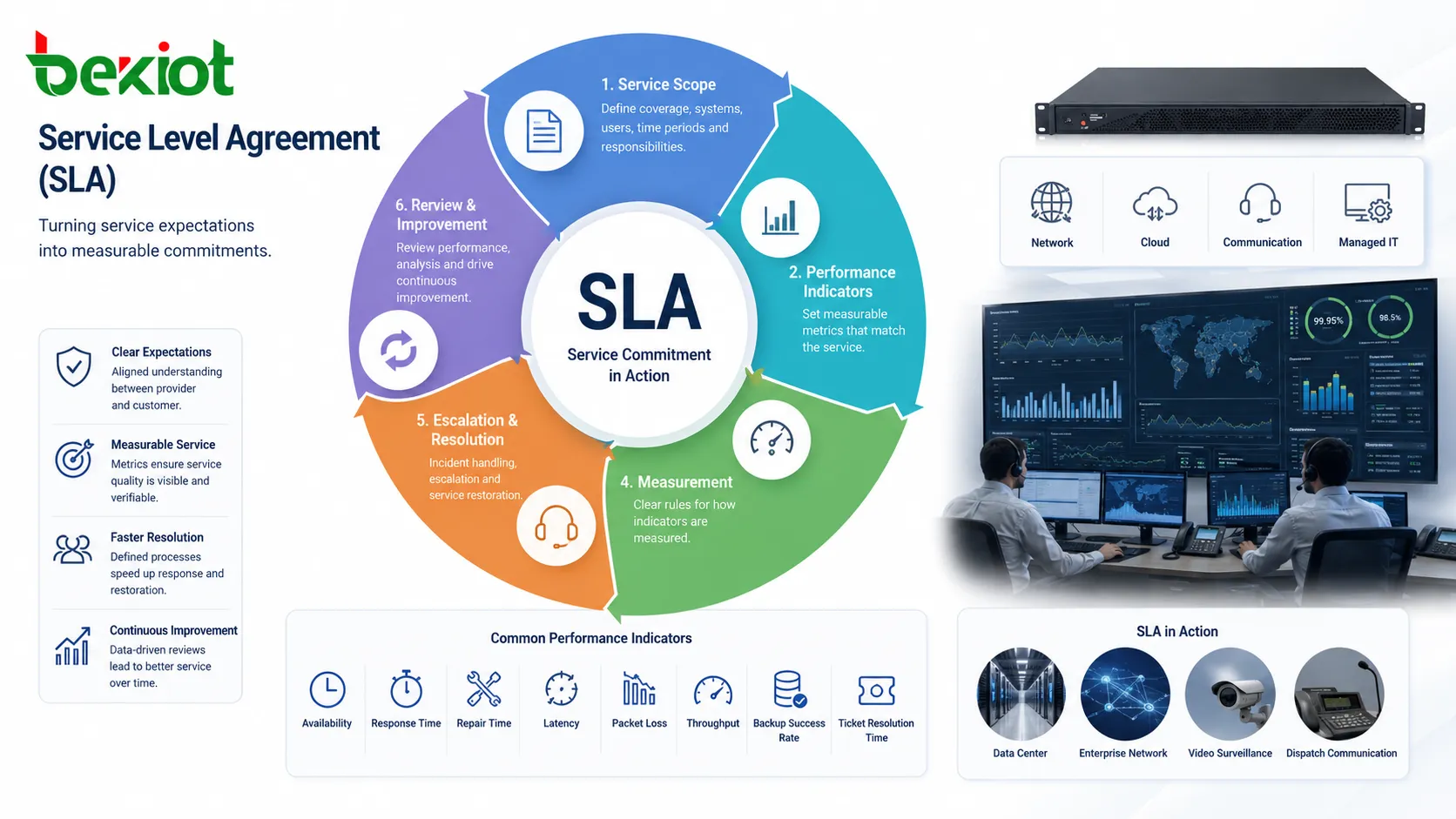
Un SLA devient utile lorsque les attentes de service doivent passer d’une promesse orale à une exploitation mesurable.
Le client attend disponibilité, reprise rapide, réponse claire, fenêtres de maintenance prévisibles et rapports transparents. Le fournisseur a besoin de limites de responsabilité, d’objectifs mesurables, de règles d’escalade et d’une évaluation fondée sur les preuves. Le SLA relie ces besoins.
La logique opérationnelle des engagements mesurables
Un accord de niveau de service, ou SLA, définit formellement le niveau de service attendu entre fournisseur et client. Il s’applique aux réseaux, clouds, centres de données, systèmes de communication, services IT managés, logiciels, maintenance et sécurité.
Le fonctionnement commence par le périmètre : services couverts, systèmes ou sites inclus, utilisateurs pris en charge, périodes applicables et responsabilités de chaque partie. Sans périmètre, l’évaluation devient ambiguë.
Le SLA définit ensuite les indicateurs : disponibilité, temps de réponse, temps de réparation, restauration, traitement des incidents, sauvegardes, résolution des tickets, latence, pertes de paquets, débit ou couverture du support. Ils doivent correspondre au service.
Il précise aussi les méthodes de mesure. La disponibilité peut être calculée par mois ou par an, depuis le bord fournisseur ou le point client, avec ou sans maintenance planifiée. Des règles claires évitent les interprétations.
En pratique, le SLA est un cadre permanent de gestion de service. Il fixe les attentes, guide la surveillance, soutient l’escalade en cas d’incident et fournit des preuves pour la revue après événement.
Du texte contractuel à l’exécution quotidienne
Un SLA est un document, mais sa valeur apparaît dans l’exécution quotidienne. Il doit orienter la surveillance, les tickets, la réponse des équipes, les mises à jour client et les revues de performance.
La mise en œuvre commence souvent par la surveillance. Pour un réseau, on suit disponibilité, latence, gigue, pertes, interfaces et santé des équipements. Pour le cloud ou le logiciel, on suit disponibilité applicative, transactions, API, ressources et erreurs.
La gestion des incidents est essentielle. Le SLA indique le délai d’accusé de réception, la classification, l’escalade et l’objectif de restauration. Un incident critique exige une réaction et des mises à jour rapides.
Le SLA influence les effectifs et l’organisation du support. Une promesse 24/7 exige personnel, outils et procédures. Un délai de réparation strict suppose pièces de rechange, accès distant et service terrain prêts.
La communication client fait partie de l’exécution. Pendant une panne, le client doit savoir si le problème est reçu, quel impact est prévu, quelles actions sont en cours et quand viendra la prochaine mise à jour.
Les indicateurs qui donnent du sens à l’accord
La qualité du SLA dépend des indicateurs. Des phrases vagues comme haute fiabilité ou support rapide ne suffisent pas. Les indicateurs mesurables permettent de juger le service de façon cohérente.
La disponibilité est un indicateur majeur. Elle exprime le temps pendant lequel le service est utilisable sur une période donnée. Le calcul doit préciser les exclusions comme maintenance, panne côté client, force majeure ou tiers.
Le temps de réponse mesure la vitesse à laquelle le fournisseur reconnaît ou commence à traiter un incident. Il ne doit pas être confondu avec le temps de réparation, car ces étapes sont différentes.
Le temps de résolution ou de restauration mesure le retour à un fonctionnement normal ou acceptable. Il est crucial pour les systèmes critiques et varie souvent selon la gravité.
D’autres indicateurs peuvent couvrir latence, gigue, pertes, débit, taux de réussite, sauvegarde, point de récupération, disponibilité du support, traitement sécurité ou maintenance préventive. Ils doivent refléter la dépendance réelle du client.
Comment les niveaux de gravité guident la réponse
Les SLA utilisent souvent des niveaux de gravité. Ils évitent de traiter de la même manière une panne totale, une dégradation, une demande mineure, une question ou un changement planifié.
Un incident grave peut interrompre le service, affecter la sécurité, causer une perte métier ou supprimer une fonction critique. Il exige reconnaissance immédiate, escalade rapide, experts et objectif strict.
La gravité doit dépendre de l’impact, non de l’émotion. Le client peut juger tout urgent et le fournisseur rester prudent. Des définitions claires limitent les litiges.
La gravité détermine aussi l’escalade. Si l’incident n’est pas résolu dans le délai prévu, il passe à un niveau supérieur, à la direction ou à un rapport renforcé.
Dans une exploitation mature, les données de gravité sont revues. Trop d’incidents graves indiquent un problème de conception ou de stabilité. Des reclassements fréquents montrent des définitions faibles.
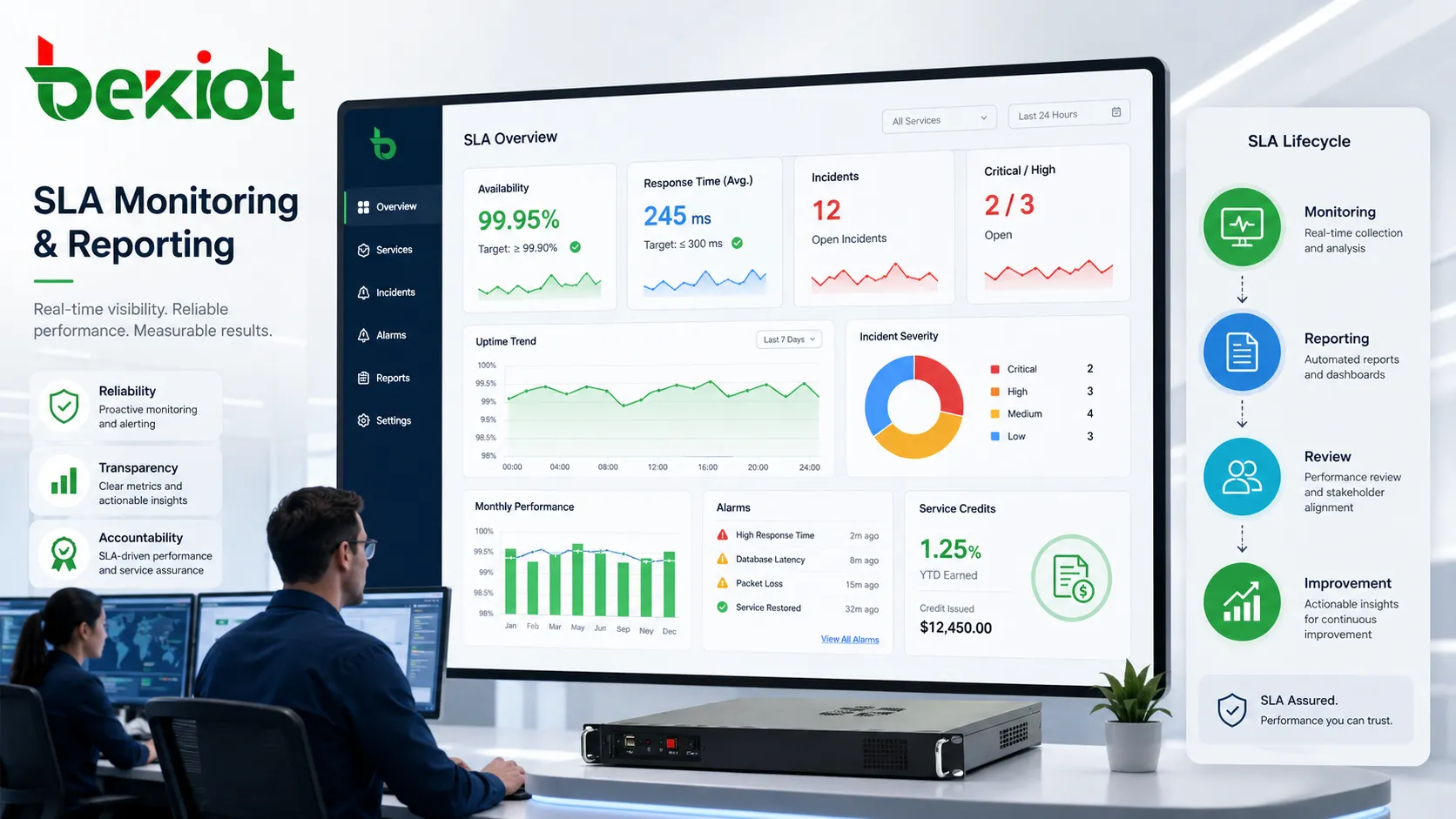
La surveillance et le reporting comme couche de preuve
Sans preuve, un SLA est difficile à appliquer. La surveillance et les rapports montrent si les objectifs sont atteints, où la qualité change, quels incidents se produisent et si des problèmes reviennent.
La surveillance peut être automatique ou manuelle. Les outils suivent disponibilité, trafic, équipements, serveurs, transactions, alarmes, temps de réponse et erreurs. Les registres manuels ajoutent visites, retours client et rapports d’incident.
La fréquence de reporting dépend du service. Les services critiques peuvent demander des tableaux de bord temps réel ou des notifications immédiates. Les services standards utilisent souvent des rapports mensuels.
L’exactitude des données est essentielle. Mesurer seulement dans le centre de données du fournisseur peut cacher un problème d’accès client. Le SLA doit définir le point et la méthode de collecte.
Un bon reporting crée de la transparence et réduit les litiges. Il révèle aussi les tendances : pannes répétées, réponses lentes ou modules faibles, afin de cibler les actions correctives.
Escalade, remèdes et crédits de service
Le SLA doit indiquer ce qui se passe en cas d’échec. Escalade, remèdes et crédits de service créent une responsabilité et incitent les deux parties à traiter les problèmes sérieusement.
L’escalade décrit le passage d’un dossier non résolu dans la structure support : premier niveau, spécialistes, constructeur, centre d’exploitation ou direction. Elle exige seuils, contacts, propriétaires et règles de mise à jour.
Les remèdes décrivent les conséquences d’un manquement : crédits, plan correctif, extension de maintenance, revue de direction ou droit de résiliation après échecs répétés.
Les crédits de service doivent rester réalistes. Ils compensent parfois financièrement, mais ne couvrent pas tout l’impact métier. Pour les systèmes critiques, restauration et prévention comptent davantage.
Les exclusions doivent être définies : configuration client, changements non autorisés, alimentation hors contrôle, maintenance planifiée, force majeure ou dépendances tierces. Cela réduit les disputes.
Avantages pour les clients et les fournisseurs
Pour le client, l’avantage principal est la prévisibilité. Il sait le niveau attendu, les délais, les services couverts et les preuves utilisées. Cela soutient planification, risque et responsabilité.
Le SLA aide aussi à comparer les fournisseurs. Deux offres semblables peuvent différer fortement par disponibilité, réponse, escalade, reporting ou fenêtres de maintenance.
Pour le fournisseur, le SLA définit les limites : inclusions, exclusions, classification des incidents et obligations du client. Il réduit les attentes irréalistes et permet de planifier le support.
Il améliore également la gestion interne. Le support priorise selon la gravité, l’exploitation repère les problèmes récurrents, les équipes commerciales expliquent la valeur et la finance évalue les risques.
Pour les deux parties, la valeur majeure est l’alignement. Les attentes du client et le processus du fournisseur se rejoignent autour de métriques et procédures communes.
Valeur opérationnelle au-delà de la protection contractuelle
Certaines organisations voient le SLA comme un document juridique, mais sa valeur opérationnelle est souvent supérieure. Il encourage surveillance, documentation, escalade, analyse de cause, capacité et amélioration.
Si le SLA impose des réponses strictes, le fournisseur doit surveiller les canaux de support. S’il fixe la disponibilité, il doit maintenir redondance, sauvegarde et détection d’incident.
Les clients utilisent les rapports pour comprendre les dépendances, justifier des mises à niveau, planifier la maintenance et évaluer le risque avant qu’un incident majeur survienne.
Dans les environnements complexes, les SLA coordonnent plusieurs fournisseurs : cloud, réseau, sécurité et maintenance sur site. Ils montrent où se rencontrent les responsabilités.
Bien utilisé, le SLA devient un élément de gouvernance du service. Il transforme la gestion réactive des plaintes en contrôle structuré de la performance.
Erreurs courantes dans la conception d’un SLA
Une erreur courante consiste à afficher de beaux chiffres sans règles de mesure. Une disponibilité élevée est faible si trop d’exclusions ou un mauvais point de mesure masquent l’expérience client.
Une autre erreur consiste à choisir trop de métriques. Une longue liste paraît complète, mais complique la gestion. Les meilleures métriques sont liées directement à l’impact métier.
Des définitions de gravité vagues provoquent aussi des litiges. L’accord doit décrire les niveaux d’impact et, si possible, donner des exemples pour classer rapidement.
Certains SLA échouent car les responsabilités ne sont pas équilibrées. Le fournisseur peut avoir besoin d’accès, de rapports exacts, de fenêtres approuvées, de contacts et de conditions côté client.
Enfin, un SLA doit être revu lorsque le service change. Besoins, utilisateurs, architecture, sécurité et dépendances évoluent; une revue régulière maintient l’accord pertinent.
Comment juger si un SLA est efficace
Un SLA efficace est clair, mesurable, pertinent, réaliste et applicable. Les deux parties doivent comprendre périmètre, objectifs, mesures, gravité, reporting et remèdes.
La mesurabilité signifie que la performance peut être vérifiée par des données fiables. Le SLA indique les sources, les calculs et le traitement des litiges.
La pertinence signifie mesurer ce qui compte vraiment pour l’exploitation du client. Une métrique technique n’a de valeur que si elle se relie à l’expérience ou à l’impact métier.
Le réalisme signifie que les objectifs correspondent à l’architecture, au budget, aux équipes, au risque et à l’environnement. Un bon SLA équilibre ambition et faisabilité.
L’applicabilité signifie qu’un échec entraîne une action définie : escalade, action corrective, crédit, revue de direction ou plan d’amélioration.

FAQ
Un SLA est-il réservé aux services externalisés ?
Non. Les SLA sont utiles pour les services externalisés, mais aussi entre équipes internes, services partagés, IT, facilities ou départements métier.
Quelle est la différence entre SLA et KPI ?
Un SLA est un accord de engagements de service. Un KPI est un indicateur de performance. Les objectifs SLA utilisent souvent des KPI, mais tous les KPI ne sont pas contractuels.
Un SLA peut-il garantir qu’aucune panne ne se produira ?
Non. Un SLA n’élimine pas les pannes. Il définit performance attendue, réponse, mesure et remèdes, tandis que la conception réduit le risque.
Qui doit examiner les rapports SLA ?
Les équipes opérationnelles et la direction doivent les examiner. Les techniciens ont besoin des détails; les managers ont besoin des tendances et de la visibilité des risques.
À quelle fréquence un SLA doit-il être mis à jour ?
Il doit être revu quand le périmètre, l’architecture, les utilisateurs, les dépendances métier, la conformité ou les responsabilités changent, et aussi périodiquement.