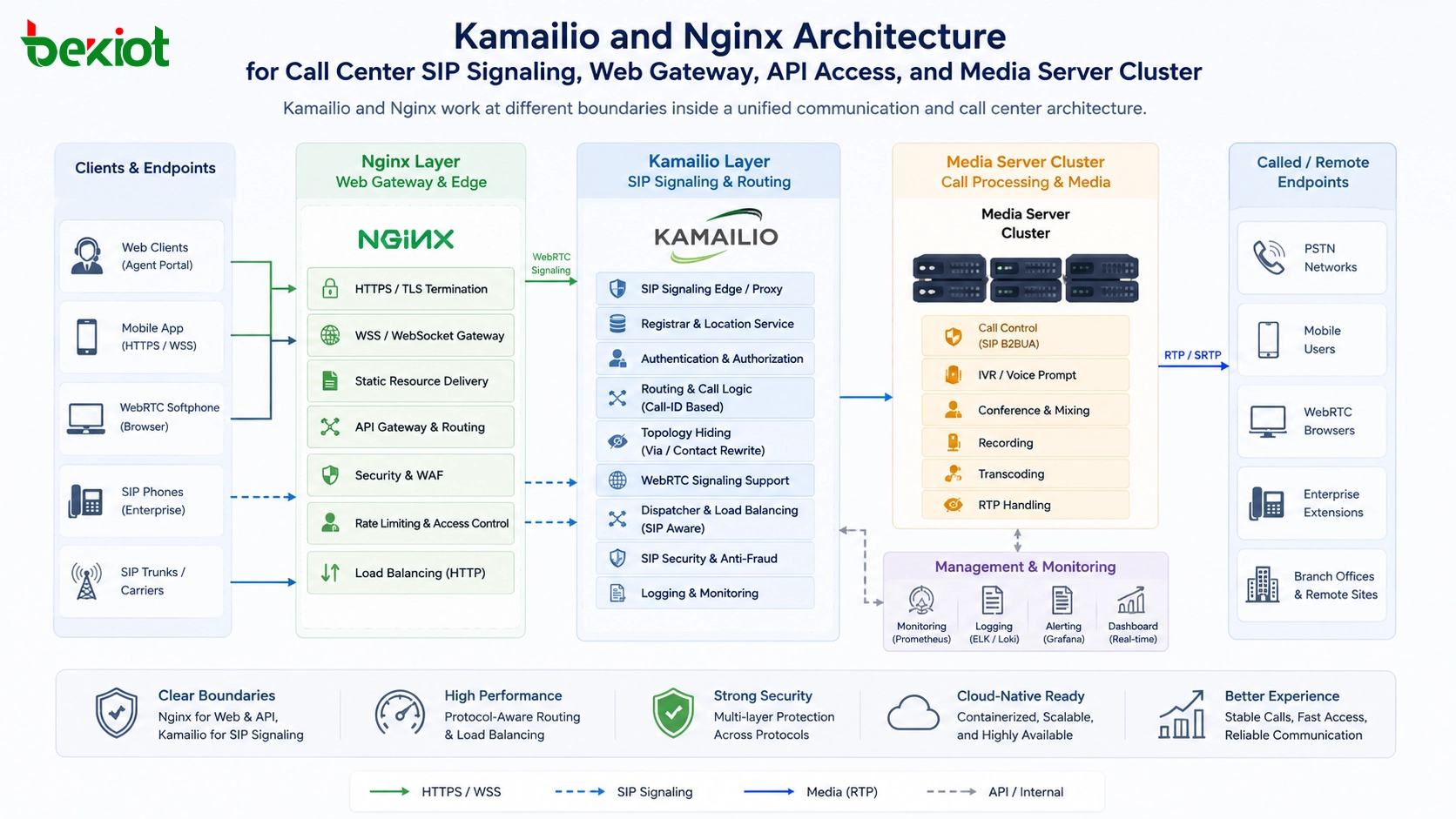
Le déploiement automatisé consiste à utiliser des outils, des scripts, des plateformes et des flux de travail prédéfinis pour publier des logiciels, des configurations, des appareils, des services ou des mises à jour système avec un minimum d’intervention manuelle. Au lieu de demander aux ingénieurs de répéter à la main chaque étape d’installation, de configuration, de test et de mise en production, il transforme ces étapes en un processus répétable et cohérent entre les environnements.
Ce que signifie le déploiement automatisé
Le déploiement automatisé est souvent associé à la livraison logicielle, mais son champ est plus large. Il peut s’appliquer aux services cloud, sites web, applications mobiles, applications d’entreprise, équipements réseau, terminaux IoT, systèmes VoIP, configurations de serveurs, politiques de sécurité, mises à jour de firmware et changements d’infrastructure.
L’idée centrale est simple : lorsqu’un processus de déploiement doit être répété de nombreuses fois, il doit être défini, testé et automatisé. Cela réduit les erreurs humaines, accélère les publications, améliore la traçabilité et facilite le retour arrière en cas de problème.
Dans un processus manuel, chaque environnement peut être configuré légèrement différemment. Un ingénieur peut oublier un paramètre, un autre utiliser un paquet obsolète, et un autre appliquer les changements dans le mauvais ordre. Le déploiement automatisé réduit ces incohérences en suivant toujours le même flux.
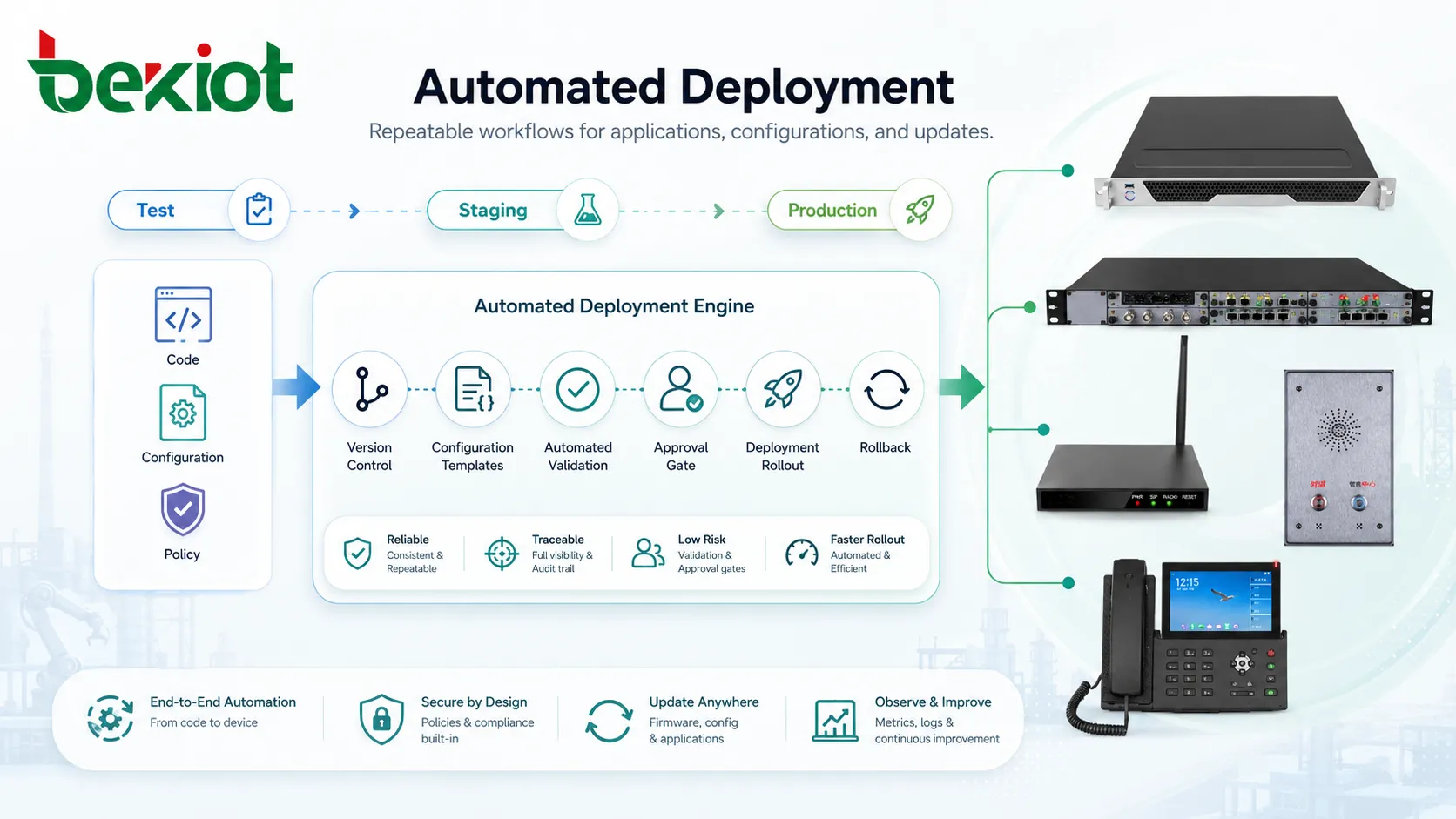
Fonctionnement du déploiement automatisé
Préparation de la source
Le processus commence généralement par un paquet source. Il peut s’agir de code applicatif, d’une image de conteneur, d’un fichier firmware, d’un modèle de configuration, d’une définition d’infrastructure ou d’un paquet de mise à jour système. La source doit être versionnée afin de suivre ce qui a changé, qui l’a modifié et quand l’approbation a été donnée.
Le contrôle de version est essentiel, car le déploiement automatisé dépend d’entrées fiables. Si le paquet source est flou, non testé ou mal documenté, l’automatisation ne fera qu’exécuter plus vite une mauvaise modification.
Construction et packaging
Dans les environnements logiciels, le code source peut être compilé, empaqueté, testé et préparé pour la publication. Dans les environnements d’infrastructure ou d’appareils, le paquet peut inclure des fichiers de configuration, scripts, certificats, listes de dépendances, versions de firmware ou définitions de politiques.
Un bon processus de build produit une sortie prévisible. Cette sortie doit être facile à identifier, stocker, vérifier et déployer. Par exemple, chaque paquet de version peut inclure un numéro de version, une somme de contrôle, des notes de version et des informations de dépendance.
Tests et validation
Avant d’atteindre la production, des contrôles automatisés peuvent vérifier si le paquet peut être publié en sécurité. Ils peuvent inclure tests unitaires, tests d’intégration, analyses de sécurité, validation de configuration, contrôles de compatibilité, vérification des dépendances ou tests de déploiement simulés.
La validation réduit les risques en détectant les problèmes plus tôt. Elle évite aussi de déployer des paquets défectueux auprès d’utilisateurs, d’appareils ou de systèmes métier en service.
Exécution de la publication
Une fois le paquet approuvé, le système de déploiement l’applique à l’environnement cible. Cela peut impliquer la copie de fichiers, le téléchargement d’images de conteneurs, la mise à jour de services, la modification de configurations, le redémarrage d’applications, l’exécution de migrations de base de données, le provisionnement cloud ou l’envoi de firmware à distance.
Le système de déploiement doit enregistrer ce qui se passe pendant l’exécution. Journaux, rapports d’état, horodatages, taux de réussite, cibles en échec et approbations sont utiles pour le dépannage et l’audit.
Surveillance après déploiement
Le déploiement ne se termine pas lorsque le paquet est installé. Après la publication, le système doit surveiller l’état des services, les taux d’erreur, les accès utilisateurs, l’état des appareils, les métriques de performance, les journaux et les conditions de retour arrière.
La surveillance après déploiement aide les équipes à confirmer que la version fonctionne comme prévu. Si des problèmes apparaissent, elles peuvent suspendre le déploiement, revenir en arrière ou appliquer une correction contrôlée.
Modèles courants de déploiement automatisé
Déploiement continu
Le déploiement continu publie automatiquement en production les changements approuvés après réussite des tests et contrôles de politique. Il est courant dans les plateformes SaaS, applications web, systèmes cloud natifs et équipes qui publient fréquemment.
Ce modèle exige des tests solides, une surveillance fiable et une capacité de retour arrière mature. Sans ces contrôles, il peut pousser des problèmes en production trop rapidement.
Déploiement planifié
Le déploiement planifié publie les mises à jour pendant des fenêtres prévues. Il est fréquent dans les systèmes d’entreprise, environnements réglementés, opérations industrielles, hôpitaux, écoles, systèmes publics et infrastructures qui ne peuvent pas changer à tout moment.
Le déploiement planifié équilibre automatisation et contrôle opérationnel. Le processus reste automatisé, mais le moment est choisi pour limiter l’impact utilisateur.
Déploiement par étapes
Le déploiement par étapes publie les changements progressivement. Un petit groupe de test peut recevoir la mise à jour en premier, puis un service, une agence, une région ou un pourcentage plus large d’utilisateurs. Si aucun problème n’apparaît, le déploiement continue.
Cette approche réduit le risque, car un problème touche d’abord un groupe limité. Elle convient aux versions logicielles, mises à jour firmware, applications mobiles, gestion des terminaux et changements de configuration réseau.
Déploiement bleu-vert
Le déploiement bleu-vert utilise deux environnements similaires. L’un exécute la version de production actuelle, tandis que l’autre reçoit la nouvelle version. Après validation, le trafic est basculé vers le nouvel environnement.
Ce modèle peut réduire l’indisponibilité et accélérer le retour arrière. Si la nouvelle version échoue, le trafic peut être redirigé vers l’environnement précédent.
Déploiement canari
Le déploiement canari dirige une petite part du trafic ou des utilisateurs vers la nouvelle version avant d’élargir la publication. Les équipes observent le comportement réel sous exposition limitée, puis décident de continuer ou non.
Il est utile lorsque le comportement en production ne peut pas être totalement prévu en test. Il aide à détecter des problèmes de performance, d’expérience utilisateur ou de compatibilité avant un déploiement complet.
Fonctions clés du déploiement automatisé
Flux de travail répétables
La répétabilité est le fondement du déploiement automatisé. Un flux de déploiement doit produire le même résultat avec la même entrée et les mêmes conditions cibles. Cela réduit l’incertitude et simplifie le dépannage.
Les flux répétables facilitent aussi l’intégration de nouveaux ingénieurs. Le processus ne dépend plus d’un savoir personnel non documenté, mais d’outils, scripts, modèles et règles d’approbation.
Intégration au contrôle de version
Les flux de déploiement se connectent souvent aux systèmes de contrôle de version. Chaque publication peut ainsi être liée à des changements de code, mises à jour de configuration, tickets ou approbations.
Le contrôle de version aide à répondre après un déploiement : qu’est-ce qui a changé, qui l’a approuvé, quelle version fonctionne et comment revenir à un état antérieur.
Configuration des environnements
Le déploiement automatisé doit gérer les différences entre développement, test, préproduction et production. Elles peuvent concerner adresses de base de données, identifiants, points d’API, feature flags, paramètres réseau, limites de ressources ou exigences régionales.
La configuration des environnements doit être traitée avec soin. Les valeurs codées en dur, mots de passe partagés et modifications manuelles peuvent créer des problèmes de sécurité et de fiabilité.
Prise en charge du retour arrière
Le retour arrière permet de revenir à un état fonctionnel précédent si le nouveau déploiement échoue. Un bon processus doit être testé avant d’être nécessaire.
Il peut consister à restaurer une ancienne version applicative, revenir sur une configuration, basculer le trafic vers un ancien environnement, restaurer un instantané de base de données ou désactiver un feature flag. La bonne méthode dépend de l’architecture.
Journaux et pistes d’audit
Le déploiement automatisé doit enregistrer les actions réalisées. Les journaux peuvent inclure version publiée, environnement cible, heure de début, heure de fin, opérateur, statut d’approbation, résultats des tests, étapes en échec et systèmes affectés.
Les pistes d’audit sont utiles pour la conformité, la revue de sécurité, l’analyse d’incident et la gestion interne du changement. Elles aident aussi à savoir si un problème a commencé après une publication précise.
Le déploiement automatisé ne concerne pas seulement la vitesse de publication. Sa valeur profonde est de rendre le changement prévisible, traçable et récupérable.
Avantages du déploiement
Cycles de publication plus rapides
L’automatisation réduit le temps nécessaire pour faire passer les changements du développement ou de la préparation à l’exploitation réelle. Les équipes peuvent publier plus vite corrections, nouvelles fonctions, changements de configuration et correctifs de sécurité.
Un déploiement plus rapide est particulièrement utile pour répondre aux retours clients, vulnérabilités de sécurité, changements métier ou incidents opérationnels.
Réduction des erreurs humaines
Le déploiement manuel implique souvent commandes répétées, transferts de fichiers, listes de contrôle, modifications de configuration et redémarrages. Chaque étape manuelle peut générer une erreur.
Le déploiement automatisé réduit ces erreurs en exécutant des étapes prédéfinies dans le bon ordre. Il diminue aussi la dépendance à la mémoire ou à l’expérience d’une seule personne.
Environnements cohérents
Le déploiement automatisé aide à maintenir la cohérence des environnements. Si le même paquet et les mêmes règles sont utilisés sur plusieurs serveurs, appareils, agences ou régions cloud, les différences cachées diminuent.
La cohérence améliore la fiabilité, car les problèmes sont plus faciles à reproduire et corriger. Elle réduit aussi le cas classique où tout marche en test mais échoue en production à cause de différences d’environnement.
Réponse de sécurité améliorée
Lorsqu’un correctif de sécurité ou une correction de configuration est nécessaire, le déploiement automatisé peut l’appliquer rapidement sur de nombreux systèmes. Cela réduit le temps d’exposition des systèmes vulnérables.
Les équipes sécurité peuvent aussi utiliser l’automatisation pour imposer des configurations de base, mettre à jour des certificats, faire tourner les secrets, supprimer des paramètres non sûrs ou désactiver des fonctions risquées.
Meilleure collaboration
Le déploiement automatisé relie développement, opérations, sécurité, QA et métiers par un processus de publication partagé. Au lieu d’échanger des consignes floues, le flux définit comment les changements sont construits, testés, approuvés, publiés et surveillés.
La communication s’améliore, car chacun peut voir l’état de publication, l’historique de déploiement et les points d’échec.
Déploiement automatisé dans différents environnements
| Environnement | Cible typique du déploiement | Valeur de l’automatisation |
|---|---|---|
| Plateformes cloud | Applications, conteneurs, bases de données, répartiteurs de charge, stockage et politiques réseau. | Prend en charge des changements d’infrastructure répétables et des publications de services évolutives. |
| IT d’entreprise | Serveurs, postes de travail, applications, politiques de terminaux et correctifs de sécurité. | Réduit le support manuel et améliore la cohérence de configuration. |
| Systèmes réseau | Routeurs, commutateurs, pare-feu, passerelles, politiques VPN et règles d’accès. | Aide à contrôler la dérive de configuration et à réduire les erreurs de changement. |
| IoT et appareils | Firmware, profils d’appareils, certificats, paramètres de télémétrie et mises à jour à distance. | Permet la maintenance à grande échelle sans visiter chaque appareil manuellement. |
| Produits logiciels | Applications web, applications mobiles, API, microservices et services backend. | Accélère les cycles de publication tout en améliorant les tests et le contrôle du retour arrière. |
Conseils de maintenance pour le déploiement automatisé
Garder les scripts de déploiement simples
L’automatisation doit rendre le déploiement plus compréhensible, pas plus difficile. Des scripts et pipelines trop complexes créent des risques cachés. Les équipes doivent garder des flux modulaires, documentés et faciles à relire.
Lorsqu’une étape devient difficile à expliquer, elle doit peut-être être divisée en tâches plus petites. Une automatisation simple est plus facile à tester, maintenir et dépanner.
Tester régulièrement le retour arrière
Beaucoup d’équipes conçoivent des plans de retour arrière mais les testent rarement. C’est risqué, car ils peuvent échouer en incident réel si bases de données, dépendances, configurations ou intégrations externes ne sont pas correctement traitées.
Les tests de retour arrière doivent faire partie de la maintenance. Les équipes doivent vérifier que les anciennes versions peuvent être restaurées, que le trafic peut être redirigé et que les données critiques restent sûres.
Surveiller la dérive de configuration
La dérive de configuration apparaît lorsque les environnements changent progressivement hors du processus approuvé. Quelqu’un peut modifier un serveur, mettre à jour un appareil, changer une règle de pare-feu ou modifier un paquet sans l’enregistrer.
La dérive affaiblit l’automatisation, car le prochain déploiement peut devenir imprévisible. Des contrôles réguliers aident à corriger l’écart entre l’état attendu et l’état réel.
Protéger les secrets et identifiants
Les systèmes de déploiement ont souvent besoin d’accéder à des serveurs, comptes cloud, dépôts, API, certificats et bases de données. Ces identifiants doivent être protégés soigneusement.
Les secrets ne doivent pas être stockés directement dans des scripts ou dépôts publics. Il faut utiliser des gestionnaires de secrets, accès par rôle, identifiants à durée courte et journaux d’audit lorsque possible.
Analyser les déploiements échoués
Un déploiement échoué ne doit pas seulement être corrigé rapidement ; il doit aussi être revu. Les équipes doivent déterminer si l’échec vient de tests manquants, dépendances floues, différences d’environnement, retour arrière faible ou surveillance insuffisante.
L’analyse après échec améliore les versions futures. Avec le temps, le processus devient plus fiable.
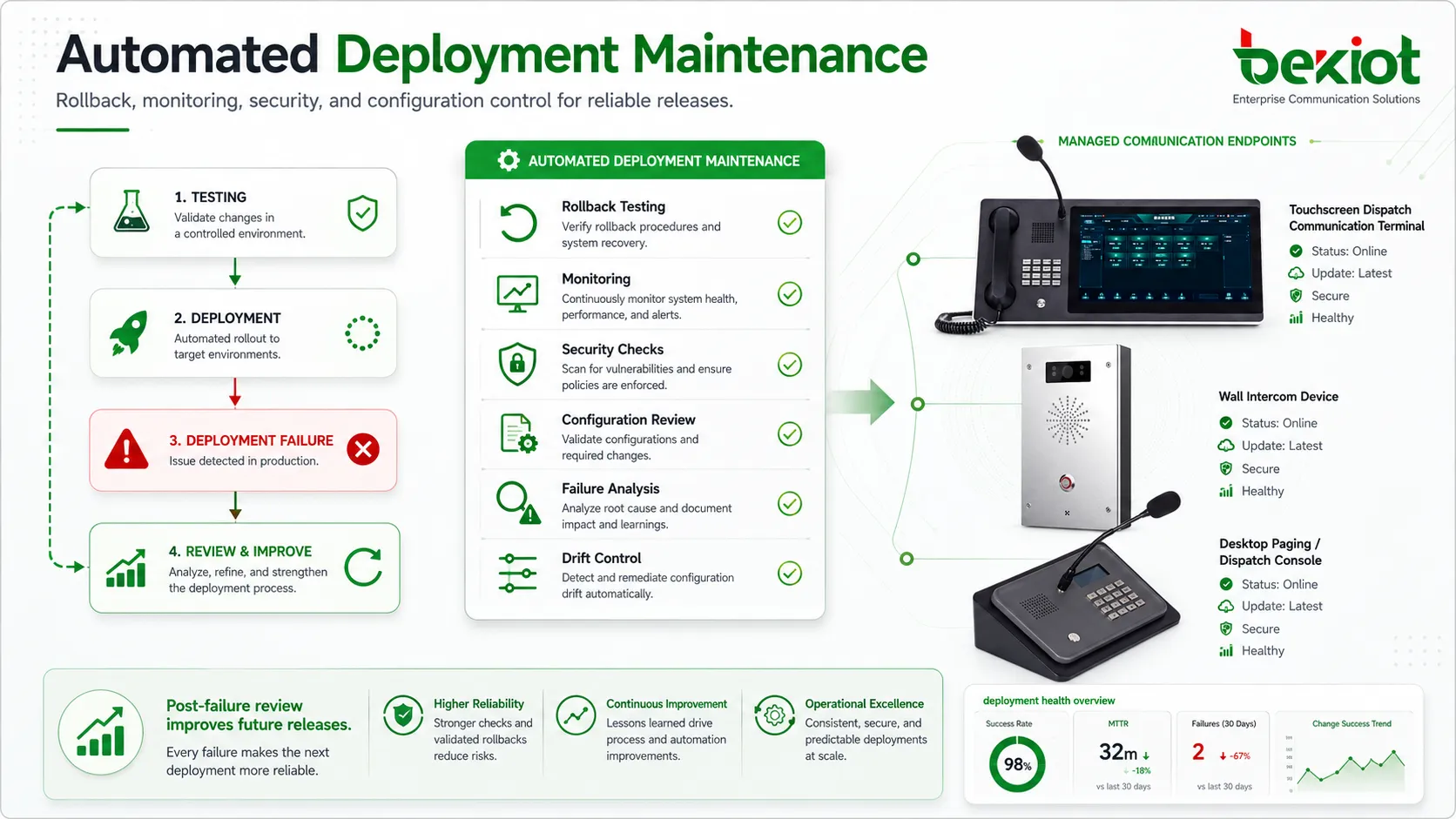
Applications du déploiement automatisé
Gestion des versions logicielles
Les équipes logicielles utilisent le déploiement automatisé pour publier de nouvelles versions d’applications web, API, backends mobiles, logiciels desktop et plateformes SaaS. Le processus peut inclure build, tests, analyse des dépendances, déploiement en préproduction puis publication en production.
Cela permet de livrer plus vite tout en gardant le contrôle. L’historique des versions est aussi plus facile à consulter lorsque des clients signalent des problèmes après une mise à jour.
Provisionnement d’infrastructure cloud
Les environnements cloud peuvent être déployés par des modèles d’infrastructure as code. Au lieu de créer manuellement serveurs, réseaux, bases de données, stockage et politiques d’accès, les équipes les définissent dans des fichiers et les déploient automatiquement.
Cette approche améliore la répétabilité. Un environnement de test, de reprise après sinistre ou régional peut être créé plus régulièrement, car la définition d’infrastructure est réutilisable.
Mises à jour d’applications d’entreprise
Les organisations utilisent le déploiement automatisé pour mettre à jour CRM, ERP, plateformes helpdesk, outils collaboratifs, systèmes de communication et tableaux de bord. L’automatisation réduit l’indisponibilité et garantit que les composants sont mis à jour dans le bon ordre.
Pour les applications d’entreprise, la planification doit considérer les horaires utilisateurs, changements de base de données, dépendances d’intégration et exigences de retour arrière.
Gestion des appareils et du firmware
Le déploiement automatisé est utile pour mettre à jour firmware, profils, certificats et paramètres sur des appareils distribués. Cela peut inclure équipements réseau, appareils IoT, téléphones IP, caméras, points d’accès, passerelles, terminaux industriels ou appareils de terrain.
Le déploiement à distance réduit les visites manuelles sur site. Il aide aussi à maintenir les appareils à jour et conformes aux politiques de sécurité.
Déploiement des correctifs de sécurité
Les équipes sécurité utilisent le déploiement automatisé pour appliquer correctifs système, mises à jour applicatives, règles de pare-feu, politiques de terminaux et corrections de vulnérabilités. Un déploiement plus rapide réduit l’exposition après découverte d’une faille.
L’automatisation des correctifs doit tout de même inclure tests et déploiement par étapes. Appliquer trop vite sans validation peut casser des services, tandis qu’attendre trop longtemps augmente le risque.
Opérations multi-sites
Les organisations avec agences, campus, entrepôts, usines, magasins ou bureaux distants bénéficient du déploiement automatisé, car une même mise à jour peut être appliquée sur de nombreux sites avec un calendrier contrôlé.
C’est utile pour standardiser les configurations, mettre à jour des systèmes de communication, appliquer de nouvelles politiques de sécurité ou préparer des appareils à un nouveau processus métier.
Défis courants
Processus mal définis
L’automatisation ne corrige pas un processus flou. Si le déploiement manuel est incohérent, non documenté ou instable, l’automatiser peut reproduire les mêmes problèmes à plus grande échelle.
Avant d’automatiser, les équipes doivent cartographier le flux, identifier les dépendances, supprimer les étapes inutiles et définir les critères de succès.
Tests insuffisants
Si le déploiement automatisé n’est pas soutenu par des tests adaptés, de mauvais changements peuvent avancer rapidement dans le pipeline. Les tests doivent couvrir fonctionnalité, configuration, sécurité, performance, compatibilité et conditions de retour arrière lorsque possible.
Les tests n’ont pas besoin d’être parfaits avant de commencer, mais ils doivent s’améliorer avec la maturité du processus.
Sur-automatisation
Toutes les étapes ne doivent pas être entièrement automatiques. Certains changements à haut risque exigent approbation manuelle, fenêtre de maintenance, confirmation métier ou revue supplémentaire.
Une bonne stratégie automatise là où répétabilité et vitesse comptent, tout en gardant un contrôle humain lorsque le jugement est nécessaire.
Fragmentation des outils
Les grandes organisations peuvent utiliser de nombreux outils de déploiement selon les équipes. L’une peut utiliser une plateforme CI/CD, une autre des scripts, une autre un outil de gestion d’appareils et une autre des outils cloud natifs.
La fragmentation complique la gouvernance. Des modèles standard, politiques partagées, guides d’intégration et rapports communs peuvent réduire ce problème.
Considérations de sécurité
Les systèmes de déploiement automatisé disposent souvent d’accès puissants. S’ils sont compromis, ils peuvent modifier la production, distribuer du code malveillant, exposer des secrets ou désactiver des contrôles. Ils doivent donc être protégés comme une infrastructure critique.
L’accès doit être limité par rôle. Développeurs, opérateurs, sécurité et prestataires externes ne doivent pas avoir les mêmes privilèges. Approbations, revue de code, paquets signés, branches protégées et restrictions d’environnement réduisent le risque.
Les journaux doivent être surveillés pour détecter versions inattendues, changements hors fenêtre approuvée, échecs répétés ou accès depuis des lieux inhabituels. La sécurité doit être intégrée au processus, non ajoutée après coup.
Le pipeline de déploiement est un système de production. S’il peut modifier des services en direct, il doit être sécurisé, surveillé et maintenu avec le même sérieux que les services qu’il déploie.
Bonnes pratiques pour le déploiement automatisé
Commencez par un processus stable avant d’ajouter une automatisation complexe. Un processus manuel clair est plus facile à automatiser qu’un processus chaotique. Les équipes doivent définir chaque étape, entrée requise, point d’approbation, condition de succès et action de retour arrière.
Utilisez le contrôle de version pour le code, la configuration, les scripts et les définitions d’infrastructure. Cela rend les changements traçables et permet de relire les différences avant publication.
Intégrez les tests automatisés au flux de travail. Ils doivent détecter les erreurs courantes avant que le déploiement atteigne la production. Avec le temps, la couverture doit inclure des scénarios de panne réels et des points d’intégration.
Utilisez un déploiement par étapes pour les systèmes importants. Déployez d’abord sur un petit groupe, puis élargissez après confirmation du comportement normal par la surveillance. Cela réduit l’impact des problèmes inattendus.
Tenez les personnes informées. L’automatisation ne doit pas masquer ce qui se passe. Tableaux de bord, notifications, notes de version, approbations et rapports d’état aident les équipes à rester alignées.
Choisir une approche de déploiement automatisé
La bonne approche dépend du type de système, du niveau de risque, de la fréquence de publication, de la maturité de l’équipe et de l’environnement opérationnel. Une plateforme SaaS peut nécessiter un déploiement continu, tandis qu’un hôpital, une usine ou une plateforme publique peut exiger des fenêtres planifiées et strictement approuvées.
Les petites équipes peuvent commencer par de simples scripts et hooks de contrôle de version. Les grandes organisations peuvent avoir besoin de plateformes CI/CD complètes, infrastructure as code, dépôts d’artefacts, gestion d’environnements, analyses de sécurité et workflows d’approbation.
Il faut aussi considérer la maintenabilité. Un système de déploiement compris par un seul ingénieur devient un risque. L’approche choisie doit être documentée, partagée, revue et conçue pour être supportée durablement par l’équipe.
Limites du déploiement automatisé
Le déploiement automatisé améliore vitesse et cohérence, mais ne garantit pas de bonnes versions. Exigences faibles, tests insuffisants, mauvaise architecture, dépendances cachées ou plans de retour arrière flous peuvent encore causer des problèmes.
L’automatisation peut aussi amplifier l’échelle des erreurs. Une erreur manuelle peut toucher un serveur, alors qu’une erreur automatisée peut toucher des centaines de systèmes si les garde-fous manquent.
C’est pourquoi le déploiement automatisé doit être associé à gouvernance, surveillance, contrôles d’approbation, tests, planification de sauvegarde et responsabilité opérationnelle claire.
Questions fréquentes
Le déploiement automatisé est-il identique au déploiement continu ?
Non. Le déploiement automatisé signifie que le processus de publication est exécuté par des outils ou scripts. Le déploiement continu est un modèle précis où les changements approuvés sont automatiquement publiés en production après les contrôles.
Le déploiement automatisé peut-il être utilisé pour des appareils matériels ?
Oui. Il peut servir aux mises à jour firmware, profils de configuration, certificats, politiques de sécurité et paramètres d’appareils sur du matériel géré, comme équipements réseau, terminaux IoT, téléphones IP et terminaux de terrain.
Que faut-il automatiser en premier ?
Les équipes doivent commencer par des étapes répétitives, peu risquées et bien comprises, comme la copie de paquets, la préparation d’environnement, la validation de configuration ou l’exécution de tests. Les changements de production à haut risque ne doivent être automatisés qu’après stabilisation du processus.
Pourquoi les déploiements automatisés échouent-ils ?
Les causes courantes incluent dépendances manquantes, différences d’environnement, tests échoués, identifiants incorrects, problèmes réseau, mauvaise configuration, erreurs de migration de base de données ou changements manuels hors processus.
L’automatisation supprime-t-elle le besoin de maintenance ?
Non. Les systèmes de déploiement automatisé nécessitent encore de la maintenance. Scripts, identifiants, outils, cas de test, dépendances, modèles et procédures de retour arrière doivent être régulièrement revus et mis à jour.