Un problème de base de données reste rarement limité à la base elle-même. Lorsque l’unique copie des données devient lente, inaccessible, corrompue ou surchargée, le système métier qui repose dessus en subit immédiatement les effets : les commandes ne peuvent plus être enregistrées, les rapports ne sortent plus, les appareils ne téléversent plus leurs journaux, les utilisateurs ne se connectent plus et la reprise devient une course contre le temps.
La réplication de base de données existe pour cette raison. Elle crée une ou plusieurs copies supplémentaires des données et les maintient synchronisées avec la base source, afin que les systèmes puissent lire plus vite, reprendre plus vite, répartir les charges et continuer à fonctionner lorsqu’un seul nœud de base de données ne suffit plus.
Le principe de base de la réplication de base de données
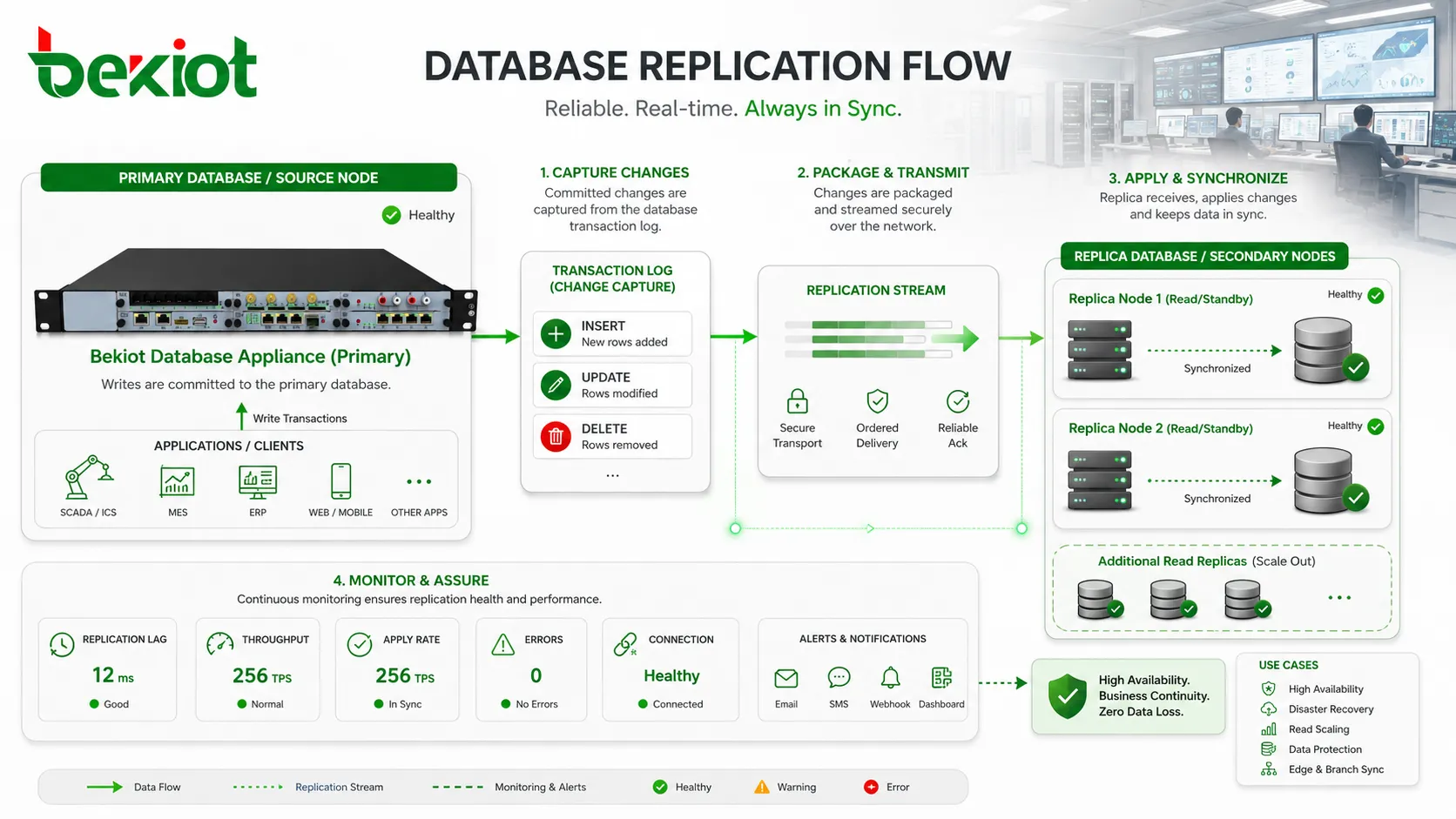
La réplication de base de données consiste à copier des données d’un nœud vers un autre et à maintenir ces copies à jour à mesure que les changements surviennent. La base source peut être appelée primaire, maître, éditeur ou leader selon la technologie. La base qui reçoit les données peut être appelée réplique, base de secours, abonné, secondaire ou suiveur. Les termes varient, mais l’objectif reste le même : transmettre de façon contrôlée les changements produits à un endroit vers un autre endroit.
Les données copiées peuvent être des bases complètes, des tables choisies, des partitions, des schémas, des journaux de transactions ou des flux précis. Dans certains systèmes, la réplique sert seulement à la sauvegarde ou au basculement. Dans d’autres, elle prend en charge des lectures, de l’analyse, du reporting, un accès régional ou des traitements en aval. La réplication n’est donc pas une fonction unique, mais une méthode d’architecture adaptée à différents objectifs d’exploitation.
Au centre de la réplication se trouve le suivi des changements. Quand des données sont insérées, mises à jour ou supprimées, la base doit identifier le changement, le conditionner de manière fiable, l’envoyer à un autre nœud et l’appliquer dans le bon ordre. Si ce processus est négligé, la réplique peut devenir incohérente. S’il est trop lent, elle prend du retard. S’il n’est pas surveillé, les équipes peuvent découvrir le problème seulement au moment de la reprise.
Une bonne conception répond à plusieurs questions pratiques : quelles données copier, à quelle vitesse elles doivent arriver, qui peut écrire, comment les conflits sont traités, ce qui se passe en cas de panne réseau et comment les applications doivent réagir si un nœud est indisponible. Ces réponses déterminent si la réplication devient un outil de résilience ou une source cachée de confusion.
Ce qui circule réellement entre les nœuds
La réplication n’est pas toujours une simple copie de fichiers. Dans la plupart des systèmes de production, la base ne renvoie pas tout le jeu de données à chaque modification d’un enregistrement. Elle capture plutôt le changement et transfère uniquement ce qui est nécessaire pour le reproduire sur la réplique. Cela réduit la bande passante et permet à la réplique de rester proche de la source sans reconstruction complète.
Une méthode courante est la réplication basée sur les journaux. La base primaire enregistre les changements dans des journaux de transactions, journaux binaires, journaux d’écriture anticipée ou journaux redo. La réplique lit ces journaux et applique les mêmes opérations dans l’ordre. Cette méthode est largement utilisée, car le journal représente déjà l’ordre officiel des changements.
Une autre méthode est la réplication par instructions, où des instructions SQL sont envoyées à la réplique. Elle peut être plus simple dans certains systèmes, mais elle peut créer des écarts si une instruction dépend de fonctions non déterministes, de valeurs temporelles, de valeurs aléatoires ou du comportement propre à l’environnement. La réplication par lignes réduit ces risques en envoyant les changements réels des lignes.
Certains systèmes utilisent la réplication par instantané. Une copie totale ou partielle des données est prise à un instant donné puis livrée à un autre emplacement. C’est utile pour la synchronisation initiale, les bases de reporting ou la distribution périodique. Mais les instantanés seuls ne suffisent généralement pas aux systèmes qui exigent des mises à jour presque temps réel.
Les architectures modernes peuvent aussi utiliser la capture de données de changement, ou CDC. La CDC extrait les changements de la base et les envoie à des plateformes analytiques, index de recherche, files de messages ou lacs de données. Dans ce cas, la réplication ne consiste plus seulement à maintenir une autre copie de base ; elle devient une partie du pipeline de données de l’organisation.
La réplication primaire-réplique au quotidien
Le modèle le plus connu est la réplication primaire-réplique. Un nœud accepte les écritures, tandis qu’une ou plusieurs répliques reçoivent les changements. Les applications envoient les insertions, mises à jour et suppressions à la primaire. Les requêtes en lecture seule peuvent être envoyées aux répliques si l’application et l’architecture le permettent.
Ce modèle est facile à comprendre et très utilisé parce qu’il clarifie la propriété des écritures. La primaire est l’autorité des changements, les répliques suivent son état. Si une réplique tombe, la primaire continue. Si la primaire échoue, une réplique peut être promue comme nouvelle primaire selon le plan de basculement.
L’avantage est de séparer les charges. Les écritures transactionnelles, opérations utilisateur et mises à jour métier restent sur la primaire, tandis que rapports, tableaux de bord, recherches ou services très lecteurs peuvent utiliser les répliques. Cela réduit la pression sur la base principale et améliore la réponse aux utilisateurs.
Les applications doivent toutefois savoir qu’une réplique n’est pas toujours parfaitement à jour, surtout en mode asynchrone. Un utilisateur qui écrit sur la primaire puis lit immédiatement sur une réplique en retard peut ne pas voir le dernier changement. Ce n’est pas forcément une panne ; c’est un compromis de conception à gérer avec soin.
Modèles multi-primaires et distribués
Certains environnements ont besoin de plusieurs nœuds capables d’écrire. En réplication multi-primaire, plusieurs nœuds acceptent les écritures puis répliquent les changements entre eux. Cela peut soutenir des sites distribués, des opérations régionales, l’écriture locale ou la haute disponibilité entre centres de données. L’idée est séduisante, mais elle est plus complexe que le modèle primaire-réplique.
Le défi principal est le conflit. Si deux nœuds modifient le même enregistrement au même moment, le système doit décider quelle modification gagne ou comment les fusionner. Les règles peuvent reposer sur l’horodatage, les versions, la logique applicative, la priorité du nœud ou une résolution manuelle. Une mauvaise gestion des conflits dégrade la qualité des données.
La réplication distribuée est aussi utilisée dans les systèmes de périphérie, magasins, sites industriels, applications mobiles ou opérations éloignées où les données locales doivent rester disponibles malgré une connexion centrale instable. Un nœud local peut stocker et modifier temporairement les données puis se synchroniser plus tard avec le système central. Cela améliore la continuité locale, mais impose des règles strictes.
Les architectures multi-primaires doivent être choisies seulement lorsque le besoin métier justifie cette complexité. Pour beaucoup d’applications, une primaire d’écriture avec répliques de lecture est plus simple à exploiter. Lorsque les écritures locales multiples sont nécessaires, la gestion des conflits, la propriété des données et la supervision doivent être définies avant le déploiement.
Réplication synchrone et asynchrone
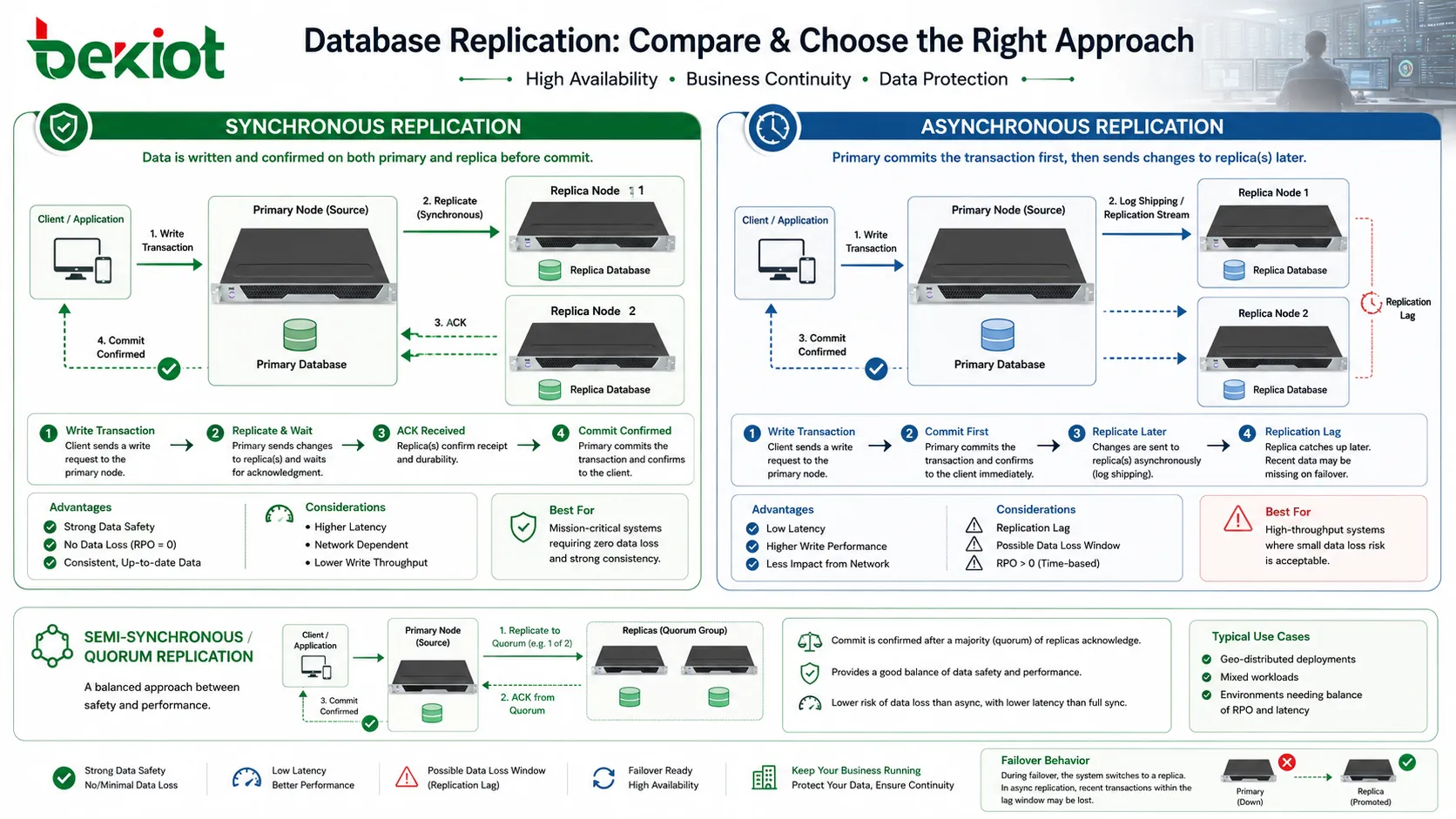
Le moment de la réplication est une décision majeure. En mode synchrone, une transaction n’est pleinement validée que lorsqu’un autre nœud confirme le changement. Cela améliore la sécurité des données, car la réplique possède le changement avant que l’application reçoive la confirmation. Si la primaire tombe juste après, les données confirmées ont plus de chances d’exister ailleurs.
Le coût est la latence. Si la réplique est éloignée ou si le réseau est lent, la primaire attend plus longtemps pour terminer la transaction. Cela peut affecter le temps de réponse applicatif. La réplication synchrone convient surtout aux environnements où la perte de données tolérée est très faible et où le réseau entre nœuds est fiable.
En mode asynchrone, la primaire valide d’abord la transaction puis envoie ensuite le changement aux répliques. Les écritures sont plus rapides, car l’application n’attend pas une confirmation distante. Ce mode est courant pour le reporting, l’extension de lecture ou la reprise après sinistre à longue distance.
Le compromis est le retard de réplication. Si la primaire échoue avant que les changements atteignent la réplique, certaines transactions récentes peuvent être perdues ou devoir être récupérées dans les journaux. Le mode asynchrone doit donc correspondre à des objectifs de reprise clairs, avec une perte acceptable et un délai de rattrapage attendu.
Certains systèmes utilisent des modes semi-synchrones ou basés sur quorum pour équilibrer performance et sécurité. Ils confirment une transaction après réponse d’une ou plusieurs répliques sans attendre toutes les copies. Le bon choix dépend du risque métier, de la qualité du réseau, du volume de transactions et des exigences de reprise.
Disponibilité et avantages du basculement
Le bénéfice le plus direct est l’amélioration de la disponibilité. Si la base primaire échoue, une réplique peut être promue pour continuer le service. Sans réplication, la reprise dépend souvent d’une restauration de sauvegarde, plus longue et parfois moins récente. La réplication offre une copie vivante ou quasi vivante utilisable pour une reprise plus rapide.
Le basculement peut être manuel ou automatique. Le mode manuel donne plus de contrôle aux administrateurs, ce qui est utile dans les environnements complexes ou lorsque le risque de split-brain doit être évité. L’automatique réduit l’interruption, mais doit empêcher que deux nœuds se considèrent primaires. Les systèmes haute disponibilité s’appuient souvent sur la supervision, les contrôles de santé, le quorum ou la gestion de cluster.
La disponibilité dépend aussi du comportement des applications. Promouvoir une réplique ne suffit pas si les applications ne se reconnectent pas, si le DNS se propage lentement, si les pools gardent l’ancienne adresse ou si les utilisateurs doivent changer la configuration. La réplication doit donc être pensée avec le routage applicatif, les équilibreurs, les chaînes de connexion, la découverte de service et les procédures d’exploitation.
Une réplique peut aussi faciliter la maintenance. Pendant les mises à jour, correctifs, remplacements matériels ou migrations de stockage, certaines charges peuvent être déplacées vers un autre nœud. Cela réduit les arrêts planifiés et donne plus de souplesse aux administrateurs. Les meilleurs designs couvrent à la fois l’urgence et la maintenance courante.
Étendre les lectures sans changer le modèle principal
De nombreux systèmes ne saturent pas à cause des écritures, mais parce que les lectures augmentent. Tableaux de bord, rapports, pages de recherche, portails clients, outils de supervision et appels API peuvent tous lire la même base. Si toutes ces lectures frappent la primaire, les transactions normales ralentissent. La réplication permet de répartir ces lectures sur des répliques.
Les répliques de lecture servent souvent au reporting et à l’analyse. Les requêtes longues peuvent s’exécuter sur réplique sans bloquer ni ralentir le travail transactionnel critique sur la primaire. C’est utile lorsque les équipes métier ont besoin de rapports fréquents mais que la production doit rester réactive.
La séparation lecture-écriture côté application améliore aussi l’évolutivité. L’application envoie les écritures à la primaire et certaines lectures aux répliques. Il faut rester prudent, car les répliques peuvent être en retard. Les données qui exigent une cohérence immédiate doivent parfois être lues sur la primaire ; celles qui tolèrent un léger délai peuvent utiliser les répliques.
Cette approche augmente la capacité de lecture sans refondre tout le modèle de données. Au lieu de basculer immédiatement vers une nouvelle architecture, l’équipe peut ajouter des répliques, optimiser le routage des requêtes et isoler les charges de reporting. C’est souvent une étape de montée en charge très pratique.
Reprise après sinistre et résilience géographique
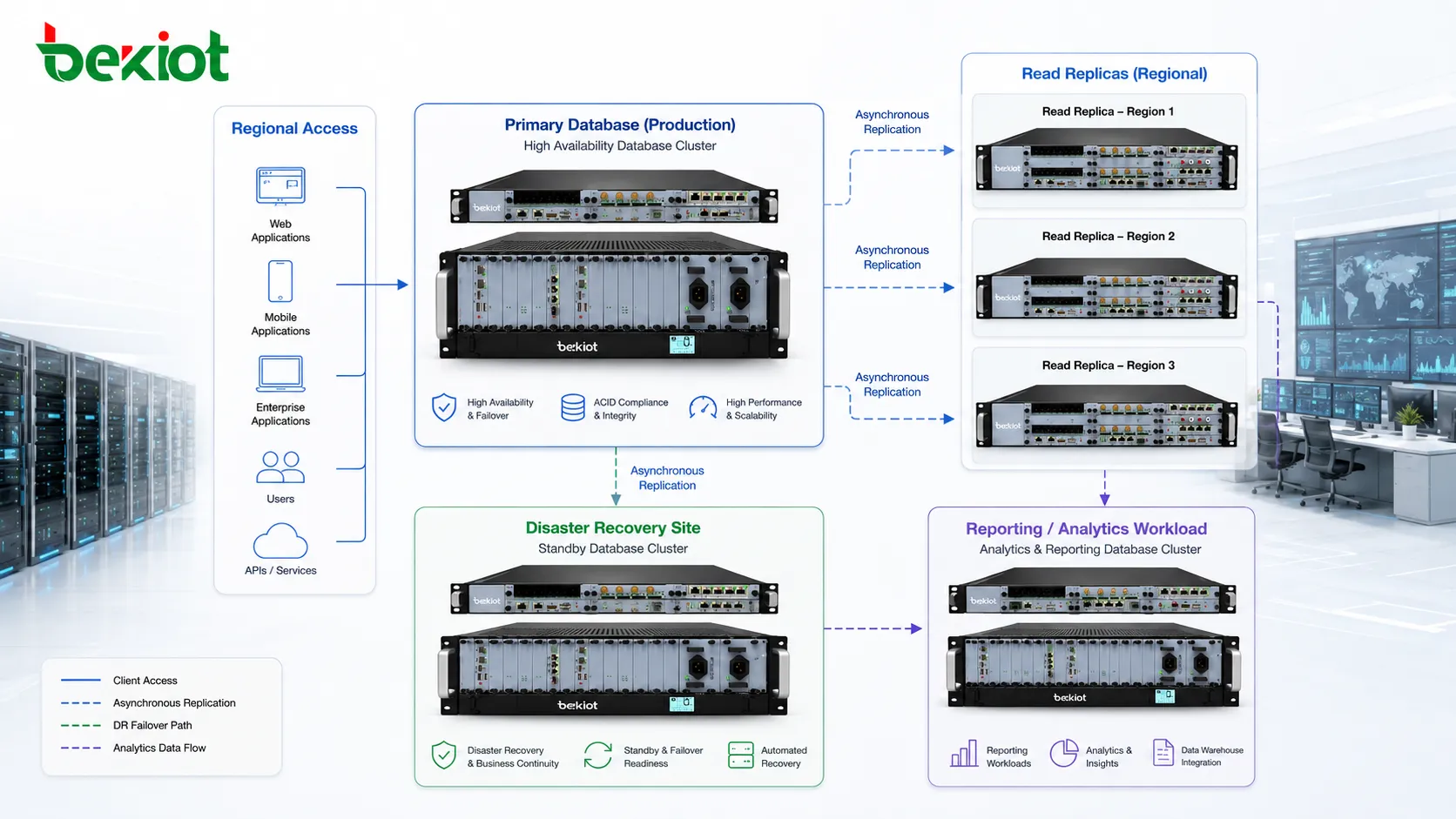
La réplication sert souvent à la reprise après sinistre. Une réplique dans un autre centre de données, une autre région cloud ou un autre site physique protège contre incendie, panne électrique, rupture réseau, panne de stockage ou sinistre local. Si le site primaire devient indisponible, la réplique distante peut devenir le chemin de reprise.
La réplication géographique doit être planifiée avec soin, car la distance augmente la latence. Le mode synchrone sur longue distance peut être trop lent pour certaines applications. Le mode asynchrone est plus courant pour la reprise distante, mais il introduit un risque de perte si le site primaire tombe avant la copie de tous les changements.
La planification doit définir le RTO et le RPO. Le RTO indique la vitesse à laquelle le service doit revenir. Le RPO indique la perte de données acceptable. Un RPO strict peut exiger une protection plus synchrone ou un retard très faible. Un RPO plus souple peut accepter l’asynchrone avec contrôles réguliers.
La reprise après sinistre nécessite aussi des tests. Une réplique jamais promue, jamais vérifiée avec les applications ou jamais restaurée dans un scénario réaliste peut ne pas être fiable au moment critique. La réplication fournit la base technique ; les exercices prouvent que le processus fonctionne.
Localité des données et performance régionale
La réplication peut rapprocher les données des utilisateurs, agences ou applications régionales. Quand les utilisateurs lisent depuis une réplique proche, le temps de réponse peut s’améliorer. C’est utile pour les applications mondiales, services multirégions, chaînes de magasins, réseaux logistiques, plateformes financières et systèmes d’entreprise distribués.
Les répliques régionales réduisent aussi la pression sur les liens centraux. Au lieu d’envoyer chaque requête sur une longue distance, les utilisateurs ou services locaux lisent une copie proche. C’est particulièrement utile lorsque le trafic de lecture est important et que les exigences de fraîcheur restent maîtrisables.
La localité des données soutient aussi le reporting local. Un bureau régional peut analyser ses transactions, stocks, dossiers de service ou données opérationnelles sans charger constamment la base centrale de production. Une base répliquée locale donne cet accès pendant que le système central reste concentré sur les transactions principales.
Il faut toutefois respecter la gouvernance des données. Certaines données peuvent être limitées par la loi, la politique interne, les contrats clients ou la réglementation sectorielle. Copier des données vers une autre région ou un autre pays peut nécessiter approbation, chiffrement, contrôle d’accès ou minimisation. La réplication doit améliorer la performance sans affaiblir la conformité.
La sauvegarde n’est pas la réplication
Réplication et sauvegarde sont souvent associées, mais elles ne résolvent pas le même problème. La réplication maintient une autre copie de base à jour pour la disponibilité, la performance ou la distribution. La sauvegarde crée des copies historiques restaurables après suppression, corruption, ransomware, changement accidentel ou perte durable de données.
Une réplique peut recopier fidèlement une erreur. Si un utilisateur supprime des enregistrements importants dans la primaire, la réplication peut les supprimer rapidement dans la réplique. Si une application écrit des données corrompues, la réplique peut recevoir le même état. Dans ce cas, la réplication ne protège pas l’organisation sans restauration à un point dans le temps, réplication différée ou sauvegardes.
Les sauvegardes sont plus lentes à restaurer, mais plus adaptées à la récupération historique. Elles permettent de revenir à un état antérieur. La réplication est plus rapide pour la continuité de service, mais ne garantit pas un retour historique. Une stratégie solide inclut généralement les deux.
La distinction doit être explicite dans les procédures. Pour un basculement rapide, la réplication est utile. Pour récupérer des données de la semaine précédente, la sauvegarde est indispensable. Pour obtenir les deux, l’organisation doit concevoir et tester les deux processus régulièrement.
Surveiller la santé de la réplication
La réplication doit être surveillée en continu. Une réplique en retard de plusieurs heures peut paraître en ligne, mais être inutile pour le basculement ou inexacte pour le reporting. Les indicateurs courants sont le retard de réplication, l’état de la réplique, l’avancement des journaux, la vitesse d’application, les erreurs, la connexion, l’espace disque, le délai transactionnel et les échecs de synchronisation.
Le retard de réplication est essentiel. Il mesure le temps entre un changement sur la primaire et sa disponibilité sur la réplique. Un petit retard peut convenir au reporting. Un grand retard peut casser les hypothèses applicatives ou augmenter le risque de perte lors du basculement. Les seuils doivent être définis pour chaque usage.
Le stockage et la capacité doivent aussi être suivis. La réplication peut générer journaux, fichiers temporaires, relay logs, journaux archivés ou données de staging. Si le disque est plein, la réplication peut s’arrêter. Si la réplique est sous-dimensionnée, elle n’appliquera pas les changements assez vite en pointe. Une réplique doit être dimensionnée pour sa charge réelle.
Les alertes doivent être exploitables. Elles ne devraient pas seulement dire que la réplication a échoué, mais aider à savoir si la cause vient du réseau, de l’authentification, de la position de journal, du disque, du schéma, des droits ou d’écritures conflictuelles. Plus la cause est claire, plus le chemin de données est rétabli vite.
Sécurité et contrôle d’accès
La réplication multiplie les endroits où des données sensibles existent. Chaque réplique doit être protégée avec le même sérieux que la primaire. Une réplique moins sécurisée peut devenir le chemin le plus simple vers une fuite. La sécurité doit inclure chiffrement, contrôle d’accès, journaux d’audit, restrictions réseau et gestion des identifiants pour chaque nœud.
Le trafic de réplication doit être protégé, surtout lorsqu’il traverse centres de données, régions cloud, réseaux publics ou liens tiers. Le chiffrement en transit limite l’interception. L’authentification entre nœuds empêche des systèmes non autorisés de rejoindre la réplication. La segmentation réseau réduit l’exposition aux systèmes non liés.
Les permissions sur les répliques doivent être revues séparément. Une réplique de reporting peut être en lecture seule pour les analystes, mais cela ne signifie pas que toutes les tables doivent être visibles par tous. Les champs sensibles peuvent exiger masquage, filtrage ou politique d’accès distincte. Parfois, la réplique ne doit contenir que les données utiles à son objectif.
L’accès administratif doit aussi être contrôlé. Les utilisateurs capables d’arrêter la réplication, de promouvoir une réplique, de modifier les filtres ou les identifiants disposent de pouvoirs importants. Ces actions doivent être journalisées et réservées au personnel autorisé. La réplication fait partie du périmètre de confiance de la base, pas seulement d’un mécanisme de fond.
Erreurs courantes au déploiement
Une erreur fréquente consiste à déployer la réplication sans définir le vrai objectif. Si l’objectif est la disponibilité, il faut prévoir le basculement et la reconnexion applicative. Si l’objectif est le reporting, il faut gérer la charge et la fraîcheur des données. Si l’objectif est la reprise après sinistre, il faut un site distant, un RTO, un RPO et des exercices. Un objectif flou produit une architecture floue.
Une autre erreur est de supposer que la réplique est toujours à jour. Les répliques asynchrones peuvent prendre du retard. Écritures massives, réseau instable, disques lents, changements de schéma ou longues transactions peuvent retarder la réplication. Les applications qui lisent sur réplique doivent être conçues avec ce délai.
Certaines équipes ne testent jamais la promotion. Elles créent des répliques sans pratiquer le basculement. En urgence, elles découvrent des problèmes de droits, de connexion, de tâches manquantes, de configuration incomplète ou de données incohérentes. Le basculement doit être testé avant d’être nécessaire.
Les filtres de réplication peuvent aussi créer des malentendus. Si seules certaines tables ou bases sont répliquées, les équipes doivent savoir exactement ce qui est inclus et exclu. Un service de reporting peut croire disposer de toutes les données alors qu’une partie seulement du schéma est copiée. Une documentation claire évite ces hypothèses.
Enfin, beaucoup de projets sous-estiment la maintenance. La réplication doit survivre aux mises à jour, changements de schéma, renouvellements de certificats, rotations de mots de passe, croissance de stockage, évolutions réseau et différences de versions. Ce n’est pas une fonction à oublier après configuration ; elle a besoin d’un responsable.
Quand la réplication apporte le plus de valeur
La réplication apporte le plus de valeur lorsque l’organisation a un besoin clair de disponibilité, d’extension de lecture, de reprise après sinistre, de distribution de données ou de séparation des charges. Elle est moins utile si la base est petite, la tolérance à l’arrêt élevée, les lectures faibles et la restauration de sauvegarde suffisante. Comme toute architecture, elle doit répondre au problème réel.
Pour les systèmes critiques, elle réduit l’interruption et améliore les options de reprise. Pour les applications en croissance, elle éloigne reporting et lectures de la primaire. Pour les organisations distribuées, elle soutient l’accès régional. Pour les équipes data, elle livre des données opérationnelles aux plateformes analytiques sans perturber la production.
Les meilleurs designs sont souvent simples et explicites. Ils définissent quel nœud accepte les écritures, quels nœuds servent les lectures, comment le retard est surveillé, comment le basculement fonctionne, comment les sauvegardes sont maintenues et qui est responsable de la réplication. La complexité ne doit être ajoutée que si la raison métier est forte.
La réplication n’est pas une copie magique de sécurité. C’est une manière disciplinée de maintenir les données disponibles à plusieurs endroits. Ses bénéfices apparaissent lorsque la conception technique, le comportement applicatif, la supervision, la sécurité et la reprise sont pensés ensemble.
FAQ
La réplication sert-elle surtout à la sauvegarde ?
Non. Elle peut aider la reprise, mais ne remplace pas les sauvegardes. Une réplique peut copier une suppression accidentelle ou des données corrompues depuis la primaire. Les sauvegardes restent nécessaires pour la récupération historique et la restauration à un point dans le temps.
Qu’est-ce que le retard de réplication ?
C’est le délai entre la validation d’un changement sur la base primaire et son apparition sur la réplique. Il est courant en mode asynchrone et doit être surveillé lorsque les répliques servent aux lectures ou au basculement.
Les applications peuvent-elles écrire sur les répliques ?
Dans les modèles primaire-réplique, les répliques sont généralement en lecture seule. Les systèmes multi-primaires autorisent les écritures sur plusieurs nœuds, mais exigent une gestion des conflits et un contrôle opérationnel plus strict.
La réplication améliore-t-elle les performances ?
Elle peut améliorer les performances en déplaçant les lectures, rapports et analyses hors de la primaire. Elle n’accélère pas automatiquement toutes les charges. Les systèmes très écrivains peuvent aussi nécessiter indexation, optimisation, partitionnement, matériel plus puissant ou changement d’architecture.
Que faut-il tester avant de s’y fier ?
Il faut tester la synchronisation initiale, le retard sous charge, le basculement, la promotion de réplique, la reconnexion applicative, la restauration de sauvegarde, les alertes, les permissions de sécurité et le comportement lors d’une interruption réseau.