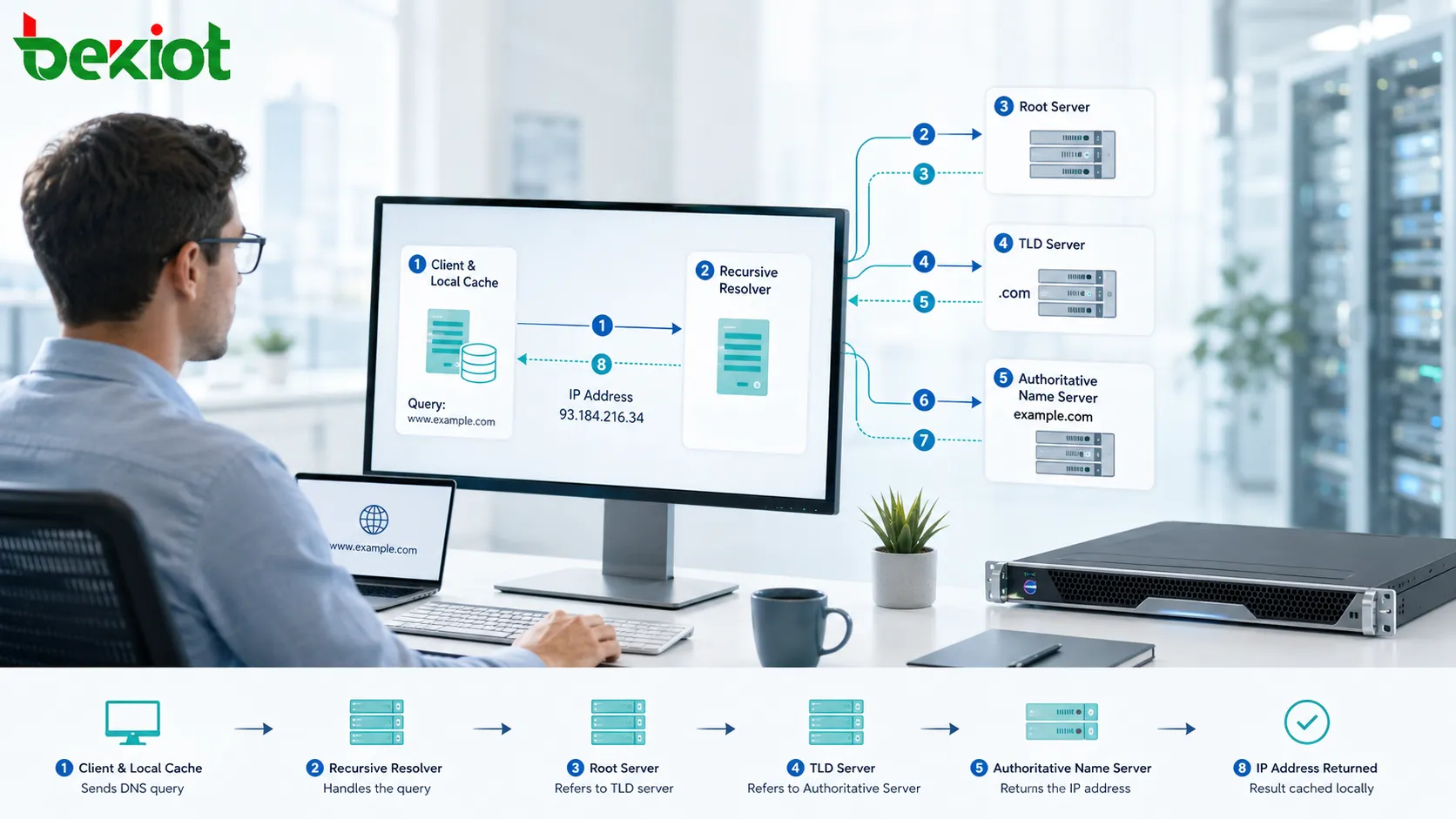
Une entreprise dotée d’un seul bureau peut souvent résoudre ses problèmes réseau en ajoutant un commutateur, en mettant à niveau un routeur ou en ajustant une règle de pare-feu. Une organisation répartie sur de nombreux sites fait face à un défi différent : chaque agence, usine, entrepôt, campus, centre de données, région cloud et point d’accès distant devient une partie du même système opérationnel. Sans planification, ces connexions peuvent produire des accès fragmentés, des ressources dupliquées, une sécurité incohérente, un dépannage lent et une collaboration instable.
Angle sectoriel :la valeur d’un réseau distribué ne se limite plus à la connectivité de base. Les organisations modernes l’utilisent pour l’accès cloud, les communications unifiées, la supervision à distance, la vidéosurveillance, les plateformes IoT, la gestion centralisée, la reprise après sinistre, l’accès zero trust et les applications métier en temps réel. La question n’est pas seulement de connecter différents lieux, mais de transformer ces connexions en une base de services contrôlable et intelligente.
Exploiter pleinement cette architecture signifie la considérer comme une plateforme numérique stratégique. Chaque site ne doit pas fonctionner comme une île isolée. Il doit partager les bonnes ressources, appliquer les bonnes règles de sécurité, échanger les données nécessaires et rester résilient lorsque des liens, équipements ou services échouent.
De la connectivité des agences à l’intégration opérationnelle
Le premier objectif de l’interconnexion de plusieurs sites était généralement simple : permettre aux utilisateurs des agences d’accéder aux systèmes du siège. Ce modèle utilisait souvent des lignes louées, des tunnels VPN, des liens WAN privés ou des connexions point à point. Il réglait l’accès, mais ne créait pas toujours des opérations numériques flexibles.
Aujourd’hui, l’environnement d’exploitation est plus complexe. Les applications peuvent s’exécuter dans le cloud public, le cloud privé, des serveurs edge, des centres de données locaux ou des plateformes SaaS. Les utilisateurs travaillent depuis des bureaux, véhicules, domiciles, sites terrain et appareils mobiles. Les menaces peuvent venir d’Internet, de terminaux compromis, de services cloud mal configurés ou de mouvements latéraux internes.
En raison de cette évolution, une architecture distribuée doit faire plus que transporter du trafic. Elle doit soutenir les performances applicatives, l’accès basé sur l’identité, les politiques centralisées, la segmentation, la supervision, l’automatisation et la résilience sur tous les sites connectés.

Définir le rôle de chaque emplacement
Tous les emplacements n’ont pas la même fonction. Un siège peut héberger des systèmes métier centraux, des équipes de direction, des salles de données et des équipements de sécurité centraux. Une usine peut privilégier les technologies opérationnelles, la supervision de production, les terminaux industriels et les systèmes de contrôle locaux. Un entrepôt peut se concentrer sur les codes-barres, la logistique, les caméras, la couverture sans fil et les terminaux portables. Un petit bureau peut seulement nécessiter un accès sécurisé aux applications cloud et aux services voix partagés.
Avant l’optimisation, chaque site doit être classé selon son rôle métier, ses dépendances applicatives, son nombre d’utilisateurs, ses types de trafic, ses exigences de disponibilité et sa sensibilité de sécurité. Cette classification aide à déterminer la bande passante, le routage, la redondance, la segmentation, le choix des équipements, la profondeur de supervision et le modèle de support.
Sans cette étape, les organisations risquent de suréquiper les petits sites et de sous-protéger les sites critiques. Un bon design aligne le niveau réseau sur l’importance métier de chaque emplacement.
Construire un modèle de connectivité clair
Un environnement distribué peut utiliser MPLS, Internet haut débit, 4G/5G, fibre privée, faisceaux hertziens, satellite, VPN, SD-WAN ou connectivité hybride. Chaque option présente des caractéristiques différentes de performance, coût, fiabilité et gestion.
Les liens WAN privés traditionnels offrent une performance maîtrisée, mais peuvent être coûteux et longs à déployer. Le VPN Internet est flexible et économique, mais ses performances peuvent varier. Le SD-WAN peut combiner plusieurs liens, orienter le trafic selon les politiques applicatives et fournir une orchestration centralisée. Les liens cellulaires permettent un déploiement rapide ou une connectivité de secours. Le satellite couvre les sites distants sans liaison terrestre.
Le meilleur modèle est souvent hybride. Les sites critiques peuvent utiliser deux liens. Les petites agences peuvent associer haut débit et secours cellulaire. Les sites industriels distants peuvent utiliser une fibre privée ou un backhaul sans fil. Le trafic cloud peut accéder directement aux plateformes cloud au lieu de repasser par le siège.
Utiliser la gestion centralisée sans perdre la résilience locale
La gestion centralisée permet de configurer, superviser, mettre à jour et sécuriser de nombreux sites depuis une seule plateforme. Elle réduit les erreurs de configuration manuelle, améliore la standardisation et rend l’exploitation à grande échelle plus efficace.
Cependant, la centralisation ne doit pas créer un point de défaillance unique. Une agence ne devrait pas s’arrêter entièrement parce qu’elle perd temporairement le contact avec le contrôleur central. Selon l’importance du site, une sortie locale, des politiques en cache, un routage de secours, DHCP local, transfert DNS local et chemins de communication d’urgence peuvent être nécessaires.
L’objectif est un contrôle équilibré. L’organisation doit administrer de manière cohérente depuis le centre tout en permettant aux sites de poursuivre les opérations essentielles en cas de panne de lien ou de contrôleur.
Segmenter le trafic par fonction et par risque
La segmentation est essentielle dans une architecture distribuée. Le trafic utilisateur, voix, vidéosurveillance, Wi-Fi invité, systèmes de contrôle industriel, paiement, serveurs, interfaces de gestion et IoT ne doivent pas partager le même espace de sécurité.
VLAN, VRF, zones de pare-feu, listes de contrôle d’accès, microsegmentation, politiques zero trust et groupes de sécurité définis par logiciel peuvent séparer le trafic. Le but est de réduire les risques, contrôler l’accès et empêcher qu’une zone compromise affecte toute l’organisation.
La segmentation doit suivre la logique métier. Par exemple, un utilisateur Wi-Fi invité ne doit pas atteindre les serveurs internes. Un réseau de caméras peut envoyer la vidéo vers une plateforme de stockage, mais ne doit pas accéder aux postes bureautiques. Les terminaux industriels peuvent nécessiter des chemins stricts vers les systèmes de contrôle et serveurs de supervision.
Optimiser les chemins applicatifs
La performance applicative est l’une des principales raisons de moderniser la connectivité multisite. Les utilisateurs ne jugent pas le réseau par ses schémas de liens ; ils le jugent par des appels clairs, des tableaux de bord rapides, des fichiers synchronisés, des flux vidéo stables et des systèmes métier réactifs.
Le routage conscient des applications peut choisir les chemins selon la latence, la perte de paquets, la gigue, la bande passante et la priorité de service. La voix et la vidéo exigent une faible latence et une faible gigue. Les transferts de fichiers tolèrent le délai mais demandent de la bande passante. Les applications cloud peuvent bénéficier d’une sortie Internet directe. Les données sensibles peuvent nécessiter une inspection via des passerelles de sécurité.
L’ingénierie du trafic doit s’appuyer sur le comportement réel des applications. Un modèle générique « tout le trafic via le siège » peut devenir inefficace lorsque la plupart des applications sont hébergées dans le cloud.
Renforcer l’accès cloud et SaaS
L’accès cloud a transformé la conception réseau. De nombreuses organisations utilisent des plateformes SaaS, des charges cloud publiques, des services d’identité, du stockage cloud, des bureaux distants et des systèmes métier pilotés par API. Si tout le trafic cloud passe obligatoirement par un centre de données central, les utilisateurs subissent des délais inutiles.
L’accès direct au cloud peut améliorer les performances, mais il doit être sécurisé. Cela peut impliquer des passerelles web sécurisées, des fonctions CASB, des politiques basées sur l’identité, la sécurité DNS, des contrôles de posture des terminaux et l’inspection du trafic chiffré lorsque c’est approprié.
La connectivité cloud doit aussi être planifiée pour la fiabilité. Les charges critiques peuvent nécessiter des régions cloud redondantes, des interconnexions dédiées, des liens Internet de secours ou des politiques de basculement.
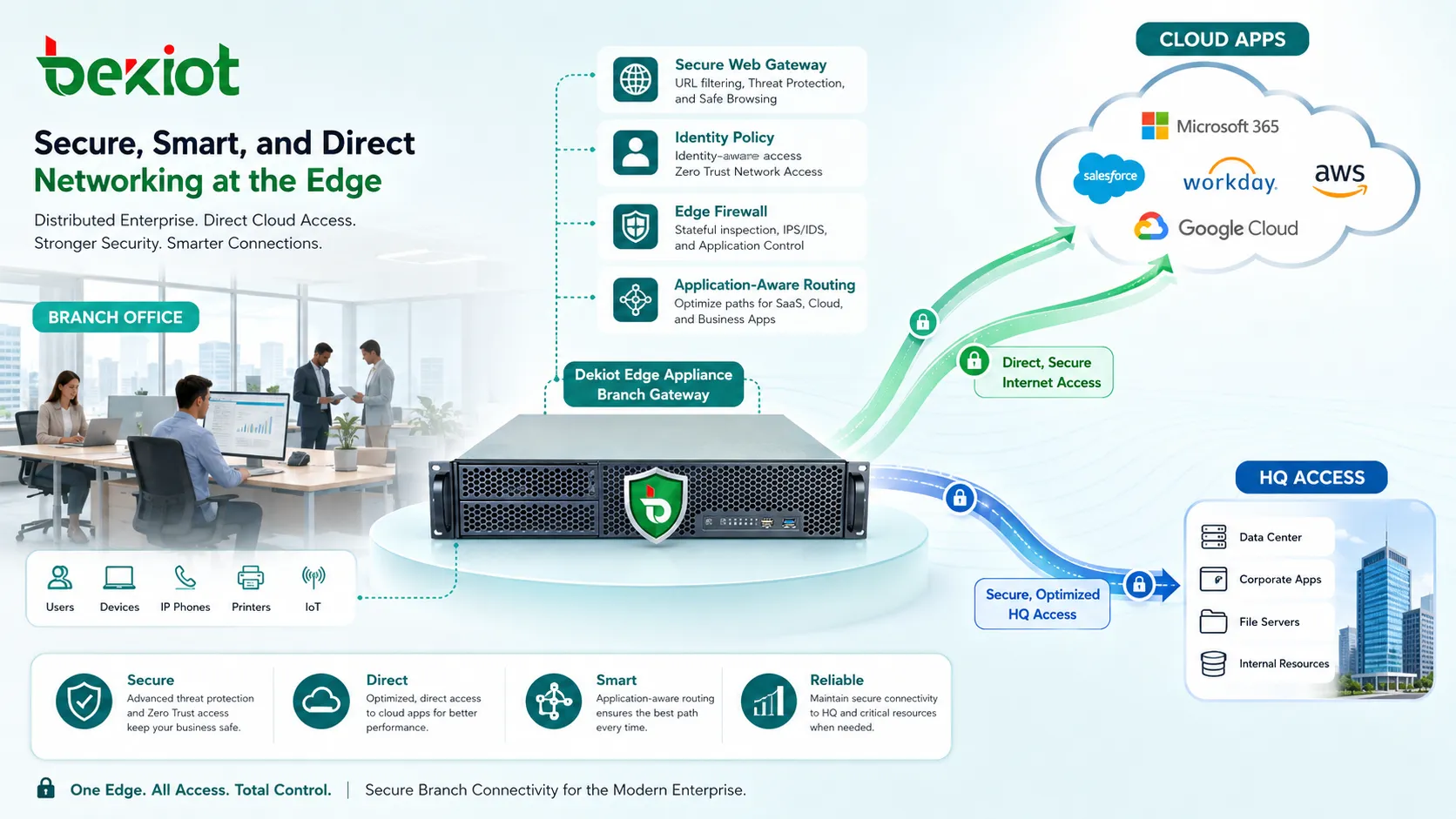
Soutenir les communications unifiées entre sites
La voix, la vidéo, la messagerie, la conférence, l’interphonie, la sonorisation et la dispatch dépendent souvent de la même base réseau. Un mauvais routage, de la gigue, des pertes de paquets ou une mauvaise configuration de pare-feu peuvent vite dégrader la qualité de communication.
Un réseau distribué bien conçu doit classifier les médias temps réel, prioriser les flux sensibles au délai, assurer la traversée NAT si nécessaire et surveiller les indicateurs de qualité voix. Il doit aussi permettre la survivabilité locale des communications critiques si les services centraux sont indisponibles.
Pour les organisations multisites, les communications unifiées doivent être intégrées aux services d’annuaire, plans de numérotation, routage d’urgence, politiques d’enregistrement et règles de sécurité. Cela évite les îlots de communication et améliore la coordination au quotidien comme en incident.
Déployer la vidéo et l’IoT à grande échelle
La vidéosurveillance, les capteurs, le contrôle d’accès, la surveillance environnementale, les compteurs intelligents, les terminaux industriels et l’IoT peuvent générer beaucoup de trafic. Leurs caractéristiques de sécurité diffèrent aussi des appareils utilisateurs ordinaires.
Pour utiliser ces systèmes efficacement, le réseau doit définir où les données sont traitées. Certaines analyses vidéo peuvent se faire en périphérie. Certains enregistrements peuvent rester locaux puis être synchronisés au centre. Certaines données de capteurs peuvent partir vers des plateformes cloud. Tous les flux n’ont pas besoin de traverser le WAN en continu.
Le traitement edge réduit la pression sur la bande passante et améliore le temps de réponse. Les plateformes centrales apportent visibilité et gestion. Le meilleur choix dépend du site, de l’application, de la valeur des données et des exigences de conservation.
Utiliser la sécurité basée sur les politiques
La sécurité traditionnelle se concentrait souvent sur le périmètre des sites. Les environnements distribués modernes exigent un contrôle plus granulaire. Un utilisateur peut accéder depuis une agence, un domicile, un mobile ou un espace cloud. Un appareil peut changer de réseau. Un service peut fonctionner dans plusieurs régions.
Les politiques doivent s’appuyer sur l’identité, l’état de santé de l’appareil, l’emplacement, l’application, la sensibilité des données et le niveau de risque. C’est là que les principes zero trust sont utiles. L’accès doit être accordé selon un contexte vérifié, non parce qu’un site est simplement dans le WAN.
La sécurité basée sur les politiques améliore aussi la cohérence. Au lieu de configurer chaque pare-feu et routeur différemment, les organisations peuvent définir des modèles d’accès standard et les diffuser sur les sites.
Concevoir pour les pannes, pas seulement pour le fonctionnement normal
Un système distribué connaîtra des pannes. Les liens Internet tombent, l’alimentation échoue, les appareils plantent, les services cloud peuvent devenir inaccessibles, la fibre peut être coupée et les changements de configuration peuvent provoquer un routage inattendu. Le vrai test est la continuité ou la reprise rapide des fonctions critiques.
La résilience doit inclure liens redondants, alimentation de secours, équipements doubles, basculement automatique, survivabilité locale, gestion hors bande, sauvegarde de configuration et procédures de reprise après sinistre. Les sites critiques doivent être mieux protégés que les sites à faible risque.
Le basculement doit être testé. Un lien de secours jamais testé peut échouer au pire moment. Les tests doivent couvrir routage, politiques de sécurité, service voix, accès applicatif et alertes de supervision.
Améliorer la visibilité avec supervision et télémétrie
Les grands environnements distribués ne peuvent pas être gérés par simple observation manuelle. Les administrateurs ont besoin de données temps réel et historiques sur l’état des liens, l’usage de bande passante, la latence, les pertes de paquets, la santé des équipements, la performance applicative, les événements de sécurité, l’expérience utilisateur et les changements de configuration.
La supervision doit être en couches. La supervision des équipements indique s’ils sont en ligne. Celle des liens montre la qualité du transport. Celle des applications montre si les utilisateurs accomplissent leurs tâches. Celle de sécurité révèle les comportements suspects. L’analyse des journaux montre ce qui a changé avant l’incident.
Une bonne visibilité réduit le temps de dépannage. Au lieu de se demander si c’est « le réseau », les ingénieurs peuvent voir s’il s’agit du DNS, d’une congestion WAN, d’un blocage pare-feu, d’une panne cloud, d’un problème Wi-Fi ou d’un terminal.

Automatiser les opérations répétitives
L’automatisation réduit les travaux manuels répétés. Les tâches courantes incluent l’enrôlement d’équipements, les modèles de configuration, le déploiement de politiques, les mises à jour firmware, le renouvellement de certificats, la sauvegarde de configuration, la réponse aux alertes et les contrôles de conformité.
La configuration par modèle est particulièrement utile pour les nouvelles agences. Au lieu de reconstruire manuellement routage, VLAN, VPN, règles de pare-feu et supervision, les administrateurs appliquent un profil standard et n’ajustent que les paramètres propres au site.
L’automatisation doit être contrôlée par approbation, suivi de version, tests et retour arrière. Un déploiement rapide n’est utile que si les changements sont fiables.
Standardiser l’adressage et la dénomination
La planification d’adresses devient difficile lorsque de nombreux sites évoluent indépendamment. Des plages IP chevauchées, des noms VLAN flous, des enregistrements DNS incohérents et des sous-réseaux non documentés créent des conflits de routage et des retards de dépannage.
Un plan d’adressage central doit définir codes de site, blocs IP, plages VLAN, adresses loopback, réseaux de gestion, étendues DHCP et plages réservées. Les règles de nommage doivent identifier clairement site, type d’équipement, fonction et rôle.
Un bon nommage et un bon adressage réduisent la confusion. Ils facilitent aussi l’automatisation, la supervision, les politiques de pare-feu et la maintenance documentaire.
Planifier le Wi-Fi et l’accès edge de façon cohérente
De nombreux sites dépendent fortement du Wi-Fi, des terminaux portables, mobiles, lecteurs de codes-barres, tablettes, caméras, capteurs et accès invités. Le design sans fil doit être assez cohérent pour le roaming, la sécurité et la gestion, tout en restant flexible pour le bâtiment local.
Les contrôleurs Wi-Fi centralisés ou points d’accès gérés dans le cloud simplifient les politiques. Cependant, la planification radio exige toujours étude de site, conception des canaux, analyse des interférences et planification de capacité.
L’accès edge doit aussi tenir compte de la sécurité physique. Les ports réseau dans les zones publiques, entrepôts et sites industriels ne doivent pas fournir un accès interne illimité.
Connecter prudemment les technologies opérationnelles
Les systèmes industriels et de bâtiment incluent souvent des technologies opérationnelles comme PLC, terminaux SCADA, capteurs, contrôle d’accès, systèmes d’énergie et équipements de production. Ils peuvent exiger faible latence, fonctionnement stable, segmentation stricte et fenêtres de maintenance contrôlées.
Connecter les réseaux opérationnels aux systèmes d’entreprise peut améliorer la supervision et l’analyse des données, mais introduit aussi des risques cyber. L’accès doit être contrôlé par pare-feu, passerelles, bastions, vérifications d’identité et journalisation.
Les équipes IT et OT doivent s’accorder sur la propriété, les procédures de maintenance, l’accès d’urgence et le contrôle des changements. Un changement sans danger dans le réseau bureautique peut affecter la production s’il est appliqué négligemment.
Utiliser la sortie locale de façon stratégique
La sortie Internet locale permet à une agence d’accéder directement au cloud et à Internet au lieu de renvoyer tout le trafic vers le siège. Cela réduit la latence et améliore l’expérience applicative.
Le risque est que le trafic d’agence contourne les contrôles de sécurité centraux. Pour l’éviter, la sortie locale doit être associée à des passerelles web sécurisées, filtrage DNS, protection des terminaux, services de sécurité cloud et inspection basée sur les politiques.
Tout le trafic ne doit pas sortir localement. Les applications internes sensibles peuvent encore utiliser des chemins privés, tandis que SaaS et trafic web peu risqué peuvent utiliser une sortie locale contrôlée.
Aligner le design réseau sur la continuité d’activité
La continuité d’activité doit définir quels services doivent survivre à différents scénarios de panne. Une agence de détail peut nécessiter le paiement, un hôpital l’accès clinique et la communication d’urgence, une usine la supervision de production, un entrepôt les systèmes de scan et de logistique.
Une fois les fonctions critiques identifiées, le réseau peut fournir le bon niveau de redondance et de survivabilité locale. Cela peut inclure serveurs locaux, authentification en cache, WAN de secours, basculement cellulaire, routage voix local ou procédures d’urgence.
La continuité d’activité doit être testée avec des scénarios réels. Un plan écrit ne suffit pas si les utilisateurs ne savent pas agir pendant une panne réseau.
Gouvernance et contrôle des changements
Les environnements multisites ont besoin d’une gouvernance disciplinée. Un changement rapide de pare-feu sur un site peut affecter l’accès depuis un autre. Une nouvelle connexion cloud peut modifier le routage. Un VPN temporaire peut devenir permanent sans revue.
Le contrôle des changements doit inclure raison de la demande, sites affectés, niveau de risque, plan de retour arrière, méthode de test, fenêtre de maintenance, approbation et mise à jour documentaire. Les changements d’urgence doivent être revus après l’incident.
La gouvernance ne signifie pas tout ralentir. Elle rend les changements sûrs, traçables et répétables.
Optimisation des coûts
Exploiter pleinement une architecture distribuée signifie aussi maîtriser les coûts. Certaines organisations paient trop de bande passante sur des sites peu actifs, tout en sous-investissant dans des liens critiques. D’autres conservent d’anciens circuits privés alors que les usages cloud ont changé.
L’analyse des coûts doit comparer valeur métier, besoin de performance, niveau de risque et exigence de redondance. Un lien coûteux peut être justifié pour un site critique, mais inutile pour un petit bureau utilisant seulement le cloud.
Les données de supervision guident les décisions. Usage réel de bande passante, pertes de paquets, temps de réponse applicatif et événements de basculement fournissent de meilleures preuves que les hypothèses.
Feuille de route de mise en œuvre
Commencez par la découverte. Cartographiez sites, liens, équipements, applications, utilisateurs, zones de sécurité, services cloud et dépendances opérationnelles. Identifiez les systèmes dupliqués, liens faibles, équipements non gérés et flux non documentés.
Définissez ensuite l’architecture cible. Décidez quels sites ont besoin de redondance, quels trafics doivent utiliser des chemins privés, quels services peuvent utiliser la sortie locale, comment fonctionnera la segmentation et comment les politiques seront gérées.
Puis déployez par étapes. Standardisez d’abord noms et adresses, améliorez la supervision, déployez la segmentation de sécurité, optimisez l’accès cloud, introduisez l’automatisation et testez la résilience. Évitez de modifier tous les sites en même temps sans capacité solide de retour arrière.
Erreurs courantes
Une erreur consiste à traiter tous les sites de la même façon. Les sites ont des risques, profils de trafic et importances métier différents. L’architecture doit refléter ces différences.
Une autre erreur est de se concentrer uniquement sur la bande passante. Plus de bande passante ne corrige pas les erreurs de routage, failles de sécurité, mauvais Wi-Fi, DNS défaillant, latence applicative ou manque de visibilité.
Une troisième erreur est de laisser croître les exceptions locales sans contrôle. Routes temporaires, commutateurs non gérés, lignes Internet fantômes et VPN non suivis créent un risque à long terme.
Une quatrième erreur est d’ignorer l’expérience utilisateur. Le réseau peut sembler sain d’après les équipements, alors que les utilisateurs subissent des applications lentes ou une mauvaise qualité voix.
Une cinquième erreur est de retarder la documentation. Dans un environnement distribué, un design non documenté devient un risque de panne future.
Perspectives d’évolution du secteur
Les réseaux distribués évoluent vers le contrôle géré dans le cloud, SD-WAN, SASE, l’accès zero trust, l’edge computing, la supervision assistée par IA et une intégration plus forte entre réseau et sécurité. Les frontières entre WAN, accès cloud, identité et protection contre les menaces deviennent moins séparées.
En même temps, les organisations ajoutent plus d’appareils connectés et de services temps réel. Vidéo, voix, capteurs, télémétrie industrielle et opérations distantes augmentent la pression sur la conception réseau.
La direction la plus réussie ne consiste pas simplement à ajouter plus d’outils. Elle consiste à construire un modèle opérationnel cohérent où connectivité, sécurité, supervision, automatisation et processus métier se soutiennent.
Un réseau multisite est pleinement exploité lorsqu’il devient une base numérique gérée qui relie les emplacements, sécurise l’accès, optimise les applications, soutient la résilience et donne aux administrateurs une visibilité claire sur toute l’organisation.
Questions fréquentes
Pourquoi différentes agences ont-elles une qualité réseau différente ?
Chaque agence peut utiliser des liens d’accès, environnements Wi-Fi, chemins de routage, modèles d’équipement, distances cloud et charges locales différents. La supervision doit comparer les conditions par site au lieu de supposer une cause unique.
Tout le trafic doit-il revenir au siège ?
Pas toujours. Le trafic cloud et SaaS peut mieux fonctionner via une sortie locale contrôlée, tandis que le trafic interne sensible peut nécessiter un routage privé ou une inspection centrale.
Comment protéger les petits sites sans équipement complexe ?
Utilisez des modèles standardisés, pare-feu gérés, passerelles cloud sécurisées, protection des terminaux, filtrage DNS, authentification forte et supervision centralisée. La complexité doit correspondre au risque du site.
Pourquoi la segmentation entre sites est-elle importante ?
La segmentation limite les accès inutiles entre utilisateurs, appareils, serveurs, systèmes IoT et réseaux opérationnels. Elle réduit l’impact d’une compromission et améliore le contrôle des politiques.
Que faut-il vérifier avant d’ajouter une nouvelle agence ?
Examinez les besoins de bande passante, l’accès applicatif, l’adressage IP, les zones de sécurité, le design Wi-Fi, les exigences de redondance, l’accès cloud, l’intégration de la supervision, les règles de nommage et la responsabilité de support.