Une mise à niveau du système ne doit jamais commencer par le paquet d’installation lui-même.Elle doit commencer par une question opérationnelle simple : qu’est-ce qui doit rester stable pendant le changement ? Une nouvelle version peut apporter des correctifs de sécurité, de meilleures performances, de nouvelles fonctions ou une durée de support plus longue, mais elle peut aussi introduire des incompatibilités, des changements de configuration, une interruption de service et une pression de reprise.
Une bonne gestion de mise à niveau ne consiste donc pas seulement à cliquer sur « mettre à jour » au bon moment. Elle consiste à contrôler le changement de manière à protéger les services, les utilisateurs, les données et la continuité d’activité.
Partir de la raison du changement
La première règle consiste à confirmer pourquoi la mise à niveau est nécessaire. Certaines sont urgentes parce qu’elles corrigent des failles de sécurité, des bogues graves, des exigences de conformité ou des risques de fin de support. D’autres sont planifiées pour améliorer les performances, ajouter des fonctions, prendre en charge du nouveau matériel ou préparer l’architecture future. Certaines restent optionnelles et doivent attendre que l’organisation dispose d’un temps de test suffisant.
Sans raison claire, la décision devient facilement réactive. Une équipe peut mettre à niveau simplement parce qu’une nouvelle version existe, parce que le fournisseur la recommande ou parce qu’un autre service l’a déjà fait. Cela crée un risque inutile. Un système stable ne doit pas être modifié sans bénéfice suffisamment clair pour justifier la perturbation possible.
L’objectif doit être formulé en termes pratiques, par exemple « corriger une faille d’authentification », « prendre en charge une nouvelle version de base de données », « augmenter la capacité de traitement des appels », « remplacer un système d’exploitation non supporté » ou « activer l’intégration avec une nouvelle plateforme ». Un objectif clair aide ensuite à définir le périmètre de test et les critères d’acceptation.
Lorsque la raison est claire, l’équipe projet peut aussi évaluer l’urgence. Une mise à niveau de sécurité critique peut nécessiter un cycle d’approbation court. Une évolution fonctionnelle peut être planifiée dans une fenêtre de maintenance à faible risque. Une transformation d’architecture peut nécessiter un déploiement par étapes. Les raisons différentes appellent des niveaux de contrôle différents.
Évaluer l’impact métier avant l’action technique
Toute mise à niveau affecte davantage que le système technique. Elle peut toucher les utilisateurs, les plages de service, les applications connectées, les rapports, les droits d’accès, les terminaux, l’expérience client, le flux de production ou les équipes de support. Avant toute action technique, l’équipe doit identifier les processus métier qui dépendent du système.
C’est particulièrement important pour les systèmes fonctionnant en continu, comme les plateformes de communication, les bases de données, les systèmes industriels, les portails clients, les paiements, les plateformes de supervision et les outils d’exploitation internes. Même une courte interruption peut provoquer appels manqués, transactions échouées, retards de production, enregistrements incomplets ou plaintes d’utilisateurs.
L’analyse d’impact doit couvrir les périodes de pointe, les groupes d’utilisateurs critiques, les clients externes, les services internes, les engagements de niveau de service et les exigences légales ou réglementaires. Si le système prend en charge l’urgence, le contrôle de production, la surveillance de sécurité ou un service public, le plan doit être plus strict que pour un outil bureautique ordinaire.
Le résultat de cette analyse doit guider la planification. Certaines mises à niveau peuvent se faire pendant la maintenance normale. D’autres exigent des nuits ou des week-ends. Certaines nécessitent des systèmes de secours temporaires, des notifications utilisateurs ou une bascule progressive. Une opération techniquement simple peut rester risquée si le moment est mal choisi.
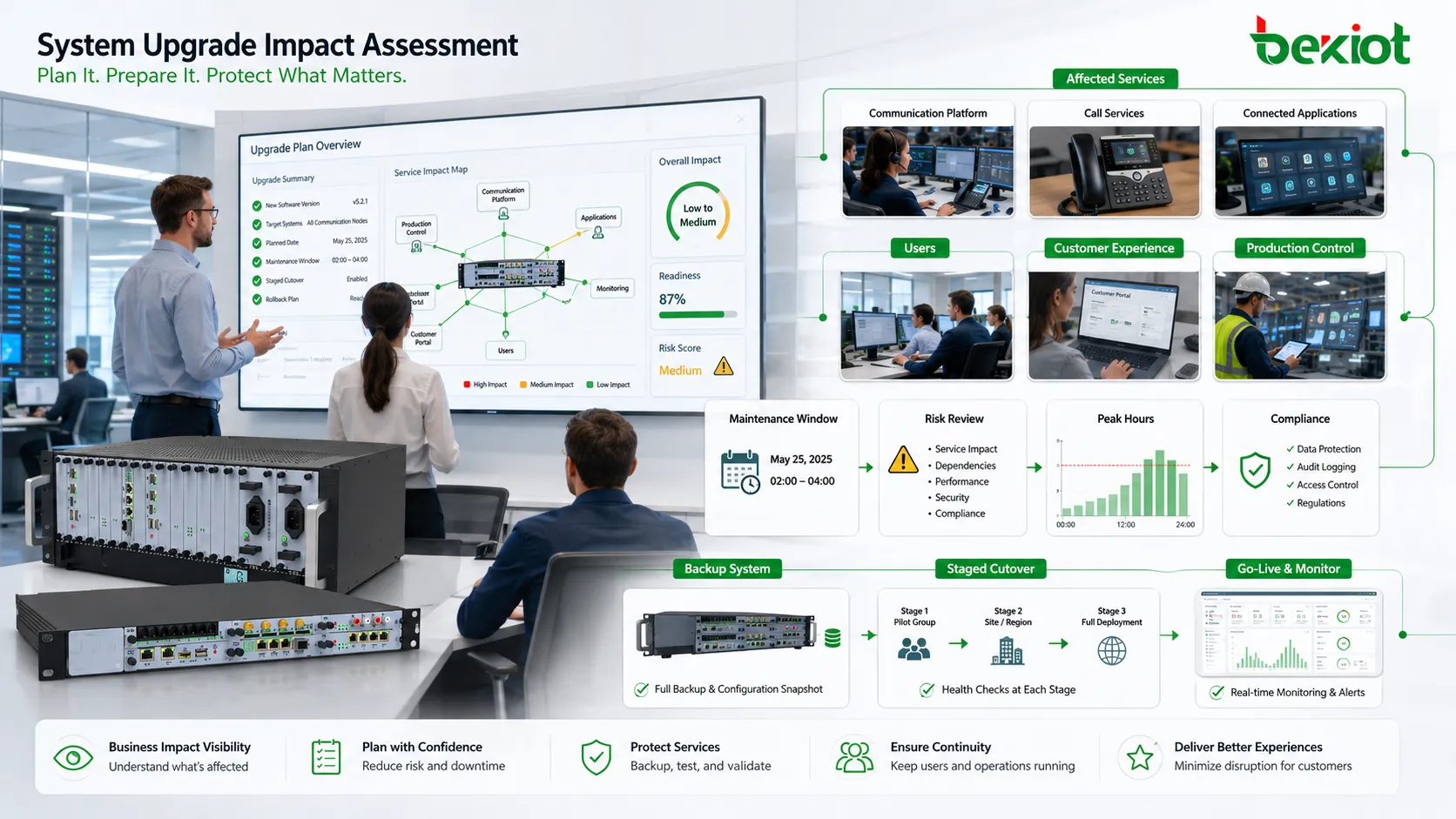
Établir d’abord un inventaire exact
Un système ne peut pas être mis à niveau en sécurité si l’équipe ignore ce qui y est connecté. L’inventaire doit inclure serveurs, systèmes d’exploitation, bases de données, middleware, applications, terminaux, équipements réseau, stockage, licences, certificats, API, intégrations tierces, outils de sauvegarde, systèmes de supervision et méthodes d’accès des utilisateurs.
Cet inventaire révèle les dépendances cachées. Un outil de reporting peut dépendre d’une version de base de données. Un client ancien peut ne pas accepter un nouveau protocole. Un équipement peut échouer après un changement de firmware. Un système de sécurité peut utiliser une API obsolète. Découvrir ces dépendances après déploiement augmente la pression de retour arrière.
L’inventaire de configuration est tout aussi important. Paramètres système, règles de routage, droits utilisateurs, clés d’intégration, tâches planifiées, comptes de service, règles de pare-feu, certificats et scripts personnalisés doivent être enregistrés avant la mise à niveau. Beaucoup d’échecs viennent de détails de configuration manquants ou écrasés, pas de la nouvelle version elle-même.
Dans les grands environnements, l’inventaire doit aussi repérer les différences de version entre sites ou nœuds. Une agence peut avoir un niveau de correctif différent. Un serveur peut contenir un module spécifique. Un modèle d’équipement peut nécessiter un firmware particulier. Ces écarts influencent l’ordre de mise à niveau et la conception des tests.
Confirmer la compatibilité au lieu de la supposer
La compatibilité est l’un des risques les plus fréquents. Une nouvelle version peut exiger une base de données plus récente, une bibliothèque d’exécution différente, un navigateur mis à jour, un pilote modifié, une API révisée ou une méthode d’authentification changée. Si les systèmes connectés ne sont pas compatibles, l’installation peut réussir tout en échouant opérationnellement.
Les contrôles doivent couvrir matériel, système d’exploitation, base de données, version applicative, protocole, interface, navigateur, client mobile, terminal, pilote, plug-in, certificat et service tiers. L’équipe ne doit pas se fier uniquement aux notes de version générales ; les conditions du projet doivent être comparées aux exigences fournisseur et à la configuration locale.
La compatibilité descendante compte également. Si d’anciens clients, équipements ou intégrations doivent continuer à fonctionner, il faut les tester directement. Certains systèmes acceptent une exploitation mixte de versions pendant une durée limitée, tandis que d’autres exigent une mise à niveau simultanée de tous les composants. Une erreur d’appréciation peut provoquer une panne partielle de service.
Lorsque la compatibilité est incertaine, un environnement pilote doit être utilisé. L’équipe peut y tester des équipements représentatifs, des rôles utilisateurs, des flux de données et des appels d’interface avant de toucher à la production. Cela réduit les conflits majeurs découverts pendant la fenêtre de maintenance.
| Zone de mise à niveau | Règle clé | Raison de l’examen |
|---|---|---|
| Version applicative | Vérifier les notes de version et les changements de dépendances | Évite les pertes de fonction et conflits d’interface |
| Base de données | Valider schéma, pilote et exigences de migration | Protège l’accès aux données et la stabilité transactionnelle |
| Système d’exploitation | Confirmer le support runtime, services et politiques de sécurité | Évite les problèmes de démarrage et de permissions |
| Réseau et sécurité | Revoir pare-feu, certificats, DNS et règles d’accès | Évite les échecs de connexion après bascule |
| Terminaux et clients | Tester des appareils et versions représentatifs | Réduit les plaintes de compatibilité sur le terrain |
Protéger les données avant de changer l’environnement
La protection des données est une règle non négociable. Avant la mise à niveau, l’équipe doit confirmer disponibilité, intégrité, méthode de restauration, emplacement de stockage, politique de rétention et durée de reprise. Une sauvegarde jamais testée n’est qu’une hypothèse, pas un plan de récupération.
Pour les bases de données et plateformes applicatives, la sauvegarde doit être prise au bon moment. Si les données continuent de changer pendant l’opération, l’équipe doit décider d’arrêter les écritures, d’utiliser les journaux de transaction, de prendre un instantané ou de préparer une reprise par réplication. Le choix dépend de l’architecture et de l’indisponibilité acceptable.
La sauvegarde de configuration ne doit pas être négligée. Paramètres applicatifs, fichiers de service, tables de routage, tâches planifiées, rôles utilisateurs, certificats, clés et modèles personnalisés peuvent être aussi importants que les données métier. Après un échec, les reconstruire manuellement peut prendre plus de temps que restaurer le logiciel.
Les scripts de migration doivent aussi être examinés avec soin. Certaines mises à niveau changent schéma, index, encodage, longueur de champ ou structure de données. Ces changements peuvent être difficiles à inverser. L’équipe doit savoir si la migration est réversible, si le retour arrière exige une restauration complète et combien de temps la reprise peut prendre.
Utiliser un environnement de test proche des conditions réelles
Les tests ne valent que si l’environnement ressemble à la production sur les points importants. Un petit système de test vide peut confirmer que l’installateur fonctionne, mais il ne révèle pas forcément les problèmes de performance, migration, intégration, permissions ou compatibilité des équipements.
L’environnement de test doit inclure des données représentatives, des rôles utilisateurs, des services connectés, des paramètres, des appels d’interface et des charges typiques. Il n’a pas toujours besoin d’être une copie parfaite de la production, mais il doit contenir assez de réalité pour exposer les principaux risques.
Les cas de test doivent suivre les flux réels. Selon le système, les utilisateurs doivent se connecter, créer des enregistrements, lancer des rapports, effectuer des transactions, déclencher des alarmes, appeler des API, générer des fichiers, accéder aux clients mobiles ou utiliser des équipements connectés. Un démarrage technique réussi ne signifie pas que le service est prêt.
Des tests de performance peuvent aussi être nécessaires. Une nouvelle version peut fonctionner avec un utilisateur mais ralentir sous charge réelle. Migration de base, cache, mémoire, CPU, I/O disque, latence réseau et tâches de fond doivent être observés si besoin. L’évaluation doit porter sur le comportement opérationnel, pas seulement sur la fin de l’installation.

Préparer le retour arrière avant le déploiement
Une mise à niveau ne doit pas avancer sans plan de retour arrière. Le retour arrière consiste à revenir à l’état fonctionnel précédent si l’opération échoue ou provoque des problèmes inacceptables. Dire « nous restaurerons la sauvegarde si nécessaire » ne suffit pas ; l’équipe doit savoir exactement comment agir.
Le plan doit préciser qui décide, quelles conditions déclenchent le retour arrière, quels fichiers ou bases doivent être restaurés, combien de temps prendra la reprise, quelles données peuvent être perdues et comment les utilisateurs seront informés. Il doit aussi dire si le retour est possible après migration ou si seule une réparation en avant est réaliste.
Certaines mises à niveau sont faciles à inverser. D’autres modifient structure de base, méthodes de chiffrement, firmware ou formats de configuration de manière difficile à annuler. Ces cas exigent plus de prudence et peuvent nécessiter déploiement par étapes, architecture blue-green, nœuds de secours ou exploitation parallèle.
Le retour arrière doit être testé lorsque c’est possible. Un plan jamais répété peut échouer en urgence. Même un exercice partiel peut révéler des permissions manquantes, une restauration trop lente, des sauvegardes incomplètes ou des responsabilités floues.
Maîtriser la fenêtre de maintenance
La fenêtre de maintenance est la période prévue pour exécuter la mise à niveau. Elle doit être choisie selon l’impact utilisateur, la charge système, la disponibilité des équipes, le support fournisseur, la fin des sauvegardes et la durée de retour arrière. Une erreur fréquente consiste à prévoir assez de temps pour installer, mais pas pour dépanner ou revenir en arrière.
La fenêtre doit inclure préparation, sauvegarde finale, exécution, vérification, correction éventuelle, temps de décision, retour arrière et communication aux utilisateurs. Si l’installation prend une heure mais le retour arrière trois heures, la fenêtre doit refléter cette réalité.
Un gel des changements peut être nécessaire avant l’opération. Les autres équipes doivent éviter les modifications non liées de configuration, réseau, base de données ou règles d’accès pendant la même période. Quand plusieurs changements se superposent, le diagnostic devient beaucoup plus difficile.
La disponibilité du support compte aussi. Techniciens clés, responsables applicatifs, ingénieurs réseau, administrateurs de base de données, équipes sécurité et support fournisseur doivent être joignables. La mise à niveau ne doit pas être planifiée lorsque la seule personne connaissant une dépendance critique est absente.
Communiquer avec les utilisateurs avant et après
La communication évite la confusion. Avant la mise à niveau, les utilisateurs affectés doivent connaître l’heure prévue, l’impact sur le service, les limites temporaires, le canal de contact et ce qu’ils doivent éviter pendant la fenêtre. Pour les systèmes publics, une communication client peut aussi être nécessaire.
Le message doit être précis sans être saturé de détails techniques. Les utilisateurs doivent savoir si le système sera indisponible, si la saisie doit être arrêtée, si un client mobile doit être mis à jour, si les mots de passe ou méthodes de connexion changent et quand le service doit reprendre.
Après l’opération, les utilisateurs doivent recevoir une confirmation de disponibilité. Si des fonctions ont changé, de courtes notes de version ou consignes peuvent être nécessaires. Si des problèmes subsistent, l’équipe doit expliquer les limites connues et les étapes prévues de résolution.
Une bonne communication réduit les tickets inutiles. Beaucoup de plaintes après mise à niveau viennent non d’une panne technique, mais de surprises liées à l’interface, aux invites de connexion, aux sessions expirées ou aux variations temporaires de performance.
Valider le résultat par des contrôles d’acceptation
Une mise à niveau n’est pas terminée quand l’installateur se ferme. Elle l’est seulement quand le système a passé les contrôles d’acceptation. Ces contrôles doivent être définis avant le début afin que l’équipe sache ce que signifie « réussi ».
Les contrôles peuvent inclure démarrage des services, connexion, exécution des flux clés, lecture et écriture de données, génération de rapports, appels d’interface, connexion d’équipements, tâches planifiées, vérification des droits, opération de sauvegarde, état de supervision et confirmation utilisateur. La liste exacte dépend de la fonction du système.
Les fonctions critiques doivent être testées en premier. Si le système gère des transactions, testez les transactions. S’il gère la communication, testez les chemins d’appel ou flux de messages. S’il supervise, testez réception d’alarme et tableaux de bord. S’il fournit une base de données, testez accès applicatif et requêtes. Ne dépensez pas les premiers tests sur des fonctions mineures tant que les services critiques restent non validés.
L’acceptation doit aussi inclure la revue des journaux. Erreurs, avertissements, travaux échoués, erreurs d’authentification, messages de migration et échecs d’intégration peuvent révéler des problèmes avant les utilisateurs. Un écran propre ne signifie pas toujours une mise à niveau propre.

Surveiller le système après la mise en service
Les premières heures et journées après une mise à niveau sont importantes. Certains problèmes n’apparaissent qu’avec le trafic réel, les tâches planifiées, les pics d’usage ou certains comportements utilisateurs. La surveillance post-mise à niveau doit être plus active que l’exploitation normale, surtout pour les systèmes critiques.
Elle doit couvrir CPU, mémoire, disque, performance de base de données, trafic réseau, état des services, journaux d’erreur, sessions utilisateurs, taux de succès des transactions, réponse API, longueur des files et croissance du stockage lorsque c’est pertinent. L’équipe doit aussi suivre les retours utilisateurs, car certains problèmes sont visibles pour eux avant les tableaux de bord.
Les références de performance sont utiles. Si l’équipe connaît le temps de réponse, l’utilisation de ressources et le taux d’erreur avant la mise à niveau, elle peut comparer la nouvelle version objectivement. Sans référence, il est difficile de savoir si une lenteur est nouvelle ou historique.
La surveillance doit avoir une durée définie. Pour un petit système, quelques heures peuvent suffire. Pour un service critique, elle peut durer plusieurs jours ou couvrir un cycle métier complet. La mise à niveau ne doit pas être clôturée avant que le système prouve sa stabilité en conditions normales.
Documenter ce qui a changé
La documentation fait partie de la mise à niveau, ce n’est pas une tâche administrative optionnelle. L’équipe doit noter la version installée, les configurations modifiées, les sauvegardes effectuées, les incidents apparus, leur résolution, les approbateurs et les travaux restants.
Les enregistrements de version sont essentiels. Le dépannage futur dépend de la connaissance exacte des versions système, base de données, firmware, pilote ou correctif en cours. Sans documentation, les équipes suivantes perdront du temps à redécouvrir l’environnement.
Les problèmes connus doivent être écrits. Si une fonction nécessite un ajustement ultérieur, si une intégration attend la confirmation d’un fournisseur ou si un groupe d’utilisateurs doit être formé, ces points ne doivent pas rester dans des messages informels. Ils doivent faire partie du dossier de mise à niveau.
Une bonne documentation améliore aussi la prochaine mise à niveau. L’équipe peut revoir ce qui a bien fonctionné, ce qui a pris plus de temps que prévu, les risques oubliés et les étapes à améliorer. Chaque mise à niveau doit mieux préparer l’organisation à la suivante.
Conclusion
La règle la plus importante d’une mise à niveau est le changement contrôlé. Une opération réussie protège les données, vérifie la compatibilité, limite l’indisponibilité, prépare le retour arrière, communique avec les utilisateurs et confirme le comportement du service après mise en production. Le paquet de mise à niveau n’est qu’une partie du processus.
Dans les environnements critiques, l’approche la plus sûre consiste à traiter la mise à niveau comme un flux opérationnel complet : évaluer l’impact, tester de façon réaliste, planifier avec prudence, exécuter avec des responsabilités claires, valider les résultats et surveiller après la mise en service. Ainsi, les mises à niveau améliorent les systèmes au lieu de créer des interruptions évitables.
FAQ
Faut-il mettre à niveau chaque système dès qu’une nouvelle version sort ?
Non. Les correctifs de sécurité urgents peuvent exiger une action rapide, mais les évolutions fonctionnelles ou les versions majeures doivent d’abord être évaluées. Compatibilité, impact métier, préparation des tests et options de retour arrière doivent être examinés avant le déploiement.
Quelle est la préparation la plus importante avant une mise à niveau ?
La préparation la plus importante est de confirmer la capacité de récupération. Cela comprend des sauvegardes testées, des enregistrements de configuration, des procédures de retour arrière et des règles de décision claires. Sans confiance dans la récupération, même une mise à niveau simple peut devenir risquée.
Pourquoi les mises à niveau échouent-elles même après les tests ?
Les tests peuvent manquer des conditions réelles de production : trafic élevé, données inhabituelles, clients anciens, intégrations tierces, tâches planifiées, différences de permissions ou restrictions réseau. L’environnement de test doit refléter les dépendances de production les plus importantes.
Combien de temps faut-il surveiller après la mise à niveau ?
Cela dépend de l’importance du système et de son cycle d’usage. Un petit outil interne peut nécessiter une surveillance courte, tandis qu’un service critique peut devoir être suivi pendant les pics, les tâches planifiées et un cycle métier complet.
Que doit contenir le dossier de mise à niveau ?
Il doit inclure anciennes et nouvelles versions, heure de mise à niveau, responsables, détails de sauvegarde, configurations modifiées, résultats de test, incidents trouvés, état du retour arrière, notification utilisateurs et actions de suivi.