HTTP, ou protocole de transfert hypertexte, est le protocole de couche application utilisé pour transférer des pages web, des données d’API, des fichiers, des formulaires, des images, des scripts et d’autres ressources entre clients et serveurs. Il constitue la base du World Wide Web et l’un des protocoles de communication les plus utilisés dans les systèmes Internet modernes.
Lorsqu’un utilisateur ouvre un site web, clique sur un lien, soumet un formulaire, charge une image ou appelle une API, HTTP définit comment le client demande une ressource et comment le serveur répond. Le protocole lui-même ne décide pas de l’apparence d’une page ni du comportement d’une application. Son rôle principal est de fournir une méthode de communication structurée entre deux parties.
Une conversation requête-réponse
Le principe de base est simple : un client envoie une requête, et un serveur renvoie une réponse. Le client est généralement un navigateur web, une application mobile, une application de bureau, un outil d’API, un robot d’exploration ou un appareil embarqué. Le serveur est le système qui héberge la ressource ou le service demandé.
Par exemple, lorsqu’un navigateur visite un site web, il envoie une requête pour demander une page précise. Le serveur reçoit la requête, vérifie la ressource demandée, applique les règles associées, puis renvoie une réponse contenant le contenu, les informations d’état et les métadonnées.
Ce modèle s’appelle communication requête-réponse. Le client lance l’échange et le serveur répond. Chaque échange est structuré afin que les deux côtés comprennent ce qui est demandé, comment cela doit être traité et quel résultat est renvoyé.

Avant le déplacement du premier octet
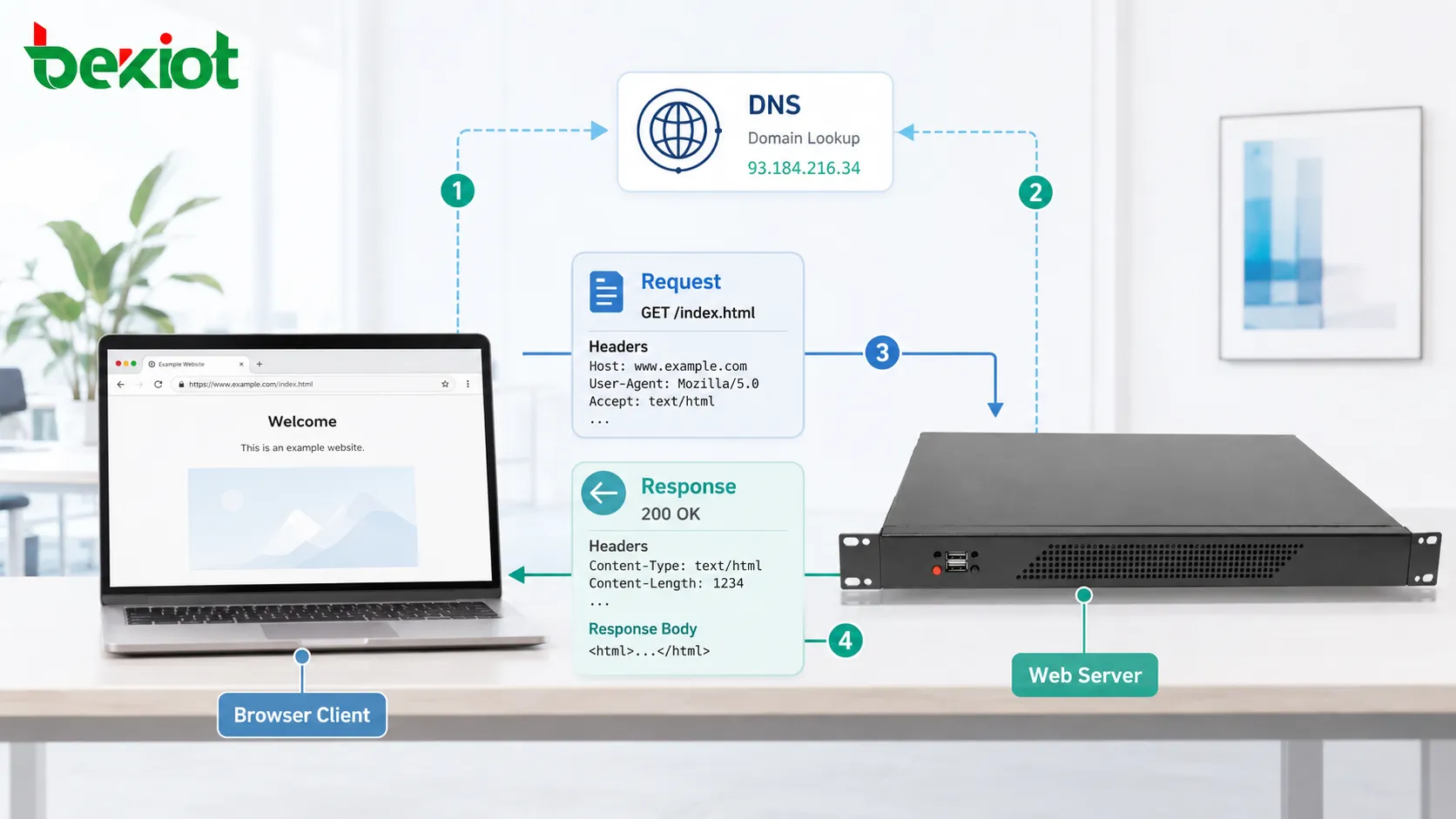
Avant qu’une requête HTTP puisse atteindre le serveur, le client doit savoir où l’envoyer. Lorsqu’un utilisateur saisit un nom de domaine, le navigateur effectue généralement d’abord une résolution DNS. Le DNS traduit le nom de domaine lisible par l’humain en adresse IP.
Ensuite, le client établit une connexion réseau avec le serveur. Avec HTTP traditionnel sur TCP, cela signifie ouvrir une connexion TCP. Avec HTTPS, une négociation TLS est également effectuée afin que la communication puisse être chiffrée et authentifiée.
Ce n’est qu’après ces étapes que le véritable message HTTP peut être échangé. Cela signifie que le chargement d’une page web ne dépend pas seulement du message du protocole. Il dépend aussi du DNS, de la connexion de transport, du chiffrement, de la disponibilité du serveur, du routage et des performances réseau.
Anatomie d’une requête client
Une requête HTTP contient généralement une méthode, un chemin cible, une version, des en-têtes et parfois un corps de message. La méthode explique l’action prévue. Le chemin identifie la ressource. Les en-têtes fournissent des informations supplémentaires. Le corps transporte les données soumises lorsque c’est nécessaire.
Une requête simple peut demander une page d’accueil. Une requête plus complexe peut soumettre des identifiants de connexion, téléverser un fichier, envoyer des données JSON à une API ou demander une ressource mise en cache uniquement si elle a changé.
Les méthodes de requête courantes incluent GET, POST, PUT, PATCH, DELETE, HEAD et OPTIONS. Chaque méthode a un sens différent et doit être utilisée selon le but de l’opération.
GET est couramment utilisé pour récupérer des données. POST sert souvent à soumettre des données. PUT et PATCH servent à mettre à jour des ressources. DELETE sert à demander une suppression. HEAD demande les en-têtes de réponse sans le corps complet. OPTIONS vérifie les options de communication prises en charge.
Comment le serveur interprète le message
Après avoir reçu la requête, le serveur lit la méthode, le chemin, les en-têtes, le corps, les cookies, les données d’authentification et les règles de routage. Il décide ensuite de ce qui doit se passer.
Si la requête vise un fichier statique, le serveur peut renvoyer directement le fichier. Si elle vise une page dynamique ou un point de terminaison d’API, le serveur peut appeler du code applicatif, interroger une base de données, vérifier les droits de l’utilisateur, exécuter une logique métier ou communiquer avec un autre service.
Le serveur peut aussi appliquer des règles de sécurité avant de renvoyer quoi que ce soit. Il peut vérifier si la requête est authentifiée, si l’utilisateur a l’autorisation, si la requête est mal formée, si la source est bloquée ou si les limites de débit ont été dépassées.
Le résultat final est encapsulé dans une réponse HTTP.
Structure et signification de la réponse
Une réponse HTTP contient généralement un code d’état, des en-têtes et un corps facultatif. Le code d’état indique au client si la requête a réussi, échoué, été redirigée ou nécessite une action supplémentaire.
Les en-têtes décrivent la réponse. Ils peuvent inclure le type de contenu, la longueur du contenu, les règles de cache, les cookies, les informations serveur, la méthode de compression, la politique de sécurité et l’emplacement de redirection.
Le corps contient le contenu réellement renvoyé. Il peut s’agir de HTML, JSON, XML, données d’image, segments vidéo, fichiers texte, feuilles de style, scripts ou téléchargements binaires.
Un navigateur utilise le corps et les en-têtes de réponse pour décider quoi afficher, quoi mettre en cache, quoi exécuter, quoi télécharger et si des requêtes supplémentaires sont nécessaires.
Les codes d’état comme des feux de circulation
Les codes d’état aident les clients à comprendre rapidement le résultat. Ils sont regroupés par catégorie.
| Plage de codes | Signification générale | Exemple d’utilisation |
|---|---|---|
| 100-199 | Réponse informative | Poursuite du traitement ou notification au niveau du protocole |
| 200-299 | Réponse réussie | Page chargée, API ayant renvoyé des données, fichier livré |
| 300-399 | Redirection | Ressource déplacée ou client devant demander une autre URL |
| 400-499 | Erreur côté client | Mauvaise requête, accès non autorisé, ressource manquante |
| 500-599 | Erreur côté serveur | Échec d’application, erreur de passerelle, surcharge serveur |
Une réponse 200 signifie généralement que la requête a réussi. Une réponse 301 ou 302 signifie que le client doit se rendre à un autre emplacement. Une réponse 404 signifie que la ressource demandée est introuvable. Une réponse 500 signifie que le serveur a rencontré un problème interne.
Les codes d’état ne servent pas seulement aux navigateurs. Les clients d’API, systèmes de supervision, robots d’exploration, proxys et équilibreurs de charge les utilisent aussi pour prendre des décisions.
Les en-têtes portent le contexte
Les en-têtes sont des champs clé-valeur qui fournissent le contexte de l’échange. Ils aident les deux côtés à décrire le format des données, la préférence linguistique, la compression, l’authentification, le comportement de cache, les cookies, le comportement de connexion et les exigences de sécurité.
Par exemple, l’en-tête Accept peut indiquer au serveur les types de contenu préférés par le client. L’en-tête Content-Type indique au destinataire le format utilisé par le corps. L’en-tête Authorization peut transporter des identifiants ou des jetons. L’en-tête Cache-Control définit le comportement de cache.
Les en-têtes rendent le protocole flexible. Le même modèle requête-réponse peut prendre en charge des sites web, des API, des téléchargements de fichiers, des segments de streaming, des flux d’authentification et des intégrations de services, car les en-têtes ajoutent des instructions sans modifier la structure de base du message.
Conception sans état et gestion de session
HTTP est souvent décrit comme sans état. Cela signifie que chaque requête est indépendante par défaut. Le serveur ne mémorise pas automatiquement les requêtes précédentes dans le modèle de base du protocole.
Cependant, la plupart des sites web et applications réels ont besoin d’un comportement de session. Les utilisateurs se connectent, ajoutent des articles à un panier, changent des paramètres et poursuivent des flux de travail sur de nombreuses requêtes. Pour cela, les systèmes utilisent cookies, identifiants de session, jetons, stockage local, sessions côté serveur et en-têtes d’authentification.
Le protocole reste basé sur des requêtes, mais les applications construisent une continuité par-dessus. C’est pourquoi un site web peut se souvenir d’un utilisateur alors que l’échange sous-jacent reste composé de requêtes et réponses séparées.
Identification des ressources avec les URL
Une URL indique au client où se trouve une ressource et comment la demander. Elle inclut généralement un schéma, un hôte, un chemin, une chaîne de requête et parfois un port ou un fragment.
Le schéma peut être http ou https. L’hôte identifie le domaine. Le chemin pointe vers une ressource ou une route spécifique. La chaîne de requête transporte des paramètres supplémentaires. Le fragment est généralement traité côté client et n’a pas besoin d’être envoyé au serveur de la même manière que le chemin principal.
Les URL rendent les ressources web adressables. Elles permettent aux navigateurs, API, moteurs de recherche, applications et utilisateurs de référencer des ressources dans un format cohérent.
Ce qui se passe quand une page web se charge
Le chargement d’une seule page peut impliquer de nombreux échanges HTTP. La première requête peut récupérer le document HTML principal. Après avoir lu ce document, le navigateur découvre des ressources supplémentaires comme fichiers CSS, JavaScript, images, polices, icônes, scripts d’analyse, appels API et fichiers multimédias.
Chaque ressource peut nécessiter une autre requête. Certaines ressources peuvent provenir du même serveur, tandis que d’autres peuvent provenir de CDN, de services tiers, de systèmes publicitaires, de fournisseurs de cartes ou de passerelles API.
Le navigateur combine ensuite les ressources reçues, construit la structure de la page, applique les styles, exécute les scripts et rend l’interface visuelle finale. C’est pourquoi une page web peut nécessiter des dizaines, voire des centaines, d’échanges de protocole derrière une seule action visible.
Mise en cache et amélioration des performances
La mise en cache permet aux clients, navigateurs, proxys, CDN et serveurs de réutiliser des ressources déjà téléchargées lorsque c’est approprié. Cela réduit les transferts répétés, diminue la latence, économise la bande passante et améliore l’expérience utilisateur.
Le comportement de cache est contrôlé par des en-têtes comme Cache-Control, ETag, Last-Modified et Expires. Ces en-têtes aident à déterminer si une ressource peut être réutilisée, doit être revalidée ou doit être téléchargée à nouveau.
Pour les fichiers statiques comme images, scripts et feuilles de style, le cache peut réduire fortement le temps de chargement. Pour les données dynamiques, il faut l’utiliser avec prudence, car un contenu obsolète peut produire des résultats incorrects.
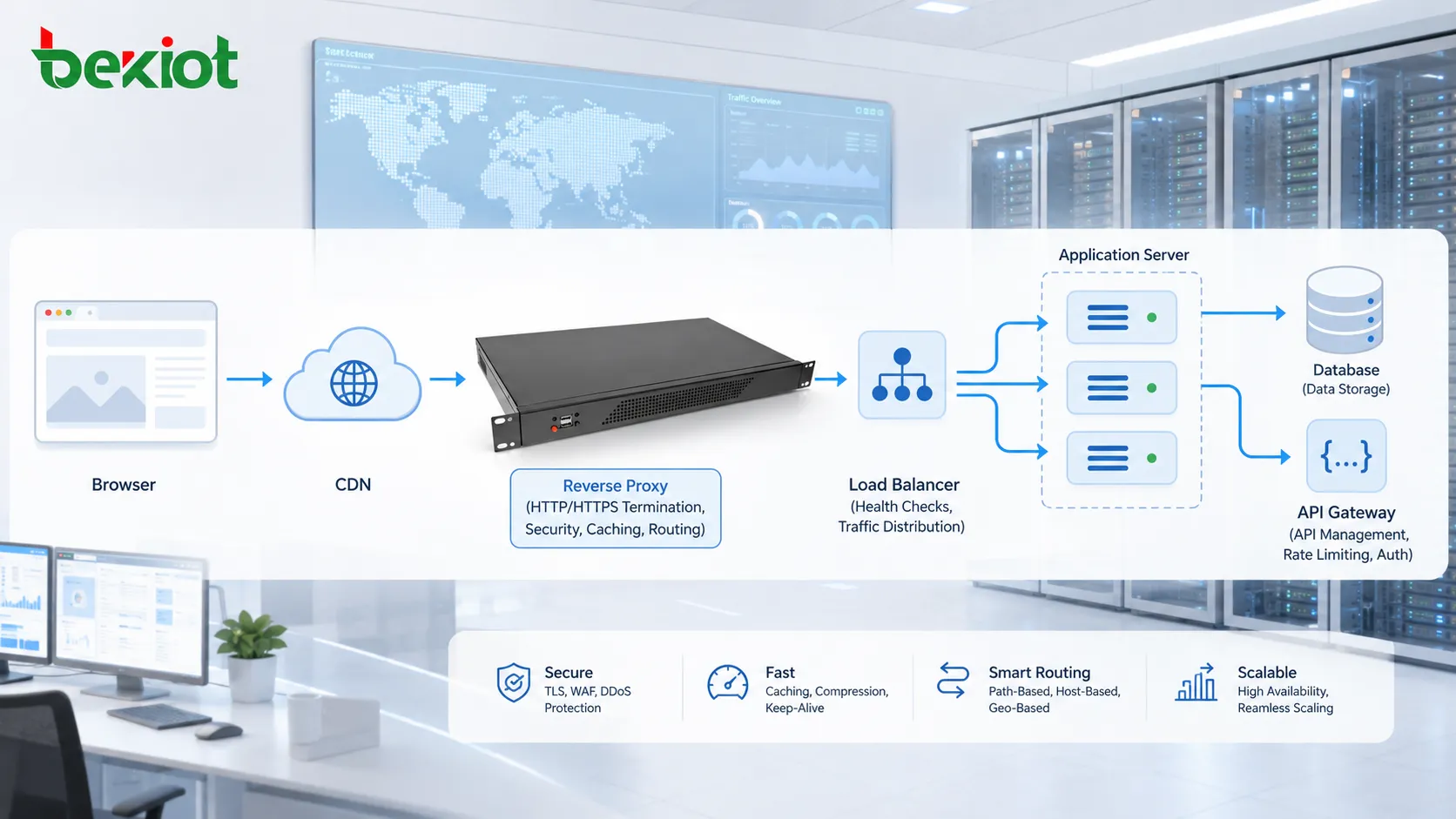
Rôle des proxys, passerelles et CDN
Le trafic HTTP ne va pas toujours directement du navigateur au serveur d’origine. Il peut traverser des proxys inverses, proxys directs, passerelles API, équilibreurs de charge, pare-feu, nœuds CDN en périphérie ou systèmes d’inspection de sécurité.
Un proxy inverse peut recevoir des requêtes au nom de serveurs backend. Un équilibreur de charge peut distribuer le trafic entre plusieurs serveurs applicatifs. Un CDN peut mettre le contenu en cache plus près des utilisateurs. Une passerelle API peut vérifier des jetons, limiter les débits de requête, transformer les en-têtes ou router le trafic vers des microservices.
Ces systèmes intermédiaires améliorent l’évolutivité, la sécurité, les performances et la gestion. Ils rendent aussi le dépannage plus complexe, car les erreurs peuvent se produire à différentes couches.
HTTPS et communication sécurisée
HTTPS est HTTP transporté sur un chiffrement TLS. Il protège les données en transit en chiffrant la communication entre le client et le serveur. Il aide aussi à vérifier l’identité du serveur au moyen de certificats numériques.
Sans chiffrement, des informations sensibles comme mots de passe, jetons, données personnelles et cookies de session pourraient être exposées à des attaquants sur le réseau. HTTPS réduit ce risque et est devenu la norme pour les sites web et API modernes.
La communication sécurisée dépend aussi d’une configuration correcte des certificats, de versions de protocole robustes, de cookies sécurisés, de redirections appropriées et de paramètres serveur sûrs. HTTPS est essentiel, mais il doit être correctement configuré.
Évolution des versions du protocole
HTTP a évolué pour améliorer les performances et l’efficacité. Les premières versions utilisaient une gestion plus simple des requêtes. Les versions ultérieures ont introduit connexions persistantes, multiplexage, compression des en-têtes, concepts de server push et comportement de transport amélioré.
HTTP/1.1 a amélioré la réutilisation des connexions et a été largement déployé. HTTP/2 a introduit le multiplexage, permettant à plusieurs requêtes et réponses de partager plus efficacement une même connexion. HTTP/3 utilise QUIC sur UDP pour améliorer l’établissement de connexion et réduire certains problèmes de latence dans certaines conditions réseau.
Le principe de fonctionnement reste la communication requête-réponse, mais les mécanismes de transport et de performance sont devenus plus avancés.
API et communication machine à machine
HTTP n’est pas utilisé seulement par les navigateurs. C’est aussi le style de protocole dominant pour de nombreuses API. Applications mobiles, applications web, plateformes IoT, services cloud, systèmes de paiement, outils de supervision et systèmes d’entreprise échangent souvent des données JSON ou XML via HTTP.
Dans la communication API, le corps de réponse peut ne pas être une page HTML. Il peut s’agir de données structurées destinées à être traitées par un autre programme. Codes d’état, en-têtes, jetons d’authentification et méthodes de requête deviennent particulièrement importants pour une intégration prévisible.
C’est pourquoi les développeurs doivent comprendre à la fois le modèle de base et les conventions pratiques utilisées dans la conception d’API.
Problèmes courants et leurs causes
Une page lente peut être causée par un délai DNS, de gros fichiers, un mauvais cache, une surcharge serveur, une latence de base de données, une congestion réseau, trop de requêtes ou des scripts inefficaces.
Une erreur 404 peut indiquer un fichier manquant, une mauvaise URL, une route supprimée, une règle de réécriture incorrecte ou un lien cassé. Une erreur 500 peut pointer vers une défaillance du code serveur, un problème de base de données, un problème d’autorisation ou un service backend mal configuré.
Les échecs d’authentification peuvent impliquer des jetons expirés, des cookies manquants, de mauvais identifiants, des paramètres cross-origin bloqués ou une mauvaise gestion des en-têtes.
Comprendre le chemin requête-réponse aide à localiser l’endroit où le problème se produit.
Méthode pratique de dépannage
Commencez par vérifier l’URL et la méthode de requête. Inspectez ensuite le code d’état. Puis examinez les en-têtes de requête, les en-têtes de réponse, les cookies et le corps de réponse. Les outils de développement du navigateur sont utiles pour ce processus.
Pour les problèmes côté serveur, vérifiez journaux d’accès, journaux d’erreurs, journaux applicatifs, journaux du proxy inverse et état des services backend. Dans les systèmes distribués, les identifiants de trace et de requête aident à suivre une requête à travers plusieurs services.
Pour les problèmes de performance, vérifiez temps DNS, temps de connexion, temps TLS, temps de réponse serveur, temps de téléchargement du contenu, comportement de cache et taille des ressources. Ces détails révèlent si le problème est lié au réseau, au serveur ou au frontend.
Pourquoi le modèle reste important
Le principe de fonctionnement de HTTP reste important parce que presque tous les services numériques modernes en dépendent. Sites web, API, applications mobiles, tableaux de bord cloud, plateformes de gestion, systèmes de paiement, services de connexion, systèmes de supervision et plateformes IoT utilisent tous la même idée de base : demander, traiter, répondre.
Sa force vient de sa simplicité, de son extensibilité, de sa lisibilité et de sa large compatibilité. Il peut transporter de nombreux types de contenu et prendre en charge de nombreux types d’applications tout en conservant une structure de communication cohérente.
En même temps, une bonne conception exige de prêter attention à la sécurité, au cache, aux en-têtes, aux codes d’état, à la gestion des erreurs, à la compatibilité des versions et à l’architecture réseau.
Résumé
HTTP fonctionne en permettant à un client d’envoyer une requête structurée à un serveur et de recevoir une réponse structurée. Autour de ce modèle simple, les systèmes web modernes ajoutent DNS, TLS, cache, proxys, CDN, API, authentification, optimisation des performances et contrôles de sécurité.
Questions fréquentes
HTTP est-il identique à HTTPS ?
Non. HTTP définit le modèle d’échange de messages, tandis que HTTPS ajoute le chiffrement TLS et la vérification d’identité par certificat pour protéger la communication en transit.
Pourquoi une page web déclenche-t-elle de nombreuses requêtes ?
Une page dépend généralement de fichiers séparés comme images, scripts, feuilles de style, polices, appels API et ressources multimédias. Le navigateur demande ces ressources après avoir lu le document principal.
HTTP peut-il être utilisé sans navigateur ?
Oui. Applications mobiles, serveurs, outils en ligne de commande, appareils IoT, systèmes de supervision et API peuvent tous utiliser HTTP sans navigateur web traditionnel.
Pourquoi certains appels API renvoient-ils des données au lieu de pages web ?
Les API renvoient souvent des données structurées comme JSON ou XML. Le programme destinataire traite ces données au lieu de les afficher comme une page web.
Que faut-il vérifier en premier lorsqu’une requête HTTP échoue ?
Vérifiez l’URL, la méthode de requête, le code d’état, les en-têtes, l’état d’authentification, la connexion réseau, les journaux serveur et si un proxy ou une passerelle modifie la requête.