fonctionner dans de petits environnements, mais les systèmes complexes ont généralement besoin de workflows documentés et automatisés pour limiter les erreurs sous pression.
Applications selon les environnements
Systèmes informatiques d’entreprise
Les entreprises utilisent la technologie de reprise pour protéger ERP, CRM, messagerie, systèmes d’identité, partages de fichiers, bases de données, plateformes intranet et applications métier. L’objectif est de maintenir les opérations essentielles disponibles après des incidents majeurs.
Ces environnements exigent souvent une reprise par niveaux. Les applications critiques reçoivent des objectifs plus rapides, tandis que les systèmes moins urgents utilisent une protection moins coûteuse.
Infrastructure cloud et hybride
Les environnements cloud prennent en charge snapshots, réplication interrégion, infrastructure as code, bases de données managées, versionnement du stockage objet et modèles de basculement automatisés. Les systèmes hybrides peuvent combiner centres de données sur site et ressources de reprise cloud.
La reprise cloud peut réduire le besoin d’un centre de données secondaire complet, mais elle nécessite toujours planification réseau, conception de sécurité, contrôle des coûts et tests réguliers.
Opérations industrielles et services essentiels
Usines, centrales électriques, systèmes de traitement de l’eau, sites pétroliers et gaziers et centres logistiques peuvent nécessiter des plans de reprise pour systèmes de contrôle, historiques, serveurs de supervision, plateformes de communication et postes opérateur.
Ces environnements doivent tenir compte de la sûreté, du contrôle de processus en temps réel, des protocoles hérités, de l’accès aux équipements de terrain et du contrôle strict des changements. La reprise ne doit pas créer de conditions d’exploitation dangereuses.
Santé et services publics
Hôpitaux, centres d’intervention d’urgence, services gouvernementaux et installations publiques doivent accéder aux dossiers, communications, plannings, systèmes de sécurité et données opérationnelles pendant les perturbations.
La planification doit inclure confidentialité, pistes d’audit, impact sur patients ou citoyens, procédures d’urgence et accès du personnel dans des conditions anormales.
Télécoms et services de communication
Les plateformes de communication nécessitent une reprise pour contrôle d’appels, routage, services média, enregistrement, messagerie vocale, trunks SIP, passerelles, plateformes de centre de contact et données d’enregistrement des utilisateurs.
Comme ces systèmes soutiennent souvent l’intervention d’urgence et la relation client, les tests doivent inclure de vrais flux d’appels plutôt que le simple démarrage de serveurs.
Intégrité des données et cybersécurité
La planification moderne doit supposer que les cyberattaques peuvent viser les sauvegardes autant que les systèmes de production. Les attaquants peuvent supprimer des sauvegardes, chiffrer des dépôts, voler des identifiants ou corrompre des données répliquées. L’isolement, le contrôle d’accès, l’immutabilité, le chiffrement et la supervision sont donc essentiels.
Les données de reprise doivent être protégées en transit et au repos. Les clés de chiffrement doivent être gérées avec soin, car leur perte peut rendre la reprise impossible. Les dépôts de sauvegarde ne doivent pas utiliser les mêmes identifiants et permissions que les comptes de production ordinaires.
La validation de sécurité après reprise est également importante. Restaurer un système depuis une sauvegarde peut aussi restaurer des logiciels obsolètes, des configurations vulnérables ou des comptes compromis. Les équipes doivent vérifier correctifs, identifiants, règles de pare-feu et sécurité des terminaux avant de rendre le service aux utilisateurs.
Tests et exercices de préparation
Un plan jamais testé n’est qu’une hypothèse. Les tests confirment que les sauvegardes sont restaurables, que les applications démarrent correctement, que les utilisateurs peuvent se connecter, que les données sont cohérentes, que les routes réseau fonctionnent et que le personnel sait quoi faire.
Les tests peuvent être réalisés à plusieurs niveaux. Un test de restauration de fichier vérifie la récupération d’une donnée individuelle. Un test applicatif vérifie la reprise d’un service. Une simulation complète teste la panne d’un site entier et le processus de basculement.
Les exercices doivent être documentés. L’équipe doit consigner le temps de reprise, les problèmes trouvés, les accès manquants, les scripts échoués, la documentation obsolète et les actions correctives. Chaque test doit améliorer le plan.
Points de défaillance courants
Sauvegardes jamais restaurées
De nombreuses organisations découvrent trop tard que leurs jobs de sauvegarde se terminaient correctement, mais que les données ne peuvent pas être restaurées. Cela peut venir de fichiers corrompus, dépendances manquantes, identifiants erronés, versions non prises en charge ou données applicatives incomplètes.
Le test de restauration est le seul moyen fiable de prouver que les données sauvegardées sont utiles.
Fichiers de configuration manquants
Les applications peuvent dépendre de fichiers de configuration, certificats, variables d’environnement, tables de routage, règles de pare-feu, licences et comptes de service. Si ces éléments ne sont pas protégés, les données peuvent être restaurées mais l’application ne pas fonctionner.
La sauvegarde de configuration doit faire partie du périmètre de reprise.
Responsabilités floues
Pendant un incident, la confusion sur les décideurs peut ralentir la reprise. Informatique, sécurité, opérations, responsables métier, équipes cloud et fournisseurs peuvent tous être impliqués.
Le plan doit définir rôles, autorité d’approbation, contacts d’escalade et canaux de communication avant la crise.
Réplication de mauvaises données
La réplication est utile, mais elle peut copier corruption, suppression ou fichiers chiffrés vers le site secondaire. C’est pourquoi la restauration dans le temps et les sauvegardes immuables restent importantes même avec la réplication.
La réplication améliore la continuité ; elle ne remplace pas les points de reprise historiques propres.
Accès réseau non prêt
Une application restaurée n’est pas utile si les utilisateurs ne peuvent pas l’atteindre. DNS, VPN, pare-feu, répartiteur de charge, certificat, routage et dépendances d’identité doivent être inclus dans les tests de reprise.
La préparation réseau fait souvent la différence entre une restauration technique et un service réellement utilisable.
La vraie mesure d’une technologie de reprise n’est pas de savoir si les données existent quelque part. C’est de savoir si les bonnes personnes peuvent reprendre le bon service, en sécurité, dans la fenêtre de temps requise.
Liste de contrôle de mise en œuvre
Classez les systèmes par priorité métier. Définissez RTO et RPO pour chaque service au lieu d’utiliser une cible générique pour tout.
Choisissez la bonne méthode de protection. Sauvegarde-restauration, snapshots, réplication, environnements de secours et architectures actif-actif répondent à des besoins et coûts différents.
Protégez les copies contre le risque cyber. Utilisez immutabilité, identifiants séparés, chiffrement, moindre privilège, supervision des sauvegardes et copies hors ligne ou isolées lorsque c’est approprié.
Documentez les étapes de reprise. Incluez dépendances système, ordre de démarrage, changements réseau, méthodes de connexion, contacts fournisseurs, exigences de licence et tests de validation.
Testez régulièrement. Un processus de reprise doit être pratiqué avant un incident réel. Mettez le plan à jour après changements d’infrastructure, migrations cloud, mises à niveau applicatives et changements de politique de sécurité.
FAQ
L’hébergement cloud fournit-il automatiquement une reprise après sinistre?
Non. Les plateformes cloud fournissent des outils utiles, mais le client doit encore configurer sauvegardes, réplication, régions, permissions, supervision, procédures de reprise et tests.
À quelle fréquence faut-il tester les plans de reprise?
La fréquence dépend du risque métier et de la criticité du système. Les systèmes critiques peuvent nécessiter des exercices réguliers, tandis que les systèmes moins importants peuvent être testés lors de revues programmées ou après de grands changements.
Un rançongiciel peut-il affecter les systèmes de sauvegarde?
Oui. Les attaquants peuvent viser les dépôts de sauvegarde et les identifiants administrateur. Copies immuables, copies hors ligne, permissions séparées et supervision aident à réduire ce risque.
Quelle est la différence entre haute disponibilité et reprise après sinistre?
La haute disponibilité vise à maintenir les services en fonctionnement lors de petites pannes. La reprise après sinistre vise à restaurer les services après des perturbations plus importantes, y compris panne de site, cyberattaque ou perte majeure de données.
Que faut-il revoir après un événement réel de reprise?
Examinez le temps de reprise, la perte de données, les étapes échouées, les lacunes de communication, l’impact utilisateur, les constats de sécurité, la réponse fournisseur, l’exactitude de la documentation et les améliorations nécessaires avant le prochain incident.