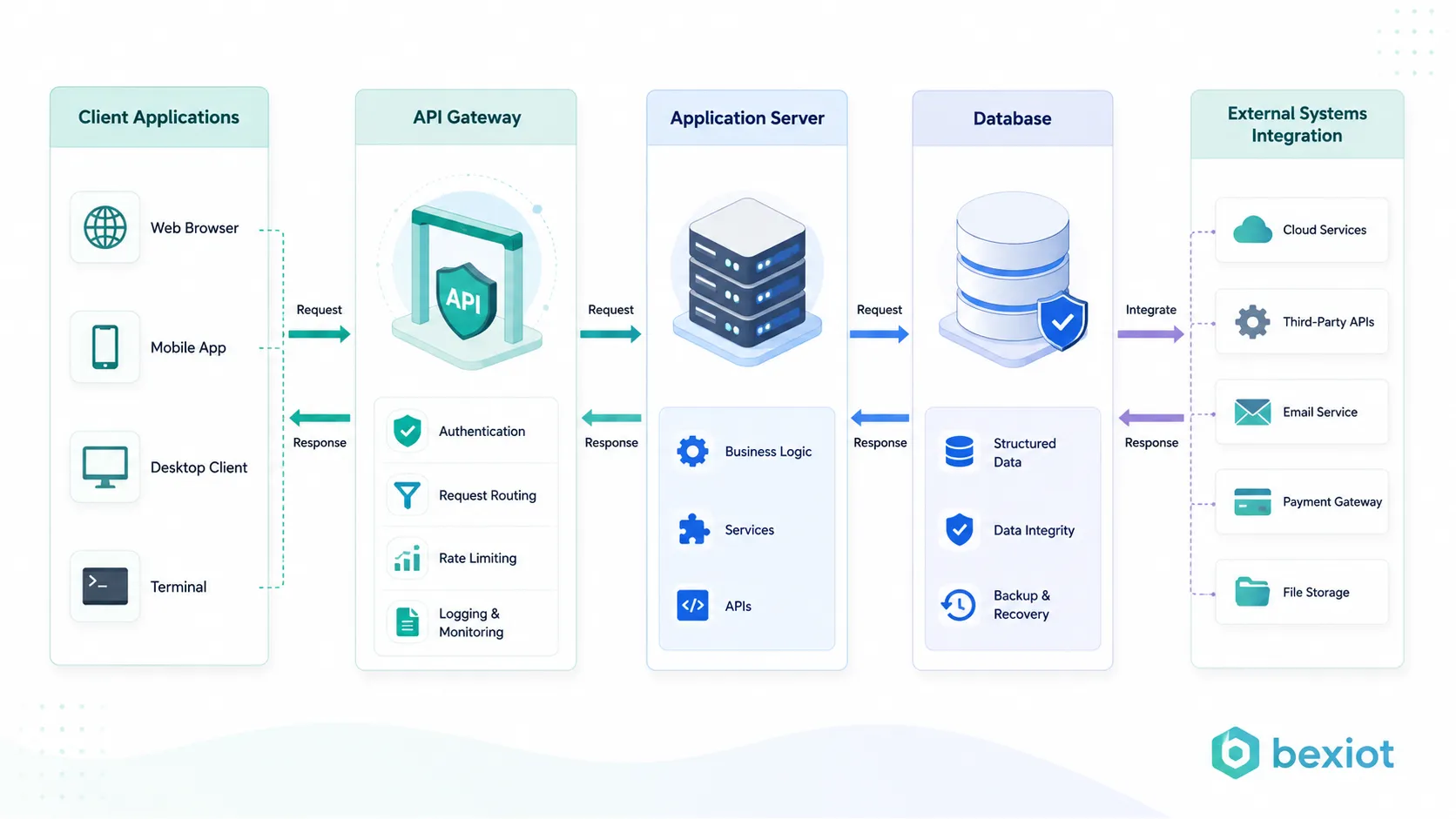
Un workflow de commandement d’urgence est un processus structuré qui aide une organisation à transformer un incident inattendu en réponse coordonnée. Il définit la réception des alarmes, la vérification des informations, l’envoi des ressources, la communication des équipes terrain et la clôture de l’événement après analyse. Pour la sécurité publique, les sites industriels, les campus, les transports, les services publics, les hôpitaux, les bâtiments commerciaux et les grandes installations, un workflow bien conçu réduit le risque lié aux décisions tardives.
Un workflow de commandement n’est pas seulement une liste de contrôle. C’est le chemin opérationnel qui relie personnes, équipements, communications, cartes, vidéo, alarmes et ressources terrain sous forte pression.
Pourquoi un processus de réponse clair est important
Pendant une urgence, les équipes doivent souvent gérer des informations incomplètes, des conditions changeantes, un temps limité et plusieurs canaux de communication. Sans processus clair, les rapports peuvent être répétés, des détails essentiels peuvent être manqués et les intervenants peuvent recevoir des consignes contradictoires. Cela ralentit la décision et augmente l’incertitude opérationnelle.
Un processus clair donne aux dispatchers, superviseurs, équipes de sécurité, techniciens de maintenance et intervenants une méthode commune. Chaque rôle comprend ce qui doit arriver en premier, qui doit être informé, quel canal utiliser et à quel moment l’incident doit être escaladé.
Du signal d’incident à l’action coordonnée
Le workflow commence généralement par un signal d’incident. Il peut provenir d’un appel d’urgence, d’un bouton panique, d’une alarme incendie, d’un événement de contrôle d’accès, d’une analyse CCTV, d’un capteur, d’une patrouille, d’une hotline publique, d’un message radio ou d’un signalement manuel sur site. La première tâche consiste à capter ce signal rapidement et à l’acheminer vers le bon poste de commandement.
Après réception du signal, le centre de commandement doit vérifier ce qui s’est passé, localiser l’événement, évaluer sa gravité et sélectionner le plan de réponse approprié. Cette transformation du signal brut en action organisée est la base de la gestion du commandement d’urgence.
Étape un : détection et prise en charge de l’incident
La première étape consiste à recevoir et enregistrer l’incident. Dans un environnement moderne, l’admission peut impliquer des téléphones d’urgence, des interphones SIP, des canaux radio, des systèmes de sonorisation, des centrales d’alarme, de la vidéo, des capteurs IoT, le contrôle d’accès et des outils mobiles de signalement.
L’admission ne consiste pas seulement à répondre à un appel ou à voir une alarme. Le centre doit collecter le type d’incident, le lieu, l’heure, la source, l’identité du déclarant si elle est disponible, le niveau de priorité et toute menace immédiate. Ces informations aident le dispatcher à distinguer un événement de routine, urgent, critique ou lié à la sécurité des personnes.
Collecte d’événements multi-sources
Les événements d’urgence proviennent rarement d’une seule source. Un accident dans un tunnel peut déclencher presque simultanément des alertes CCTV, des appels d’urgence, des alarmes incendie et des messages radio. Un incident de sécurité sur un campus peut combiner données d’accès, boutons panique, appels vocaux et retours de patrouille.
Pour cette raison, les systèmes de commandement doivent prendre en charge la collecte multi-source. Lorsque les signaux sont affichés ensemble, les opérateurs comprennent la situation plus vite et évitent de traiter des signaux liés comme des incidents séparés.
Classification initiale
Après l’admission, l’incident doit être classé. Les catégories courantes incluent incendie, urgence médicale, intrusion, panne d’équipement, accident de circulation, alarme gaz dangereux, personne bloquée dans un ascenseur, mouvement de foule, risque environnemental ou panne de communication.
La classification aide le centre à appliquer la règle de réponse correcte. Par exemple, une alarme incendie peut nécessiter une diffusion d’évacuation et la notification de l’équipe incendie, tandis qu’une alarme de maintenance peut demander l’envoi d’un technicien et l’isolement de l’équipement.
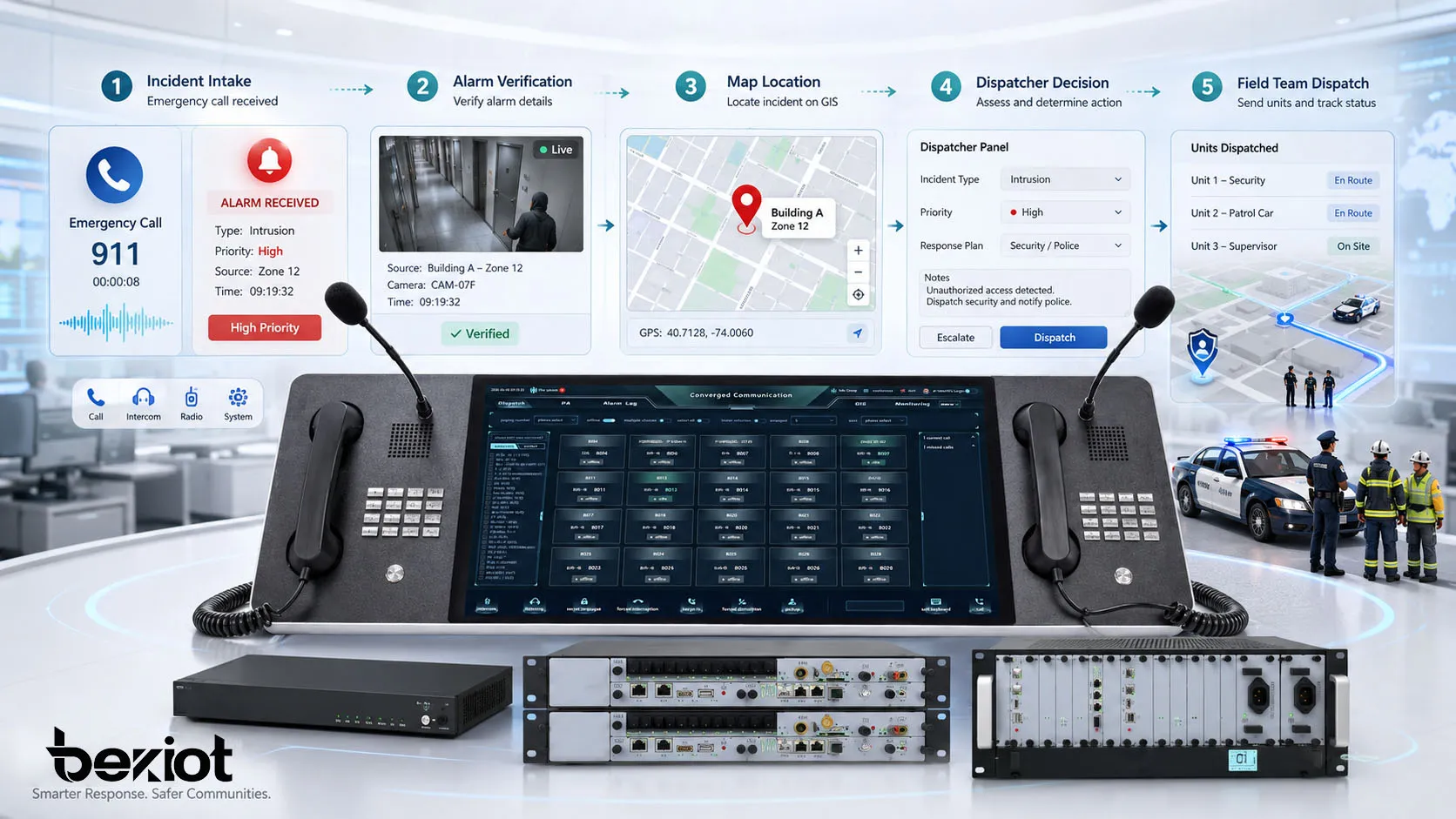
Étape deux : vérification et évaluation de la situation
Toutes les alarmes ne présentent pas le même niveau de risque. Certaines sont fausses, certaines sont des doublons et d’autres sont les premiers signes d’un incident plus important. La vérification permet de confirmer la situation avant l’envoi des ressources ou une escalade majeure.
La vérification peut se faire par communication vocale, contrôle vidéo, comparaison de capteurs, position sur carte, confirmation par patrouille, historique d’accès, contact radio ou retour du personnel proche. L’objectif est de réduire l’incertitude et de construire une image opérationnelle fiable.
Confirmation de localisation
La localisation exacte est l’un des éléments les plus importants de la réponse. Les dispatchers doivent savoir où se trouve l’incident, quelle entrée est la plus proche, quelle zone est touchée, quelle caméra doit être ouverte et quelle équipe est la plus proche.
Les plateformes de commandement cartographiques améliorent cette étape en affichant les points d’incident, emplacements d’appareils, caméras, téléphones d’urgence, patrouilles, véhicules, sorties, zones dangereuses et itinéraires. C’est particulièrement utile dans les tunnels, campus, parcs industriels, pôles de transport, mines et grands lieux publics.
Évaluation de la gravité
L’évaluation de gravité détermine l’urgence de la réponse. Une alerte mineure d’équipement peut demander une inspection de routine, alors qu’un incendie, une fuite de gaz, un acte violent ou un appel de personne piégée nécessite une escalade immédiate. Le workflow doit définir les niveaux de gravité et l’autorité qui peut les modifier.
Des niveaux clairs évitent la sur-réaction et la sous-réaction. Si chaque incident est traité comme critique, les ressources sont gaspillées. Si un événement sérieux est sous-estimé, la réponse peut être retardée.
Étape trois : décision de commandement et planification
Une fois l’incident vérifié, le centre doit décider quoi faire. Cette étape peut inclure le choix d’un plan prédéfini, l’affectation d’une équipe, la notification des superviseurs, l’activation de groupes de communication, la liaison vidéo, l’envoi d’alertes publiques ou la coordination avec les services d’urgence externes.
Dans les environnements à haut risque, les règles de décision doivent être prêtes avant l’incident. Les opérateurs ne doivent pas créer un plan depuis zéro pendant que la situation évolue. Un workflow pratique utilise des procédures prédéfinies tout en permettant aux superviseurs d’ajuster les actions selon les conditions réelles.
Plans prédéfinis et ajustement flexible
Les plans prédéfinis peuvent inclure les rôles, listes de notification, niveaux d’escalade, messages de diffusion, zones d’évacuation, actions de contrôle d’accès, préréglages caméra, groupes radio et étapes de reprise. Ils réduisent l’hésitation pendant les événements urgents.
Cependant, les urgences ne sont presque jamais identiques. Le workflow doit permettre aux utilisateurs autorisés d’adapter le plan lorsque les conditions changent. Par exemple, un accident routier dans un tunnel peut demander un contrôle de voie, une ventilation et un itinéraire de secours différents selon la position exacte et le trafic.
Responsabilités par rôle
Tout workflow de commandement doit définir qui reçoit l’incident, qui le vérifie, qui approuve l’escalade, qui envoie les équipes, qui communique avec le public, qui enregistre l’événement et qui le clôture. La clarté des rôles évite les consignes qui se chevauchent et les responsabilités oubliées.
Dans les opérations multi-services, ce point est essentiel. Sécurité, maintenance, sécurité incendie, support médical, IT, gestion des installations et organismes externes peuvent intervenir dans le même incident. Un workflow par rôles les aide à coordonner sans confusion.
Étape quatre : dispatch et coordination des communications
Le dispatch est le moment où les décisions deviennent des actions sur le terrain. Le centre affecte du personnel, des véhicules, des équipements ou des équipes spécialisées au lieu de l’incident. Les instructions doivent être claires, concises et traçables.
La coordination des communications est tout aussi importante. Les intervenants peuvent utiliser radios, téléphones, interphones, applications mobiles, appels vidéo ou systèmes de sonorisation. Le workflow doit préciser quel canal sert aux ordres, lequel sert aux retours terrain et lequel sert aux notifications publiques.
Voix, vidéo, carte et liaison d’alarme
Le commandement moderne exige souvent plus que la voix. Un dispatcher peut devoir ouvrir la CCTV proche, appeler un téléphone d’urgence, diffuser des consignes à une zone, consulter la carte, vérifier les capteurs et enregistrer tout le processus dans un journal d’incident.
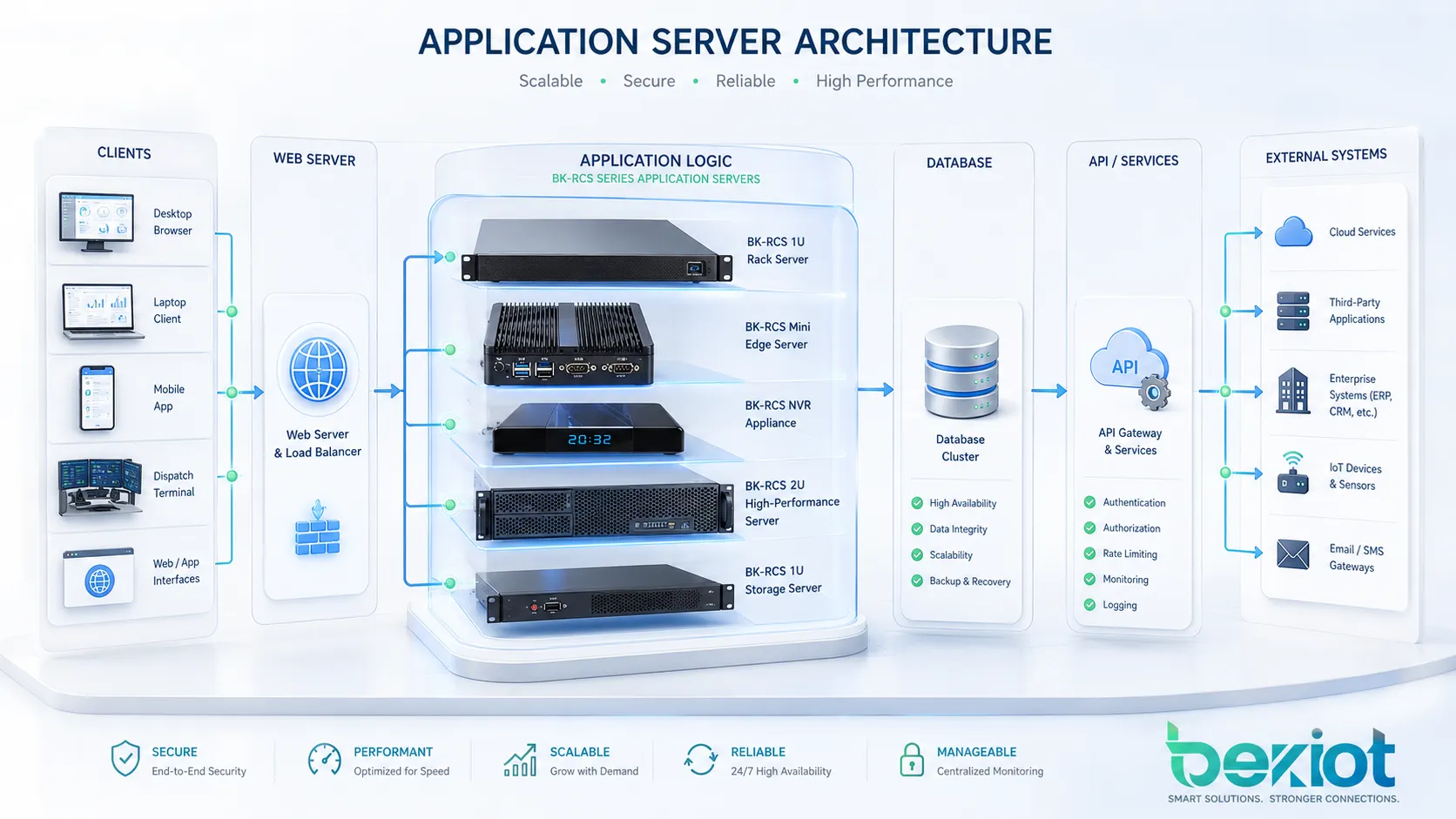
Pour les projets nécessitant ce type de workflow intégré, le système de dispatch unifié Becke Telcom BK-RCS peut constituer une option pratique. Il prend en charge dispatch vocal, liaison vidéo, coordination de diffusion, intégration d’alarmes, opérations GIS et gestion de communication multi-systèmes pour parcs industriels, tunnels, campus, sites de transport et centres de commandement.
Maintenir l’alignement des équipes terrain
Les équipes terrain ont besoin de mises à jour régulières lorsque l’incident évolue. Le workflow doit inclure rapports de statut, confirmation d’arrivée, progression des tâches, avertissements de risque et retour de fin d’intervention. Le centre conserve ainsi la conscience de situation et évite d’envoyer les équipes dans des conditions floues ou dangereuses.
Lorsque plusieurs équipes travaillent en même temps, le groupement des communications devient important. Les équipes médicales, de sécurité, de maintenance et d’évacuation peuvent nécessiter des instructions séparées pendant que le centre garde la vue globale.

Étape cinq : escalade et coordination multi-agences
Certains incidents peuvent être traités par les équipes sur site. D’autres nécessitent une escalade vers la direction, les services d’urgence, la police, les pompiers, les équipes médicales, les fournisseurs d’énergie ou les autorités locales. Le workflow doit définir à l’avance les conditions d’escalade et les méthodes de notification.
L’escalade doit dépendre de la gravité, de la propagation du risque, des obligations légales, de l’impact public, de la menace de sécurité ou de l’incapacité de l’équipe interne à résoudre l’incident. Une escalade tardive peut avoir de graves conséquences, tandis qu’une escalade inutile consomme des ressources et surcharge la communication.
Escalade interne
L’escalade interne peut impliquer responsables d’astreinte, chefs de service, responsables sécurité, superviseurs techniques, direction ou cellule de crise. Le workflow doit définir qui est notifié à chaque niveau et quelles informations sont transmises.
Les messages doivent inclure le type d’incident, le lieu, la gravité, le statut actuel, les ressources affectées, les risques immédiats et l’action suivante. Cela évite des alertes vagues qui obligent les destinataires à rappeler pour obtenir les détails de base.
Coordination externe
La coordination externe peut être nécessaire lorsque l’incident dépasse la capacité interne ou touche à la sécurité publique. Les exemples incluent incendie majeur, blessures graves, fuite de matière dangereuse, incident de sécurité publique, perturbation de transport, panne électrique importante ou évacuation d’urgence.
Lors du travail avec des agences externes, le centre doit fournir localisation précise, routes d’accès, contacts du site, détails de risque et canaux de communication. Si des vidéos, cartes ou journaux sont disponibles, ils accélèrent la compréhension de la situation.
Étape six : notification publique et guidage sur site
Dans de nombreuses urgences, le public ou les occupants du bâtiment ont besoin d’instructions. Elles peuvent concerner l’évacuation, le confinement, les changements d’itinéraire, les interruptions de service, les avertissements de danger ou les annonces de fin d’alerte.
La notification publique doit être exacte, calme et rapide. Des messages mal rédigés peuvent créer confusion ou panique. Le workflow doit inclure des modèles approuvés et des règles indiquant qui peut déclencher les annonces.
Diffusion et alerte visuelle
Les systèmes PA, haut-parleurs IP, sirènes, feux flash, affichage numérique, SMS, applications mobiles, e-mails et alertes de bureau peuvent faire partie de la notification. Le bon canal dépend de l’environnement et du public visé.
Dans les zones industrielles bruyantes, les alertes visuelles et sonores doivent souvent fonctionner ensemble. Sur les campus ou dans les bâtiments, les annonces par zone évitent les perturbations inutiles. Dans les transports, des messages multilingues ou localisés peuvent être nécessaires.
Contrôle et approbation des messages
Les messages d’urgence doivent être contrôlés soigneusement. Le workflow doit définir si les opérateurs peuvent envoyer directement les messages, si une approbation superviseur est nécessaire et quels messages peuvent être automatisés après confirmation d’une alarme.
Les modèles accélèrent la réponse, mais ils doivent être révisés régulièrement. Des instructions obsolètes, des formulations floues ou une mauvaise association de zones réduisent l’efficacité de la notification.
Étape sept : journalisation et gestion des preuves
Chaque action importante pendant l’incident doit être enregistrée. Les journaux soutiennent la responsabilité, l’examen juridique, la formation, la maintenance, les assurances et l’amélioration des performances. Un journal complet peut inclure heure d’alarme, actions opérateur, appels, captures vidéo, dispatch, arrivée des équipes, escalades, annonces publiques et notes de clôture.
Les notes manuelles sont utiles, mais la journalisation automatique réduit les informations manquantes. Lorsque communications, alarmes, vidéo et dispatch sont connectés à une plateforme centrale, le dossier d’incident devient plus facile à examiner.
Décisions traçables
Dans le commandement d’urgence, les décisions doivent être traçables. Le dossier doit indiquer qui a pris la décision, quand, quelles informations étaient disponibles et quelle action a suivi. C’est important pour améliorer les réponses futures et protéger l’organisation lors d’audits ou d’enquêtes.
La traçabilité aide aussi à repérer les lacunes du workflow. Si un délai apparaît entre la réception de l’alarme et le dispatch, le journal peut montrer s’il vient de la vérification, de l’approbation, d’une panne de communication ou d’un manque de ressources.
Enregistrements vidéo et communication
Les clips vidéo, enregistrements d’appels, journaux radio, conversations d’interphone et événements système peuvent fournir des preuves utiles. Ils aident à reconstruire l’incident et à vérifier si la réponse a suivi la procédure.
Les politiques de conservation doivent être définies selon les exigences légales, opérationnelles et de confidentialité. Tous les enregistrements n’ont pas besoin d’être gardés indéfiniment, mais les preuves critiques doivent être protégées contre la suppression accidentelle et l’accès non autorisé.
Étape huit : clôture, revue et amélioration
Un incident ne doit pas être clôturé simplement parce que le danger immédiat est passé. La clôture doit confirmer que la tâche est terminée, que la zone touchée est sûre, que les canaux sont mis à jour, que les messages publics sont arrêtés et que les actions de reprise sont assignées.
Après la clôture, l’organisation doit revoir le workflow. La revue doit se concentrer sur les faits plutôt que sur le blâme. Elle doit identifier ce qui a fonctionné, ce qui a échoué, ce qui a été retardé et ce qui doit être amélioré avant le prochain incident.
Revue post-incident
Une revue post-incident peut examiner le temps de réponse, la précision du dispatch, la qualité de communication, la validité des alarmes, la performance des équipements, la coordination terrain, le moment de l’escalade, la notification publique et la complétude de la documentation.
La revue doit aboutir à des améliorations pratiques. Elles peuvent inclure mise à jour des plans, meilleure maintenance des appareils, modification des règles de notification, formation des dispatchers, ajout de caméras, correction de données cartographiques ou meilleure intégration des systèmes.
Optimisation continue du workflow
Le workflow de commandement d’urgence doit évoluer avec le site. Nouveaux bâtiments, nouveaux équipements, nouveaux risques, nouvelles équipes et nouvelles réglementations peuvent exiger des changements. Des exercices réguliers et des simulations vérifient que le workflow fonctionne encore en conditions réelles.
Les organisations doivent aussi tester les outils de communication, téléphones d’urgence, consoles de dispatch, liaisons radio, zones PA, entrées d’alarme, liaisons vidéo et alimentation de secours. Un workflow n’est fiable que si les systèmes qui le soutiennent sont testés et maintenus.
Considérations de conception clés
Un bon workflow doit être pratique, pas seulement complet. S’il est trop complexe, les opérateurs ne le suivront pas sous pression. S’il est trop simple, il ne couvrira pas les situations réelles. La meilleure conception équilibre vitesse, contrôle, clarté et traçabilité.
| Point clé | Pourquoi c’est important | Focalisation pratique |
|---|---|---|
| Intégration des sources | Plusieurs sources peuvent signaler le même événement | Connecter alarmes, appels, vidéo, capteurs et rapports manuels dans un workflow |
| Précision de localisation | Les intervenants ont besoin du bon lieu et du bon accès | Utiliser cartes, emplacements, zones et ressources proches |
| Définition des rôles | Une autorité floue retarde la réponse | Définir dispatcher, superviseur, intervenant, notificateur et réviseur |
| Fiabilité des communications | Les équipes terrain ont besoin d’un contact stable | Utiliser voix, radio, intercom, mobile et diffusion redondants si nécessaire |
| Traçabilité | Les journaux soutiennent revue, conformité et amélioration | Enregistrer alarmes, décisions, dispatch, communications et clôture |
Intégration système
Le commandement d’urgence est plus efficace quand communication, sécurité, automatisation et supervision travaillent ensemble. L’intégration peut inclure CCTV, contrôle d’accès, alarme incendie, sonorisation, interphonie d’urgence, radio, GIS, capteurs IoT, gestion technique du bâtiment et plateformes de maintenance.
L’intégration doit être conçue autour des besoins du workflow, pas seulement autour de la technologie. La question essentielle est ce que l’opérateur doit voir, entendre, contrôler et enregistrer à chaque étape de l’incident.
Redondance et basculement
Les systèmes d’urgence doivent rester utilisables quand une partie de l’infrastructure tombe en panne. Alimentation de secours, réseaux redondants, canaux secondaires, commande locale manuelle et procédures hors ligne améliorent la résilience.
Pour les sites critiques, les scénarios de défaillance doivent être testés. Le workflow doit encore fonctionner si le réseau principal devient instable, si une caméra est indisponible, si un canal radio est saturé ou si un poste opérateur est hors ligne.
Formation et exercices
Même le meilleur workflow échoue si les personnes ne savent pas l’utiliser. Opérateurs, superviseurs, équipes terrain et maintenance doivent recevoir une formation régulière basée sur des scénarios réalistes.
Les exercices doivent tester non seulement la vitesse de réponse, mais aussi la clarté de communication, la compréhension des rôles, l’utilisation du système, les règles d’escalade et la documentation. Après chaque exercice, le workflow doit être ajusté selon les performances réelles.
Erreurs courantes à éviter
Une erreur fréquente consiste à construire un workflow qui dépend trop de l’expérience d’une seule personne. Si un seul opérateur sait gérer les incidents complexes, le processus est fragile. Le workflow doit être documenté et reproductible.
Une autre erreur est de traiter alarmes, caméras, téléphones, radios et PA comme des outils séparés. Pendant une urgence, les opérateurs ont besoin d’une vue connectée. S’ils doivent passer entre trop de systèmes isolés, la réponse ralentit.
Une troisième erreur est d’ignorer la revue. Sans analyse post-incident, les mêmes problèmes de communication, retards de dispatch et lacunes de coordination peuvent se reproduire. L’amélioration continue fait partie du workflow.
FAQ
Qu’est-ce qu’un workflow de commandement d’urgence ?
Un workflow de commandement d’urgence est un processus structuré pour recevoir les incidents, vérifier l’information, décider, envoyer les ressources, coordonner la communication, escalader, enregistrer les actions et revoir les résultats après l’événement.
Quelles sont les principales étapes ?
Les principales étapes incluent généralement admission de l’incident, vérification, évaluation de situation, décision de commandement, dispatch, communication terrain, escalade, notification publique, journalisation, clôture et revue post-incident.
Pourquoi le dispatch cartographique est-il utile ?
Le dispatch cartographique aide les opérateurs à localiser incidents, intervenants proches, caméras, dispositifs d’urgence, accès, zones et secteurs à risque. Il améliore la conscience de situation et accélère l’affectation des ressources.
Comment les systèmes de communication améliorent-ils le workflow ?
Les systèmes de communication relient dispatchers, équipes terrain, superviseurs, dispositifs PA, téléphones d’urgence, interphones, radios et utilisateurs mobiles. Une communication intégrée réduit les retards et garde les équipes alignées.
Où utiliser le système de dispatch unifié BK-RCS ?
Le système de dispatch unifié Becke Telcom BK-RCS peut être utilisé dans parcs industriels, sites de transport, tunnels, campus, services publics, centres de commandement et environnements de sécurité publique nécessitant dispatch vocal, liaison vidéo, intégration d’alarmes, coordination de diffusion et gestion d’urgence basée sur GIS.
À quelle fréquence faut-il revoir le workflow ?
Il doit être révisé après les incidents majeurs, après les exercices, après les mises à niveau système et lorsque l’aménagement du site, le profil de risque, la structure d’équipe ou les procédures changent. Une revue régulière maintient le workflow pratique et fiable.