

Le temps moyen de réparation, couramment abrégé MTTR, est un indicateur de maintenance et de fiabilité qui mesure le temps moyen nécessaire pour remettre en fonctionnement normal un actif, un appareil, une machine, un service logiciel, un composant réseau ou un système de production après une panne. Il se concentre sur le processus de réparation après l’apparition du défaut, ce qui en fait un repère important pour contrôler l’arrêt, améliorer l’efficacité du service, renforcer la résilience opérationnelle et planifier la maintenance.
Dans les usines, centres de données, réseaux télécoms, systèmes de transport, installations électriques, hôpitaux, bâtiments et environnements informatiques, les pannes ne peuvent pas toujours être évitées. L’enjeu est de savoir à quelle vitesse l’organisation détecte le problème, diagnostique la cause, réalise la réparation, teste le résultat et remet le système en service. Le MTTR aide les équipes à mesurer cette capacité de récupération.
Sens de base dans la gestion de la fiabilité
Mean Time to Repair représente la durée moyenne de réparation sur plusieurs événements de panne. Ce n’est pas le temps entre deux pannes, ni la durée totale d’arrêt d’un système sur une longue période. Il répond plutôt à une question pratique : lorsqu’un élément tombe en panne, combien de temps faut-il généralement pour le réparer ?
Cet indicateur est largement utilisé par les ingénieurs de maintenance, responsables de site, équipes de services IT, ingénieurs fiabilité, fabricants d’équipements et responsables d’exploitation. Un MTTR plus faible signifie souvent une restauration plus rapide, une meilleure réponse de maintenance, une préparation plus solide des pièces de rechange, des procédures plus claires et un dépannage plus efficace.
Ce que le MTTR mesure réellement
Le MTTR inclut généralement le temps actif de réparation nécessaire pour remettre un actif en état de marche. Selon la définition retenue par l’organisation, il peut inclure la confirmation du défaut, le diagnostic, le remplacement de pièces, la récupération de configuration, les tests fonctionnels et la restauration finale du service.
Par exemple, si une machine de production s’arrête à cause d’un capteur défectueux, le temps de réparation peut comprendre l’envoi du technicien, l’inspection du capteur, le remplacement, l’étalonnage et la vérification du redémarrage. Si un serveur tombe en panne, il peut inclure l’analyse d’incident, le remplacement de composant, la récupération de données, le redémarrage et la validation du service.
Pourquoi la définition doit être claire
Les organisations ne calculent pas toujours le MTTR de la même manière. Certaines comptent à partir du signalement du défaut, d’autres à partir du début effectif des travaux. Certaines incluent l’attente de pièces détachées, tandis que d’autres ne comptent que le temps technique de réparation sur site ou à distance.
C’est pourquoi le MTTR doit être clairement défini avant toute comparaison de performance. Sans définition cohérente, l’indicateur peut induire en erreur. Une équipe peut sembler lente parce que son calcul inclut les temps d’attente, d’approbation ou de déplacement, alors qu’une autre ne mesure que l’activité de réparation.
Fonctionnement du calcul
La formule standard du MTTR est simple. Il faut additionner le temps de réparation de tous les événements sur une période définie, puis diviser ce total par le nombre d’événements de réparation. Le résultat indique le temps moyen nécessaire pour restaurer l’actif ou le système défaillant.
Par exemple, si cinq réparations prennent 2 heures, 3 heures, 1 heure, 4 heures et 5 heures, le temps total de réparation est de 15 heures. En divisant 15 heures par cinq événements, on obtient un MTTR de 3 heures. Chaque réparation dure donc en moyenne 3 heures.
Collecte du temps de réparation
Un MTTR fiable dépend de relevés de réparation fiables. Les équipes doivent noter quand la panne est détectée, quand la réparation commence, quelles actions sont effectuées, quand le service est rétabli et si la réparation est vérifiée. Les systèmes de gestion de maintenance, plateformes de tickets, journaux SCADA, centres de services et CMMS peuvent tous aider à collecter ces données.
Les relevés manuels peuvent aussi convenir, mais ils doivent rester cohérents. Si les techniciens oublient de clôturer les ordres de travail, saisissent des durées incomplètes ou classent les incidents différemment, la valeur finale du MTTR risque de ne pas refléter la performance réelle.
Exemple simple de réparation d’équipement
Imaginons qu’une unité de ventilation tombe en panne trois fois en un mois. La première réparation dure 90 minutes, la deuxième 120 minutes et la troisième 60 minutes. Le temps total de réparation est donc de 270 minutes.
Avec la formule MTTR, 270 minutes divisées par 3 événements donnent 90 minutes. Le MTTR de cette unité de ventilation est donc de 90 minutes. Les responsables de site peuvent utiliser ce chiffre pour évaluer l’efficacité de réponse, la charge des techniciens, la disponibilité des pièces et le besoin de maintenance préventive.
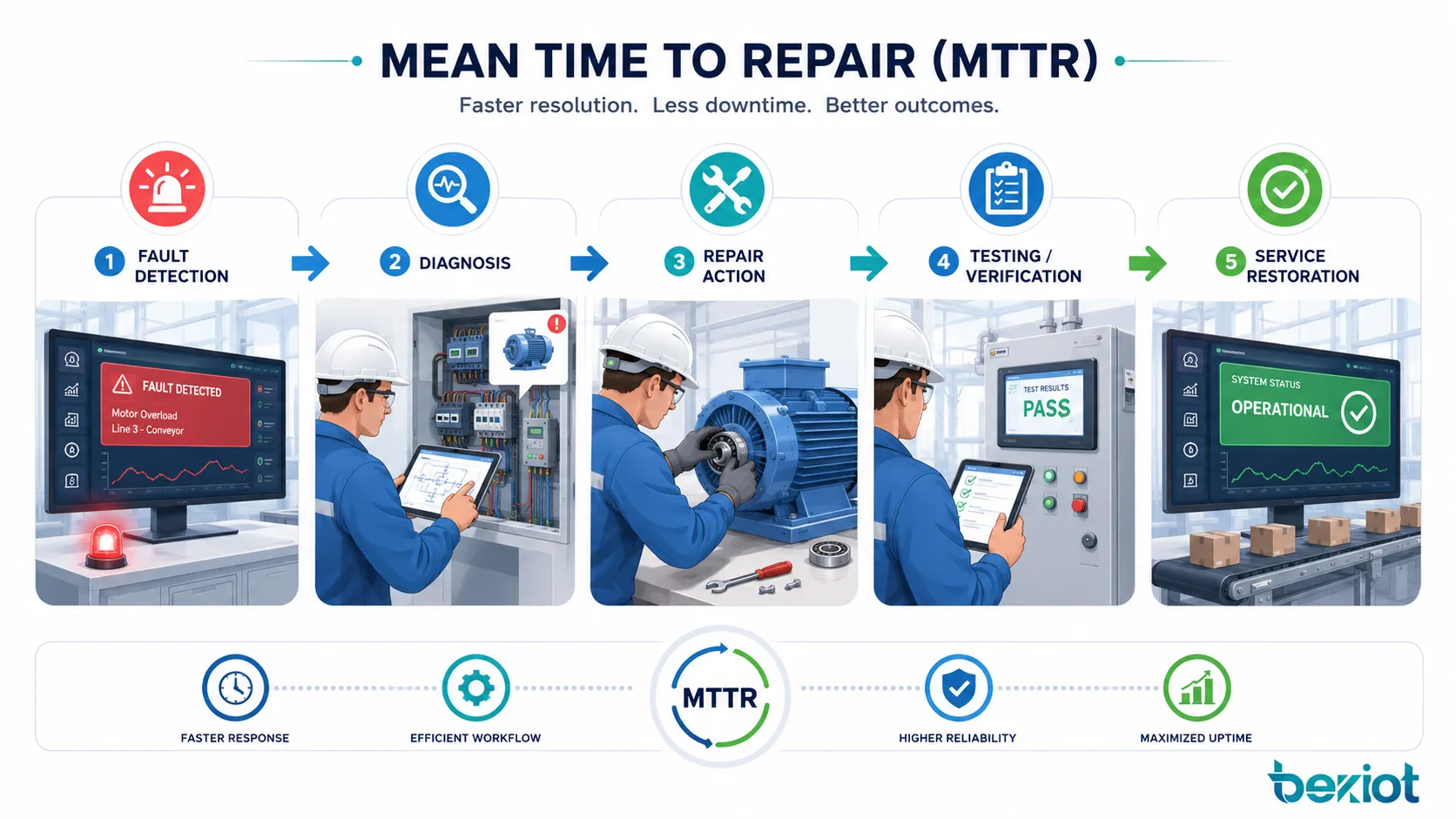
Ce qui se passe pendant un cycle de réparation
Le MTTR n’est pas seulement une moyenne mathématique. Il reflète tout le flux de réparation derrière chaque panne. Une longue durée peut venir d’une détection lente, d’étapes de diagnostic peu claires, de pièces indisponibles, d’une documentation insuffisante, d’un accès difficile aux équipements ou d’un manque de personnel formé.
Comprendre le cycle de réparation aide les équipes à corriger les causes réelles des arrêts au lieu de se limiter au chiffre final.
Détection et signalement des pannes
Le cycle commence lorsque la panne est détectée. Dans certains systèmes, la détection est automatique grâce aux alarmes, capteurs, tableaux de supervision, autodiagnostics ou codes défaut. Dans d’autres cas, un opérateur, un utilisateur ou un technicien remarque le problème et le signale manuellement.
Une détection rapide réduit l’impact global d’une panne. Si un défaut machine est découvert immédiatement, la réparation peut commencer avant que le problème n’affecte la qualité, la sécurité ou les équipements en aval. En informatique et en réseau, les alertes automatiques peuvent réduire fortement le temps de réponse aux incidents.
Diagnostic et identification de la cause racine
Après la détection, les techniciens ou ingénieurs doivent identifier la cause. Le diagnostic peut inclure inspection visuelle, analyse des journaux, tests électriques, vérifications mécaniques, revue logicielle, traçage réseau ou comparaison avec les historiques de panne.
Le diagnostic est souvent l’un des facteurs les plus importants pour le MTTR. Une équipe disposant d’une bonne documentation, de codes défaut clairs, d’une supervision distante et de techniciens expérimentés identifie les problèmes plus vite qu’une équipe qui dépend uniquement d’essais successifs.
Réparation, remplacement et vérification
La réparation peut comprendre remplacement de composants, redémarrage logiciel, correction de configuration, réparation de câbles, réglage mécanique, récupération de firmware, nettoyage, lubrification, recalibrage ou remplacement complet de l’équipement.
Une fois la réparation terminée, le système doit être testé avant son retour en service normal. La vérification peut inclure essais de démarrage, contrôles de sécurité, essais de production, tests de connectivité réseau, confirmation de réinitialisation d’alarme ou validation utilisateur. Sans vérification, le système peut sembler réparé puis retomber rapidement en panne.
Pourquoi cet indicateur est important
Le MTTR est important parce que l’arrêt a des conséquences réelles. Il peut stopper la production, retarder la livraison de services, réduire la satisfaction client, augmenter les coûts, créer des risques de sécurité et perturber la continuité d’activité. En suivant le temps de réparation, les organisations identifient les faiblesses de maintenance et améliorent la récupération.
Le MTTR est le plus utile lorsqu’il déclenche des actions. Le but n’est pas seulement de calculer une moyenne, mais de comprendre pourquoi les réparations prennent ce temps et comment améliorer le processus.
Réduire l’impact des arrêts
Un MTTR plus faible signifie que les équipements ou systèmes reviennent plus vite en fonctionnement après une panne. En fabrication, cela peut réduire les pertes de production. En télécoms et IT, cela réduit les interruptions de service. Dans les bâtiments et infrastructures, cela améliore confort, sécurité et disponibilité.
La réduction des arrêts est essentielle pour les systèmes critiques. Plateformes de communication d’urgence, distribution électrique, systèmes médicaux, contrôle du trafic, sécurité et lignes de production industrielles exigent souvent une restauration rapide, car toute interruption peut avoir de graves conséquences opérationnelles.
Améliorer l’efficacité de la maintenance
Le MTTR permet aux équipes de maintenance d’évaluer leur efficacité de réponse. Si la durée moyenne augmente, les responsables peuvent rechercher si la cause vient des retards de pièces, d’une formation insuffisante, d’un accès difficile, d’une escalade lente ou d’instructions peu claires.
En comparant le MTTR par type d’équipement, site, équipe, poste ou prestataire, l’organisation repère les améliorations prioritaires. Cela peut soutenir une meilleure dotation, une formation ciblée, une documentation plus complète et une planification plus intelligente des pièces.
Soutenir les objectifs de fiabilité et de disponibilité
La disponibilité dépend à la fois de la fréquence des pannes et de la vitesse de récupération. Même si un équipement tombe parfois en panne, une réparation rapide peut maintenir une disponibilité acceptable. Le MTTR est donc souvent utilisé avec le MTBF, le pourcentage de disponibilité, les objectifs de niveau de service et les cibles de fiabilité.
Par exemple, un système avec des pannes fréquentes et des réparations longues aura une faible disponibilité. Un système avec des pannes rares et des réparations rapides présentera en général une meilleure continuité opérationnelle.
Avantages pour les équipes d’exploitation et de maintenance
Le MTTR a une valeur pratique car il relie la performance technique de maintenance aux résultats métier. Il aide à passer de la réparation réactive à l’amélioration structurée. Au lieu de parler de l’arrêt de manière générale, les responsables peuvent décider à partir de données de réparation.
Meilleure planification des pièces de rechange
Si les réparations prennent trop de temps parce que les pièces ne sont pas disponibles, les données MTTR mettent le problème en évidence. Les équipes peuvent identifier les composants critiques, définir des stocks minimums, améliorer les accords fournisseurs ou utiliser des modules de remplacement pour restaurer plus vite.
Pour les actifs de grande valeur ou liés à la sécurité, le coût du stock de pièces peut être bien inférieur au coût d’un arrêt prolongé. L’analyse MTTR aide à justifier cette décision par des preuves mesurables.
Gestion plus claire des niveaux de service
Dans la maintenance externalisée, le support IT, les services télécoms et l’exploitation de bâtiments, le MTTR peut soutenir les SLA. Il donne au fournisseur et au client un indicateur mesurable de la performance de réparation.
Les objectifs doivent toutefois rester réalistes. La réparation d’un simple lecteur de contrôle d’accès n’est pas comparable à celle d’une ligne de production complexe, d’un grand système HVAC ou d’une panne réseau multisite. Complexité, localisation, risque et conditions d’accès doivent être pris en compte.
Formation et documentation plus efficaces
Un MTTR élevé peut montrer que les techniciens ont besoin d’une meilleure formation ou d’instructions plus claires. Si le même type de panne prend trop de temps à résoudre à plusieurs reprises, l’organisation peut créer guides de dépannage, modes opératoires visuels, listes de diagnostic ou procédures d’assistance à distance.
Une bonne documentation réduit la dépendance à l’expérience individuelle. Elle aide aussi les nouveaux techniciens à intervenir avec plus de confiance et limite les erreurs répétées.
Applications courantes dans les secteurs
Mean Time to Repair est utilisé dans de nombreux secteurs car presque toute organisation dépend d’actifs, systèmes, appareils ou services susceptibles de tomber en panne. Le processus de réparation varie, mais le besoin de mesurer et d’améliorer le temps de restauration est universel.
Fabrication et équipements industriels
Dans les usines, le MTTR mesure les performances de réparation des lignes de production, moteurs, pompes, convoyeurs, robots, machines CNC, équipements d’emballage, capteurs, armoires de contrôle et systèmes utilitaires.
Réduire le MTTR en environnement industriel améliore la continuité de production, réduit les heures supplémentaires, augmente l’utilisation des actifs et soutient les programmes de maintenance lean. Il aide aussi à identifier les machines qui génèrent le plus d’efforts de réparation.
Systèmes IT et centres de données
Dans les opérations IT, le MTTR s’applique aux serveurs, systèmes de stockage, applications, bases de données, services cloud, pare-feu, commutateurs, routeurs et plateformes utilisateur. Il est courant dans la gestion d’incidents et l’ingénierie de fiabilité de site.
Pour les services numériques, réparer peut consister à restaurer une fonction logicielle plutôt qu’à remplacer un composant physique. Le processus peut inclure revue de journaux, rollback, patch, basculement, correction de configuration, redémarrage ou restauration depuis sauvegarde.
Télécommunications et infrastructure réseau
Les opérateurs télécoms et équipes réseau utilisent le MTTR pour évaluer la vitesse de récupération des stations de base, liens fibre, équipements de transmission, réseaux IP, passerelles de communication, routeurs, commutateurs et plateformes de service.
Les pannes réseau peuvent affecter de nombreux utilisateurs à la fois. Une réparation rapide et une localisation précise sont essentielles pour maintenir la qualité de service. Supervision distante, liens redondants, chemins d’escalade clairs et coordination terrain contribuent à réduire le MTTR.
Installations, bâtiments et utilités
Les gestionnaires de site utilisent le MTTR pour les systèmes HVAC, ascenseurs, pompes, contrôle d’éclairage, contrôle d’accès, interfaces incendie, équipements de sécurité, distribution électrique, systèmes d’eau et automatisation du bâtiment.
Dans les bâtiments et utilités, le MTTR est lié au confort des occupants, à la sécurité, à la conformité réglementaire et à la continuité du service. Des réparations longues peuvent affecter locataires, visiteurs, zones de production ou usagers d’infrastructures publiques.
Comparaison du MTTR avec les indicateurs liés
Le MTTR est souvent discuté avec d’autres indicateurs de fiabilité et de maintenance. Comprendre les différences aide à choisir le bon indicateur pour le bon objectif. Le MTTR se concentre sur la vitesse de réparation, tandis que d’autres mesures portent sur la fréquence de panne, la disponibilité ou le délai de réponse.
| Indicateur | Signification | Objectif principal |
|---|---|---|
| MTTR | Temps moyen de réparation | Mesure le temps moyen nécessaire pour restaurer un actif ou système en panne |
| MTBF | Temps moyen entre pannes | Mesure le temps moyen de fonctionnement entre deux pannes |
| MTTF | Temps moyen avant panne | Estime la durée de vie attendue avant panne pour les éléments non réparables |
| MTTA | Temps moyen d’acquittement | Mesure le temps nécessaire pour remarquer et reconnaître un incident |
| Availability | Taux de disponibilité opérationnelle | Indique à quelle fréquence un système est disponible |
MTTR et MTBF
Le MTBF mesure la fréquence des pannes, tandis que le MTTR mesure la rapidité de réparation. Les deux sont importants. Un système peut avoir un MTBF élevé et provoquer tout de même de graves perturbations si chaque réparation dure longtemps.
Par exemple, une machine qui ne tombe en panne que deux fois par an peut rester problématique si chaque réparation dure trois jours. À l’inverse, un appareil moins critique peut tomber en panne plus souvent mais être réparé en quelques minutes. MTBF et MTTR doivent être étudiés ensemble pour une vision complète de la fiabilité.
MTTR et disponibilité
La disponibilité est fortement influencée par le MTTR. Si le temps de réparation diminue, la disponibilité peut augmenter à taux de panne constant. Réduire le MTTR est donc une stratégie courante pour les systèmes qui ne peuvent pas être immédiatement reconçus pour tomber moins souvent en panne.
En pratique, les équipes améliorent la disponibilité en évitant les pannes, réparant plus vite, ajoutant de la redondance, améliorant la surveillance ou concevant des systèmes capables de fonctionner en mode dégradé pendant la réparation.
Comment réduire le temps de réparation
Réduire le MTTR ne consiste pas seulement à demander aux techniciens d’aller plus vite. L’amélioration durable vient d’une meilleure conception, de meilleures informations, d’une meilleure préparation et d’une coordination plus efficace. Le but est de retirer les retards du processus de réparation.
Utiliser la surveillance et la détection précoce
La surveillance automatique peut détecter des conditions anormales avant qu’elles ne deviennent des pannes majeures. Capteurs, journaux, alarmes, tableaux de bord, systèmes de suivi d’état et outils de maintenance prédictive aident à réagir plus tôt et diagnostiquer plus vite.
La détection précoce est très utile lorsque l’équipement présente des signes tels que vibration, hausse de température, changement de pression, fluctuation de tension, codes d’erreur ou instabilité de communication. Agir sur ces signaux réduit à la fois le temps de réparation et l’impact de la panne.
Standardiser les procédures de dépannage
La vitesse de réparation augmente lorsque les techniciens suivent des procédures claires. Listes de contrôle, arbres de panne, manuels, schémas de câblage, listes de pièces, étapes de récupération logicielle et règles d’escalade réduisent l’incertitude.
Les procédures standard rendent aussi la performance plus cohérente entre techniciens et équipes. Elles assurent que le même problème est traité de manière fiable à chaque fois.
Améliorer l’accès aux pièces et aux outils
De nombreuses réparations sont retardées non parce que le défaut est difficile, mais parce que la pièce, l’outil, le mot de passe, l’image logicielle, le câble ou l’instrument de test manque. Des kits de réparation et des pièces critiques en stock peuvent réduire fortement la durée de restauration.
Pour les sites distribués, des pièces locales, centres régionaux ou stratégies de remplacement modulaire évitent les longs trajets et retards d’expédition. Dans les systèmes numériques, des sauvegardes prêtes à l’emploi et modèles de configuration jouent un rôle similaire.
Limites et mauvais usages du MTTR
Même utile, le MTTR ne doit pas être le seul indicateur de performance de maintenance. Un MTTR faible ne signifie pas toujours que le système est fiable. Il peut simplement montrer que l’équipe sait réparer des pannes répétées. Si le même actif échoue sans cesse, la cause racine doit encore être traitée.
Le MTTR peut aussi masquer les variations. Une moyenne peut sembler acceptable alors que quelques incidents critiques durent beaucoup plus longtemps que prévu. Pour les systèmes importants, il faut examiner la distribution des temps, les pires incidents, les pannes répétées et les équipements à risque séparément.
Ne pas ignorer la prévention des pannes
La rapidité de réparation compte, mais prévenir les pannes évitables est souvent préférable. Maintenance préventive, surveillance d’état, amélioration de conception, installation correcte, formation opérateur et protection de l’environnement réduisent la fréquence des pannes.
Une stratégie solide équilibre réparation rapide et amélioration de fiabilité à long terme. Le MTTR indique la vitesse de récupération, mais n’explique pas pourquoi les pannes apparaissent sans analyse de cause racine.
Ne pas comparer sans contexte
Comparer le MTTR entre systèmes différents peut être trompeur. Remplacer un capteur simple n’est pas comparable à réparer une turbine, une panne réseau, un ascenseur ou une base de données. Chaque actif a sa complexité, son niveau de risque, ses conditions d’accès et ses exigences de réparation.
Les comparaisons pertinentes se font dans des groupes d’équipements similaires, des conditions proches ou sur le même actif dans le temps. Elles révèlent les vraies améliorations sans produire de jugements injustes.
Bonnes pratiques d’utilisation
Pour utiliser le MTTR efficacement, l’organisation doit définir clairement l’indicateur, collecter des données fiables, analyser les causes des réparations longues et relier les résultats à des actions d’amélioration. L’indicateur doit soutenir de meilleures décisions, pas seulement remplir un rapport.
Définir les points de début et de fin
Chaque organisation doit décider quand le temps de réparation commence et se termine. Il peut commencer au signalement, à l’ouverture du ticket, à l’arrivée du technicien ou au début de la réparation active. Il peut se terminer au redémarrage, à la fin des tests ou à la confirmation du service par l’utilisateur.
La définition choisie doit correspondre au but de mesure. Pour améliorer le service client, le temps total d’arrêt peut être plus pertinent. Pour évaluer l’efficacité technique, le temps actif de réparation peut être plus approprié.
Segmenter les données
Au lieu de calculer un MTTR global pour tous les actifs, les équipes doivent segmenter par type d’équipement, site, catégorie de panne, gravité, équipe, poste, fournisseur ou fonction système. La mesure devient alors plus utile et exploitable.
Par exemple, un site peut découvrir que les pompes se réparent vite, mais que les ascenseurs sont lents à cause de pièces externalisées. Une équipe IT peut voir que les incidents applicatifs se résolvent vite, tandis que les incidents réseau demandent plus de diagnostic. La segmentation indique où commencer.
Relier le MTTR à l’analyse de cause racine
Lorsque les temps de réparation sont élevés, les équipes doivent rechercher la raison. Le défaut était-il difficile à diagnostiquer ? La documentation manquait-elle ? La pièce était-elle indisponible ? L’approbation a-t-elle tardé ? L’accès distant était-il impossible ? L’équipement était-il difficile d’accès ?
L’analyse de cause racine transforme le MTTR d’une mesure passive en outil d’amélioration actif. Avec le temps, elle réduit l’arrêt, améliore la fiabilité et rend la planification de maintenance plus prévisible.
FAQ
Que signifie Mean Time to Repair ?
Mean Time to Repair est le temps moyen nécessaire pour rétablir un actif, système, appareil ou service en panne en fonctionnement normal. Il se calcule en divisant le temps total de réparation par le nombre d’événements sur une période définie.
Le MTTR est-il identique au temps d’arrêt ?
Pas toujours. Le MTTR se concentre généralement sur la durée de réparation, alors que l’arrêt peut inclure détection, signalement, attente, retard de pièces, approbation et redémarrage. L’organisation doit définir ce qui est inclus.
Quelle est une bonne valeur de MTTR ?
Une bonne valeur dépend de l’équipement, du secteur, des exigences de service et de la gravité. Quelques minutes peuvent être attendues pour redémarrer un service numérique, tandis que plusieurs heures peuvent être raisonnables pour un équipement industriel complexe. Le meilleur repère est souvent la comparaison avec des actifs similaires ou les performances passées.
Comment une entreprise peut-elle réduire le MTTR ?
Elle peut améliorer la surveillance, accélérer la détection, standardiser le dépannage, former les techniciens, garder les pièces critiques disponibles, utiliser le diagnostic distant, améliorer la documentation et simplifier l’accès aux équipements.
Pourquoi le MTTR est-il important pour la fiabilité ?
Le MTTR est important car la vitesse de réparation influence directement l’arrêt et la disponibilité. Même les systèmes fiables peuvent tomber en panne ; une récupération rapide réduit l’impact opérationnel, l’interruption de service, les pertes de production et l’insatisfaction client.
Quelle est la différence entre MTTR et MTBF ?
Le MTTR mesure la durée de réparation après panne. Le MTBF mesure le temps moyen entre deux pannes. Le MTTR porte sur la vitesse de récupération, tandis que le MTBF porte sur la fréquence de panne. Les deux aident à comprendre fiabilité et disponibilité globales.







