La haute disponibilité est une approche de conception qui permet à un système, un service, une application ou un réseau de rester accessible même lorsque des composants individuels tombent en panne. Au lieu de dépendre d'un seul serveur, d'une seule base de données, d'un seul chemin réseau, d'une seule source d'alimentation ou d'un seul processus logiciel, un système hautement disponible exploite la redondance, la supervision, le basculement automatique et la planification de la reprise pour réduire les interruptions et assurer la continuité de service.
Pour les entreprises et les organisations qui s'appuient sur les opérations numériques, la haute disponibilité n'est pas qu'un concept informatique. Elle impacte l'expérience client, l'efficacité de la production, la réponse aux urgences, la fiabilité des communications, l'accès aux données, les opérations de sécurité et les engagements de niveau de service. Une brève coupure peut être acceptable pour un outil interne peu prioritaire, mais la même interruption devient inacceptable pour un système hospitalier, une plateforme de dispatch, une passerelle de paiement, un réseau de contrôle industriel, un service de communication public ou une application cloud utilisée par des milliers d'utilisateurs.
Signification concrète dans la conception système
La haute disponibilité, souvent abrégée en HA, désigne la capacité d'un système à rester utilisable pendant un pourcentage de temps élevé. On en parle couramment à travers des objectifs de temps de fonctionnement comme 99,9 %, 99,99 % ou 99,999 %. Cependant, la disponibilité ne se limite pas à savoir si un serveur est sous tension. Un système n'est véritablement disponible que lorsque les utilisateurs peuvent accomplir les actions dont ils ont besoin : passer un appel, soumettre une transaction, ouvrir une application, recevoir une alarme, synchroniser des enregistrements ou accéder à des informations en temps réel.
Un service fiable dépend de la chaîne de service complète. Celle-ci peut inclure des ressources de calcul, du stockage, des moteurs de base de données, des commutateurs réseau, des pare-feux, des serveurs DNS, des services d'identité, des certificats de sécurité, des processus applicatifs, des outils de supervision, des liens de secours, l'infrastructure électrique et les procédures opérationnelles. Si une dépendance critique ne possède aucun chemin de secours, l'ensemble du service peut rester vulnérable.
La haute disponibilité se distingue également de la simple sauvegarde. Une sauvegarde aide à restaurer les données après une panne, mais elle ne maintient pas forcément le service opérationnel pendant la panne. La HA se concentre sur la continuité. Elle permet à un autre nœud, chemin, instance de service ou site de prendre le relais avant que les utilisateurs ne subissent une longue interruption.
Pourquoi les organisations construisent pour la continuité
La valeur de la haute disponibilité devient évidente lorsque les temps d'arrêt entraînent de vraies conséquences. Dans le e-commerce, une panne peut signifier des commandes perdues et des échecs de paiement. Dans les télécommunications, cela peut entraîner des appels manqués, des postes injoignables ou un routage d'urgence interrompu. Dans l'industrie manufacturière, cela peut arrêter les flux de production. Dans le secteur de la santé et de la sécurité publique, cela peut retarder la communication, la coordination et l'intervention.
La disponibilité protège aussi la confiance. Clients, employés, partenaires et équipes de terrain s'attendent à ce que les systèmes modernes soient accessibles à tout moment. Lorsqu'une plateforme est régulièrement hors ligne, les utilisateurs peuvent perdre confiance, même si chaque panne est brève. Pour les fournisseurs de services et les plateformes d'entreprise, une disponibilité stable fait partie intégrante de l'expérience produit globale.
Une autre raison est la maîtrise opérationnelle. Sans planification HA, les équipes techniques s'appuient souvent sur un dépannage d'urgence après qu'une panne a déjà affecté les utilisateurs. Avec de la redondance, des contrôles de santé automatisés, une logique de basculement et des procédures d'incident claires, les pannes deviennent des événements maîtrisés plutôt que des crises imprévues.
Un système hautement disponible ne part pas du principe que les pannes n'arriveront jamais. Il part du principe qu'elles arriveront et prépare le service à continuer de fonctionner lorsqu'elles surviennent.
Fonctionnalités clés pour un fonctionnement fiable
Infrastructure redondante
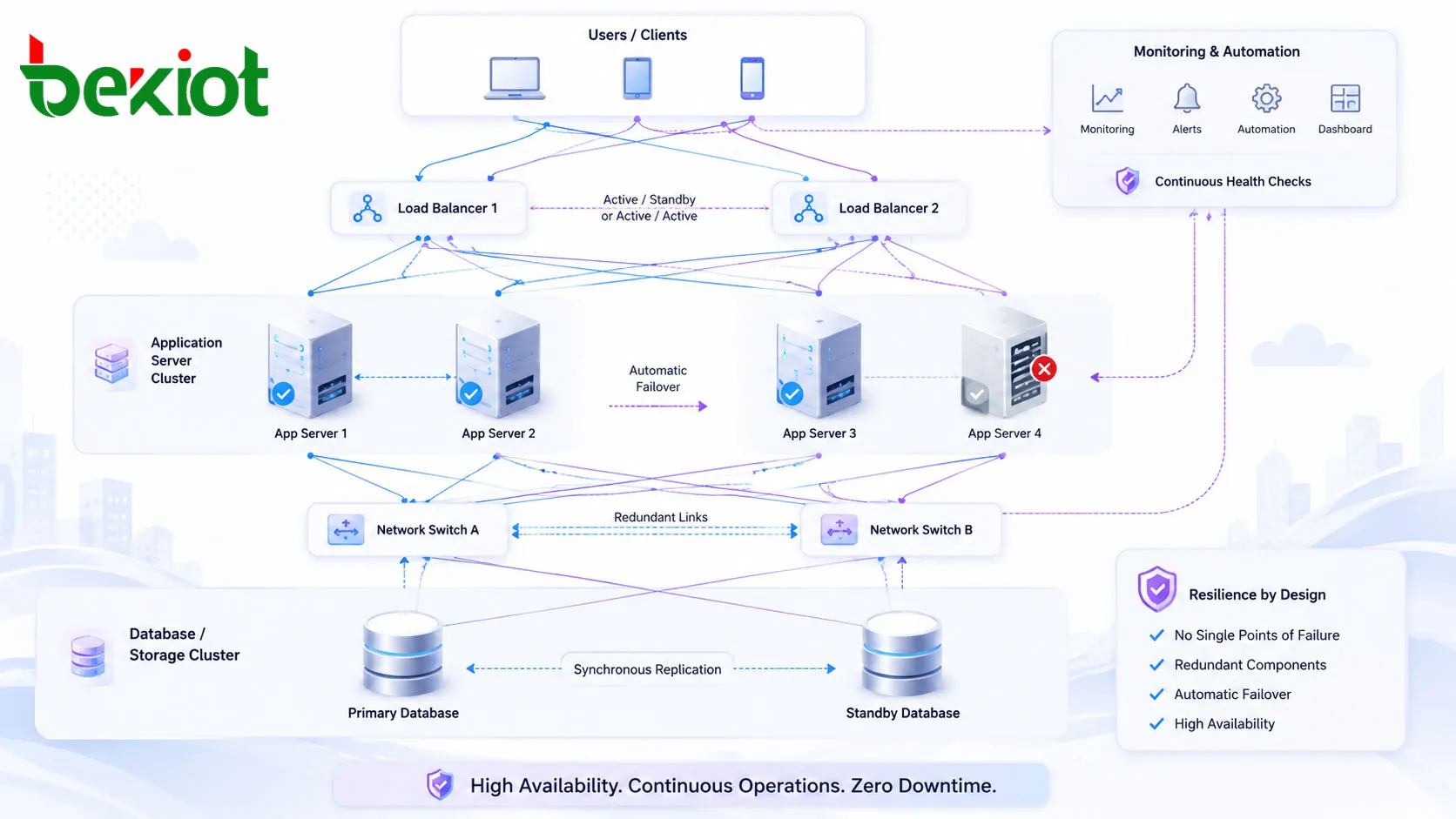
La redondance est le fondement de la haute disponibilité. Les composants importants sont dupliqués afin qu'un autre composant puisse prendre le relais si celui qui est actif tombe en panne. Cette redondance peut inclure de multiples serveurs, des nœuds applicatifs en cluster, du stockage en miroir, des bases de données répliquées, des alimentations doubles, des routeurs de secours, des commutateurs redondants, plusieurs connexions Internet et des instances de service dupliquées sur différents sites géographiques.
Une redondance efficace doit couvrir le chemin de service réel. Deux serveurs d'application n'offrent pas une protection totale s'ils dépendent tous les deux d'une seule base de données, d'une seule baie de stockage, d'un seul pare-feu, d'un seul circuit électrique ou d'un seul fournisseur externe. La planification HA doit passer en revue chaque dépendance nécessaire au fonctionnement du service.
Basculement automatique
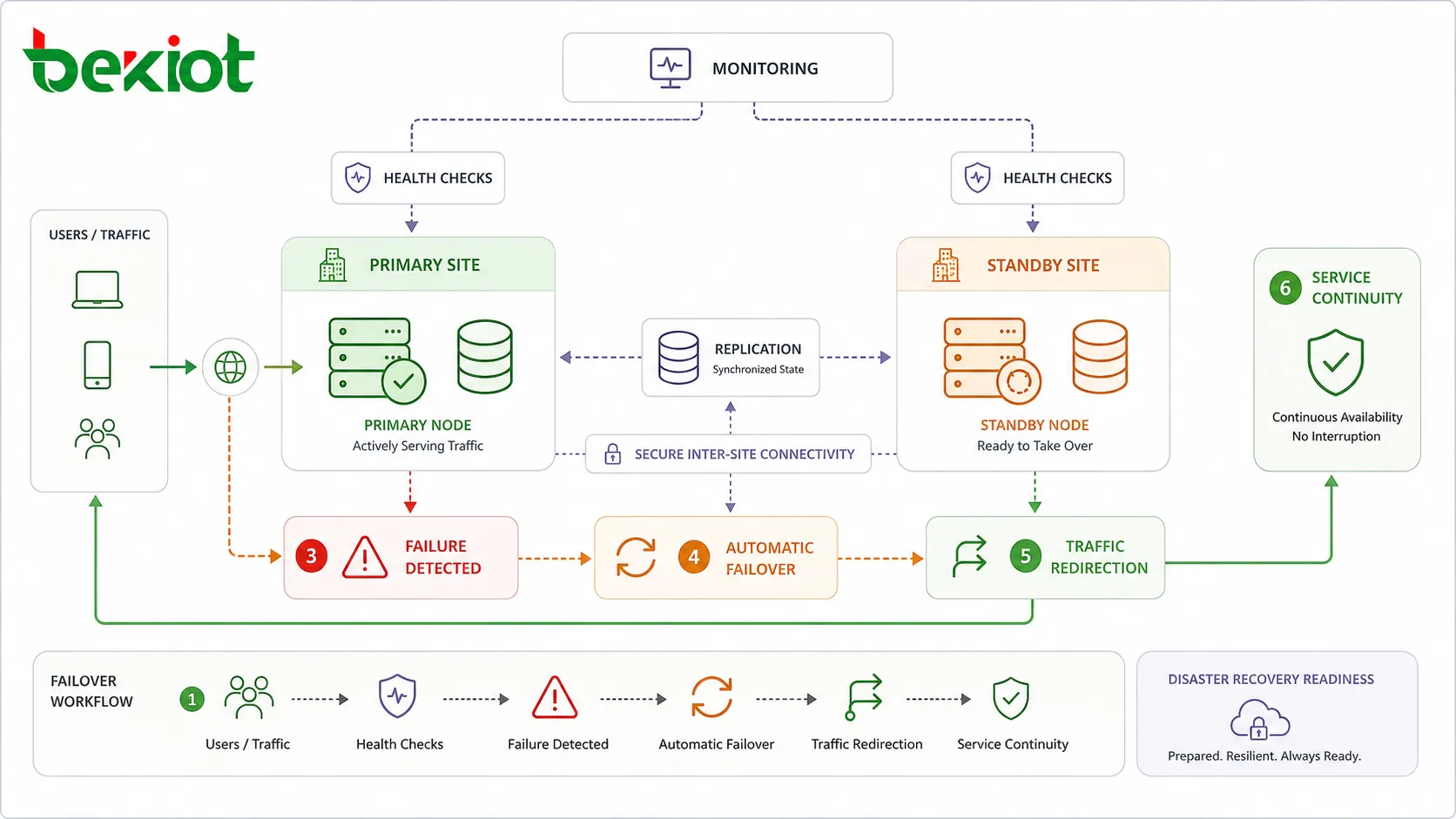
Le basculement (failover) est le processus qui consiste à transférer le service d'un composant défaillant vers un composant sain. Dans de nombreuses conceptions HA, ce processus se produit automatiquement. Par exemple, un répartiteur de charge peut retirer un serveur défaillant de la rotation, une base de données en attente peut devenir la base de données principale, ou une route réseau de secours peut prendre le relais lorsque la liaison principale est interrompue.
Le basculement automatique réduit le temps de récupération car il n'attend pas qu'un ingénieur diagnostique manuellement la panne. Cependant, la logique de basculement doit être soigneusement conçue. Si les contrôles de santé sont trop simplistes, le système peut basculer inutilement. Si les règles de basculement sont trop lentes, les utilisateurs peuvent subir une interruption plus longue que prévu.
Supervision de l'état du service
La supervision permet au système et à l'équipe d'exploitation de détecter précocement les conditions anormales. Une supervision utile couvre la santé du serveur, l'utilisation du CPU et de la mémoire, l'espace disque, le temps de réponse du service, la réplication de base de données, la latence réseau, la perte de paquets, l'aboutissement des appels, le taux de succès des transactions, l'expiration des certificats, l'état des sauvegardes et les événements de sécurité.
Les contrôles de santé les plus utiles sont reliés au comportement réel du service. Un équipement peut répondre au ping alors que l'application est gelée. Un serveur web peut être en cours d'exécution alors que la connexion à la base de données est rompue. Un serveur de communication peut être en ligne alors que le routage des appels échoue. La supervision doit confirmer si le service est effectivement utilisable.
Répartition de charge
La répartition de charge distribue le trafic sur plusieurs serveurs ou instances de service. Cela améliore les performances en fonctionnement normal et soutient la continuité en cas de panne. Si un nœud devient surchargé ou indisponible, le trafic peut être redirigé vers d'autres nœuds sains.
La répartition de charge est largement utilisée pour les sites web, les API, les applications cloud, les plateformes de communication, les services d'authentification et les systèmes internes d'entreprise. Selon la conception, elle peut prendre en charge la persistance de session, le routage géographique, le routage basé sur l'état de santé ou un pilotage de trafic sensible au contexte applicatif.
Réplication des données
De nombreux systèmes ne peuvent rester disponibles que si les données le sont aussi. La réplication des données conserve des copies des informations importantes sur plusieurs nœuds ou sites. Cela permet à un serveur, un système de stockage ou un centre de données secondaire de continuer à assurer le service si l'environnement principal tombe en panne.
La réplication peut être synchrone ou asynchrone. La réplication synchrone confirme une écriture seulement après que la donnée a été écrite à plusieurs endroits, ce qui peut améliorer la cohérence mais augmenter la latence. La réplication asynchrone est généralement plus rapide, mais une petite quantité de données récentes peut être à risque en cas de panne soudaine. Le bon choix dépend de l'équilibre souhaité entre performance, cohérence et perte de données acceptable.
Maintenance sans arrêt complet
Une bonne conception HA facilite également les opérations de maintenance planifiée. Les systèmes ont besoin de mises à jour, de correctifs de sécurité, de remplacement de matériel, de renouvellement de certificats, de modifications de configuration et d'extensions de capacité. Si l'architecture prend en charge les mises à jour progressives ou le basculement contrôlé, la maintenance peut être réalisée sans mettre hors ligne l'ensemble du service.
C'est particulièrement utile pour les services qui fonctionnent 24 heures sur 24. Plutôt que d'attendre de longues fenêtres de maintenance, les équipes peuvent mettre à jour un nœud à la fois pendant que les autres nœuds continuent de traiter le trafic de production.
Modèles d'architecture courants
Actif-Passif (Active-Standby)
Dans une conception actif-passif, un système gère le trafic de production tandis qu'un autre système reste prêt à prendre le relais. Ce modèle est souvent utilisé pour les pare-feux, les bases de données, les autocommutateurs (PBX), les passerelles, les applications industrielles et les plateformes de gestion centrales.
L'avantage de l'architecture actif-passif réside dans sa simplicité et son comportement de basculement prévisible. L'inconvénient est que les ressources en veille peuvent ne pas être pleinement utilisées pendant le fonctionnement normal. Le système en attente doit aussi être testé régulièrement pour confirmer qu'il est synchronisé et prêt.
Actif-Actif (Active-Active)
Dans une conception actif-actif, plusieurs systèmes gèrent le trafic simultanément. Si un nœud tombe en panne, les nœuds restants continuent de fonctionner et absorbent la charge de travail. Ce modèle peut améliorer à la fois la disponibilité et les performances car la capacité est utilisée en continu.
L'architecture actif-actif exige généralement une conception plus soignée. Les applications doivent gérer les sessions distribuées, la cohérence des données, le comportement de routage et les éventuels scénarios de conflit. Si le logiciel n'est pas conçu pour un fonctionnement distribué, un déploiement actif-actif peut engendrer de la complexité plutôt que de la fiabilité.
Services en cluster
Un cluster est un groupe de nœuds qui travaillent ensemble comme un seul service. Les systèmes en cluster peuvent protéger des applications, des bases de données, des machines virtuelles, des plateformes de stockage, des charges de travail conteneurisées et des services de communication. Les gestionnaires de cluster supervisent la santé des nœuds et coordonnent le basculement ou la redistribution de la charge de travail.
Un clustering stable exige une communication de pulsation (heartbeat) appropriée, des règles de quorum, des mécanismes d'isolement (fencing) et une séparation réseau. Ces contrôles permettent d'éviter les situations de split-brain, où deux nœuds croient à tort qu'ils sont tous les deux le système primaire.
Déploiement multi-sites
Pour des exigences de résilience plus élevées, les systèmes peuvent être déployés sur plusieurs sites, centres de données, zones de disponibilité cloud ou régions. Si un site devient indisponible en raison d'une panne de courant, d'une coupure réseau, d'un dommage physique ou d'un incident majeur d'infrastructure, un autre site peut assurer la continuité du service.
La conception multi-sites est plus complexe que la redondance locale. Elle nécessite un pilotage du trafic, une connectivité sécurisée, une planification de la réplication, une configuration cohérente, une coordination opérationnelle et des tests réguliers de reprise après sinistre. Elle implique aussi des règles claires pour décider quand basculer le trafic entre les sites.
Indicateurs utilisés pour mesurer la continuité de service
Pourcentage de disponibilité
Le pourcentage de disponibilité mesure la durée pendant laquelle un système reste opérationnel sur une période donnée. Il est souvent utilisé dans les accords de niveau de service (SLA) et les objectifs de fiabilité internes. Des objectifs de disponibilité plus élevés exigent une architecture plus robuste, une récupération plus rapide, une meilleure supervision et une exploitation plus rigoureuse.
Cependant, la disponibilité doit être mesurée du point de vue de l'utilisateur. Un système qui tourne techniquement mais qui est incapable de traiter des requêtes, de terminer des appels, d'accéder aux données ou de répondre dans des délais acceptables ne devrait pas être considéré comme pleinement disponible.
Objectif de durée de rétablissement (RTO)
L'objectif de durée de rétablissement (Recovery Time Objective) définit la rapidité avec laquelle un service doit être restauré après une interruption. Un RTO court exige généralement un basculement automatisé, une capacité de veille prête à l'emploi, des procédures éprouvées et une détection rapide.
Le RTO doit correspondre à l'impact métier. Tous les systèmes n'ont pas besoin d'une récupération immédiate. Certains systèmes internes peuvent tolérer une période de récupération plus longue, tandis que les services critiques peuvent nécessiter une exploitation quasi continue.
Objectif de perte de données maximale admissible (RPO)
L'objectif de perte de données maximale admissible (Recovery Point Objective) définit la quantité de perte de données acceptable après une panne. Un RPO faible exige une réplication fréquente ou continue. Un RPO plus élevé peut permettre une récupération à partir de sauvegardes planifiées.
Le RPO est crucial pour les enregistrements de transactions, les journaux d'appels, les historiques d'événements, les données de production, les informations utilisateur, les pistes d'audit et les rapports opérationnels. Si la perte de données est inacceptable, la conception de la réplication et de la sauvegarde doit être plus stricte.
Délai moyen de réparation (MTTR)
Le délai moyen de réparation (Mean Time to Repair) mesure le temps nécessaire pour rétablir un service normal après une panne. La haute disponibilité s'améliore lorsque le MTTR diminue. Une meilleure automatisation, une documentation plus claire, des opérateurs formés, des ressources de rechange et des plans de reprise testés contribuent tous à raccourcir le temps de réparation.
Réduire le temps de réparation est souvent plus réaliste que d'essayer de prévenir toutes les pannes possibles. Même les systèmes bien conçus finiront par tomber en panne, mais une organisation bien préparée pourra récupérer plus vite et avec un impact moindre sur les utilisateurs.
Applications dans des environnements réels
Plateformes cloud et applications SaaS
Les services cloud et les plateformes SaaS utilisent la conception HA pour garder les applications accessibles aux utilisateurs sur différents sites et fuseaux horaires. Les techniques courantes incluent les groupes d'auto-scaling, les répartiteurs de charge, les bases de données répliquées, le stockage objet distribué, les contrôles de santé, les régions de secours et les stratégies de déploiement progressif.
Pour les services par abonnement, la disponibilité affecte directement la fidélisation client et la réputation de la marque. Les utilisateurs ne connaissent peut-être pas les détails de l'architecture, mais ils remarquent rapidement les réponses lentes, les échecs de connexion, les données manquantes ou les interruptions de service.
Systèmes de communication d'entreprise
Les systèmes de voix, vidéo, messagerie, recherche de personnes et de dispatch exigent souvent une haute disponibilité car la communication peut être nécessaire aussi bien lors du travail courant que durant les incidents urgents. La planification HA peut inclure des serveurs d'appels redondants, des trunks SIP de secours, des passerelles secondaires, des chemins réseau résilients, des systèmes de succursale survivables et une alimentation de secours.
La disponibilité de la communication doit être testée de bout en bout. Il ne suffit pas qu'un serveur soit en ligne si les téléphones ne peuvent pas s'enregistrer, si les appels ne peuvent pas être routés, si l'audio ne traverse pas le réseau ou si les numéros d'urgence sont inaccessibles.
Opérations industrielles et énergétiques
Les sites industriels, les services publics, les mines, les ports, les plateformes de transport et les installations énergétiques dépendent souvent d'une surveillance et d'une communication continues. Dans ces environnements, la haute disponibilité peut inclure des anneaux de fibre optique redondants, des liaisons sans fil de secours, des serveurs de contrôle doubles, une capacité de survie locale, des équipements durcis et des chemins d'urgence isolés.
La conception doit tenir compte à la fois des pannes informatiques et des conditions physiques. Les environnements hostiles, les interférences électromagnétiques, l'isolement géographique, l'instabilité électrique et l'accès restreint pour la maintenance peuvent tous affecter la disponibilité.
Santé et services d'urgence
Les hôpitaux, les centres de réponse aux urgences, les agences de sécurité publique et les salles de commandement s'appuient sur des systèmes fiables pour leur coordination. La haute disponibilité peut soutenir l'accès aux informations des patients, la notification d'alarmes, la communication d'urgence, les flux de travail de dispatch, le contrôle d'accès, la vidéosurveillance et la collaboration interne.
Dans ces environnements, un temps d'arrêt n'est pas qu'un problème technique. Il peut affecter la vitesse d'intervention, la sécurité, la prise de décision et la continuité des soins. L'alimentation de secours, les réseaux redondants, les procédures d'escalade claires et les exercices réguliers y sont particulièrement importants.
Finance, distribution et transactions en ligne
Les banques, les processeurs de paiement, les plateformes de trading et les boutiques en ligne exigent des systèmes fiables pour protéger les transactions et l'accès des clients. Même de courtes interruptions peuvent entraîner des échecs de paiement, des pertes de ventes, des retards de commande, des problèmes de règlement ou des réclamations clients.
Ces systèmes combinent souvent la planification de la disponibilité avec une sécurité forte, la journalisation d'audit, la surveillance des fraudes, le chiffrement et des contrôles de conformité. La continuité de service doit être conçue conjointement avec l'intégrité des données et la gestion des risques.
Considérations de conception avant le déploiement
Cartographier la chaîne complète des dépendances
La première étape consiste à comprendre comment le service fonctionne concrètement. Les équipes doivent cartographier les applications, les bases de données, les réseaux, le stockage, l'authentification, le DNS, les pare-feux, les services tiers, les certificats, les outils de supervision et les responsabilités opérationnelles. Cela aide à identifier les dépendances cachées qui pourraient devenir des points de défaillance uniques.
Une cartographie de service aide également les équipes à décider quels composants nécessitent une redondance et quels risques peuvent être acceptés. Chaque dépendance n'exige pas le même niveau de protection, mais chaque dépendance critique doit être visible.
Fixer des objectifs de récupération réalistes
Les objectifs de disponibilité doivent être fondés sur les besoins métier, pas sur un discours marketing. Une plateforme de mission critique peut justifier une redondance coûteuse et une réplication quasi temps réel. Un outil de reporting peu prioritaire peut se contenter d'une sauvegarde planifiée et d'une récupération manuelle.
Des objectifs RTO et RPO clairs aident les équipes à choisir la bonne architecture. Ils évitent aussi de sur-dimensionner des systèmes qui n'ont pas besoin d'une protection avancée, ou de sous-protéger des services essentiels aux opérations.
Tester le basculement en conditions contrôlées
Un plan de basculement n'a de valeur que s'il fonctionne au moment voulu. Les tests contrôlés vérifient si la supervision détecte la panne, si les ressources en veille s'activent correctement, si le trafic est redirigé comme prévu, si les données restent cohérentes et si les utilisateurs peuvent continuer à travailler.
Les tests doivent inclure le basculement planifié, la simulation de défaillance de nœud, l'isolement réseau, la restauration de sauvegarde, la reprise de base de données et les procédures de retour en arrière. Les résultats doivent être documentés pour que les améliorations futures s'appuient sur des preuves et non des suppositions.
Maîtriser les changements de configuration
De nombreuses pannes sont causées par des erreurs humaines plutôt que par des défaillances matérielles. Des règles de pare-feu incorrectes, des certificats expirés, des mises à jour incompatibles, des modifications de routage erronées, des erreurs de permissions de base de données et des incohérences de configuration peuvent toutes interrompre le service.
Le contrôle des changements, la gestion des versions, les flux de validation, les environnements de test, les plans de retour arrière et les sauvegardes de configuration réduisent ce risque. Dans les environnements HA, les systèmes primaire et de veille doivent rester alignés.
Défis et limites
La haute disponibilité réduit les temps d'arrêt, mais elle ne rend pas un système invulnérable aux pannes. Les bogues logiciels, les rançongiciels, les erreurs de configuration, la corruption de données, les pannes de dépendances, les catastrophes régionales et les erreurs d'exploitation peuvent toujours perturber le service. La HA doit s'intégrer à la sauvegarde, à la cybersécurité, à la reprise après sinistre, à l'observabilité et à la réponse aux incidents.
Le coût représente un autre défi. Une architecture redondante peut exiger plus de serveurs, d'équipements réseau, de ressources cloud, de licences, de systèmes de supervision, de capacité de stockage et d'expertise opérationnelle. Plus l'objectif de disponibilité est élevé, plus il devient important de justifier l'investissement.
La complexité peut aussi devenir un risque. Une conception HA trop compliquée que l'équipe d'exploitation ne comprend pas risque d'échouer au moment d'un incident. Une haute disponibilité pratique doit être documentée, testable et gérable par les personnes chargées de l'exécuter.
La meilleure stratégie de disponibilité n'est pas toujours la plus complexe. C'est celle qui protège les services les plus importants, qui peut être testée régulièrement et qui peut être exploitée avec confiance durant les incidents réels.
Bonnes pratiques pour une fiabilité à long terme
Commencez par la classification des services. Identifiez quels systèmes sont critiques pour la mission, lesquels sont importants pour l'activité, et lesquels peuvent tolérer une récupération plus longue. Cela permet de concentrer les ressources là où les temps d'arrêt ont le plus d'impact.
Utilisez une supervision qui reflète les résultats réels des utilisateurs. Au lieu de vérifier uniquement l'état des équipements, supervisez si les utilisateurs peuvent se connecter, passer des appels, accéder aux dossiers, soumettre des formulaires, recevoir des alertes ou finaliser des transactions. Cela donne une image plus fidèle de la santé du service.
Maintenez la documentation à jour. Les schémas d'architecture, les étapes de basculement, les listes de contacts, les chemins d'escalade, les emplacements de sauvegarde, la gestion des identifiants et les procédures de retour arrière doivent être mis à jour après chaque changement majeur. En cas d'incident, une documentation obsolète peut retarder la récupération.
Révisez l'architecture régulièrement. Le volume de trafic, les versions logicielles, les exigences de sécurité, les dépendances tierces et les priorités métier évoluent avec le temps. Un système qui atteignait les objectifs de disponibilité par le passé peut nécessiter une refonte à mesure que l'usage et les risques augmentent.
Conclusion
La haute disponibilité est une méthode pragmatique pour maintenir l'accès aux services importants lorsque des pannes surviennent. Elle combine une infrastructure redondante, un basculement automatique, une supervision de l'état, une répartition de charge, une réplication des données, une planification de la maintenance et des procédures de récupération éprouvées. Sa valeur est particulièrement évidente lorsque les interruptions affectent la sécurité, le chiffre d'affaires, la communication, la production, la conformité ou la confiance des clients.
Une stratégie HA réussie ne consiste pas simplement à ajouter plus d'équipements. Elle exige de comprendre la chaîne de service complète, d'identifier les points de défaillance uniques, de fixer des objectifs de récupération réalistes, de tester le basculement, et de trouver un équilibre entre fiabilité, coût et complexité. Lorsqu'elle est conçue correctement, la haute disponibilité aide les organisations à bâtir des systèmes qui restent fiables dans des conditions réelles.
FAQ
Un système hautement disponible peut-il quand même perdre des données ?
Oui. La disponibilité et la protection des données sont liées mais distinctes. Si la réplication est différée ou si les politiques de sauvegarde sont faibles, un service peut redémarrer rapidement tout en perdant des données récentes. Une planification du RPO est nécessaire pour maîtriser ce risque.
La haute disponibilité est-elle identique à la tolérance aux pannes ?
Non. La tolérance aux pannes signifie généralement qu'un système continue de fonctionner avec peu ou pas d'interruption même en cas de défaillance d'un composant. La haute disponibilité se concentre sur la réduction du temps d'arrêt, mais un bref délai de basculement peut toujours se produire selon l'architecture.
Les petites entreprises devraient-elles utiliser la haute disponibilité ?
Oui, mais la conception doit correspondre à l'impact métier. Une petite entreprise n'a peut-être pas besoin d'une architecture multi-régions, mais elle peut néanmoins bénéficier de liaisons Internet redondantes, de sauvegardes fiables, d'un basculement basé sur le cloud, de services supervisés et d'une alimentation de secours pour les systèmes critiques.
La haute disponibilité peut-elle protéger contre les cyberattaques ?
Seulement en partie. La HA peut aider à maintenir le service si un nœud est isolé ou restauré, mais elle ne remplace pas les contrôles de cybersécurité. Les rançongiciels, le vol d'identifiants, les attaques DDoS et l'altération de données exigent une surveillance de sécurité, un contrôle d'accès, l'application de correctifs, l'isolement des sauvegardes et une réponse aux incidents.
Toutes les applications supportent-elles le déploiement actif-actif ?
Non. Certaines applications ne sont pas conçues pour les sessions distribuées, l'état partagé ou les écritures multi-nœuds. Avant de choisir une architecture actif-actif, les équipes doivent confirmer que le logiciel, la base de données, le modèle de licence et la conception réseau peuvent la supporter en toute sécurité.