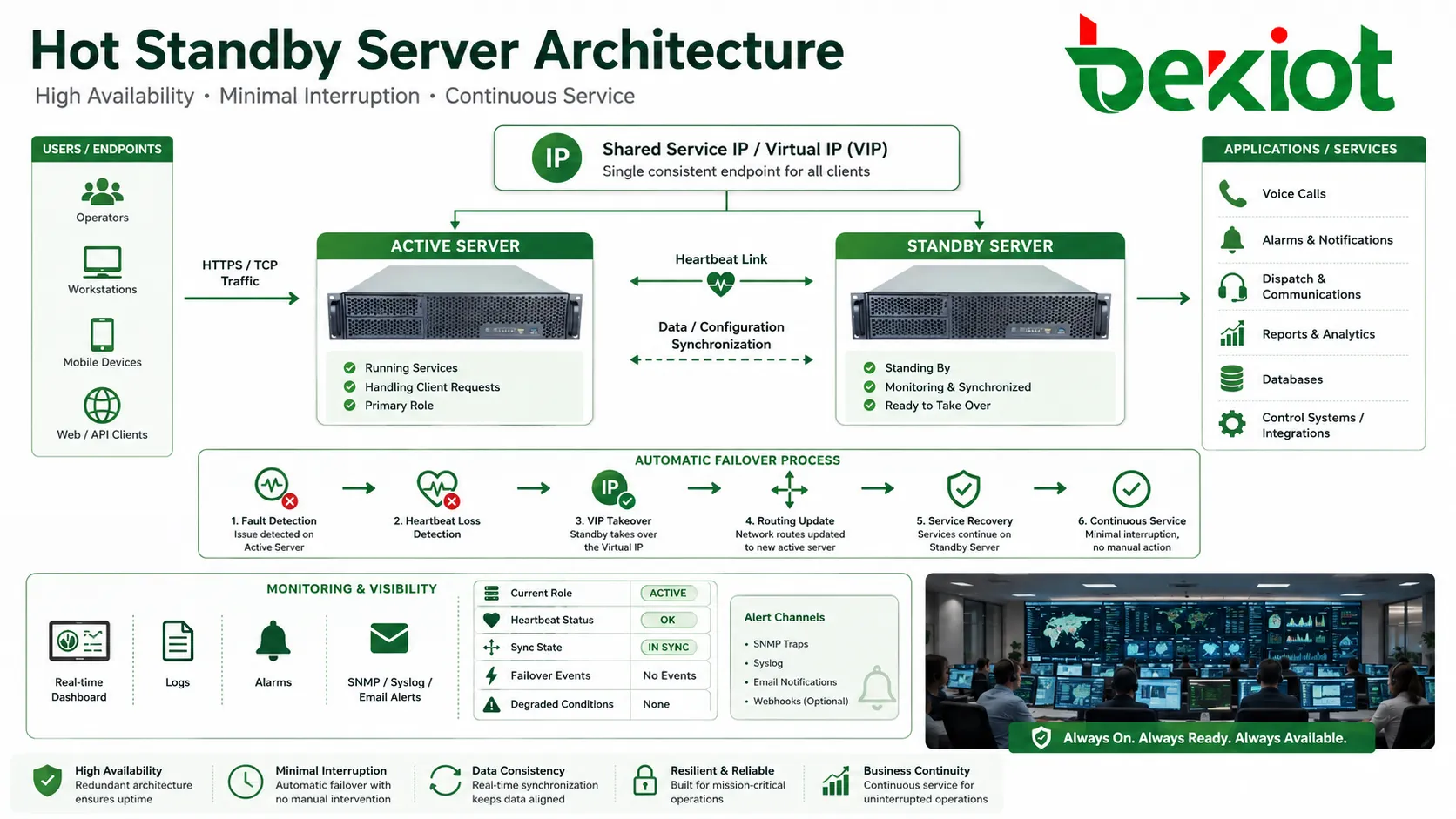
Le hot standby est une conception de haute disponibilité dans laquelle un appareil, serveur, contrôleur, gateway ou plateforme de secours reste alimenté, synchronisé et prêt à prendre le relais quand l’unité active tombe en panne. Au lieu d’attendre une réparation manuelle ou un redémarrage à froid, le côté en veille peut reprendre le service par basculement automatique, réduire l’arrêt et maintenir les systèmes critiques en fonctionnement.
Cette fonction est utilisée dans les plateformes de communication, les centres de données, le contrôle industriel, la sécurité, l’énergie, les transports, les services cloud, les gateways télécom, les systèmes d’urgence et les applications d’entreprise. Sa valeur ne consiste pas seulement à disposer d’une machine de rechange : le nœud de secours doit être raccordé, surveillé, synchronisé et testé pour devenir actif lorsque le nœud de production n’est plus disponible.
Du dispositif de secours à la continuité de service
Une sauvegarde traditionnelle peut rester inutilisée jusqu’à la panne. Le hot standby est différent, car l’élément de secours fait déjà partie de l’architecture en service. Il écoute les signaux de heartbeat, reçoit les mises à jour de configuration, suit l’état des services et se prépare à prendre le relais avec une interruption minimale.
Pour l’utilisateur, le résultat attendu est simple : les appels continuent, les sessions se rétablissent, les alarmes restent visibles, les systèmes de contrôle demeurent disponibles et les opérateurs n’ont pas à reconstruire le service manuellement. Derrière cette simplicité, l’architecture doit gérer la synchronisation des données, la reprise d’IP, l’état du service, les mises à jour de routage, la détection de panne et l’ordre de récupération.
Dans les environnements d’entreprise et industriels, la haute disponibilité est souvent plus importante que la performance maximale. Un système légèrement moins rapide mais disponible en continu peut avoir plus de valeur qu’un système très puissant qui s’arrête sans protection.
Fonctionnement du processus de reprise
Détection par heartbeat
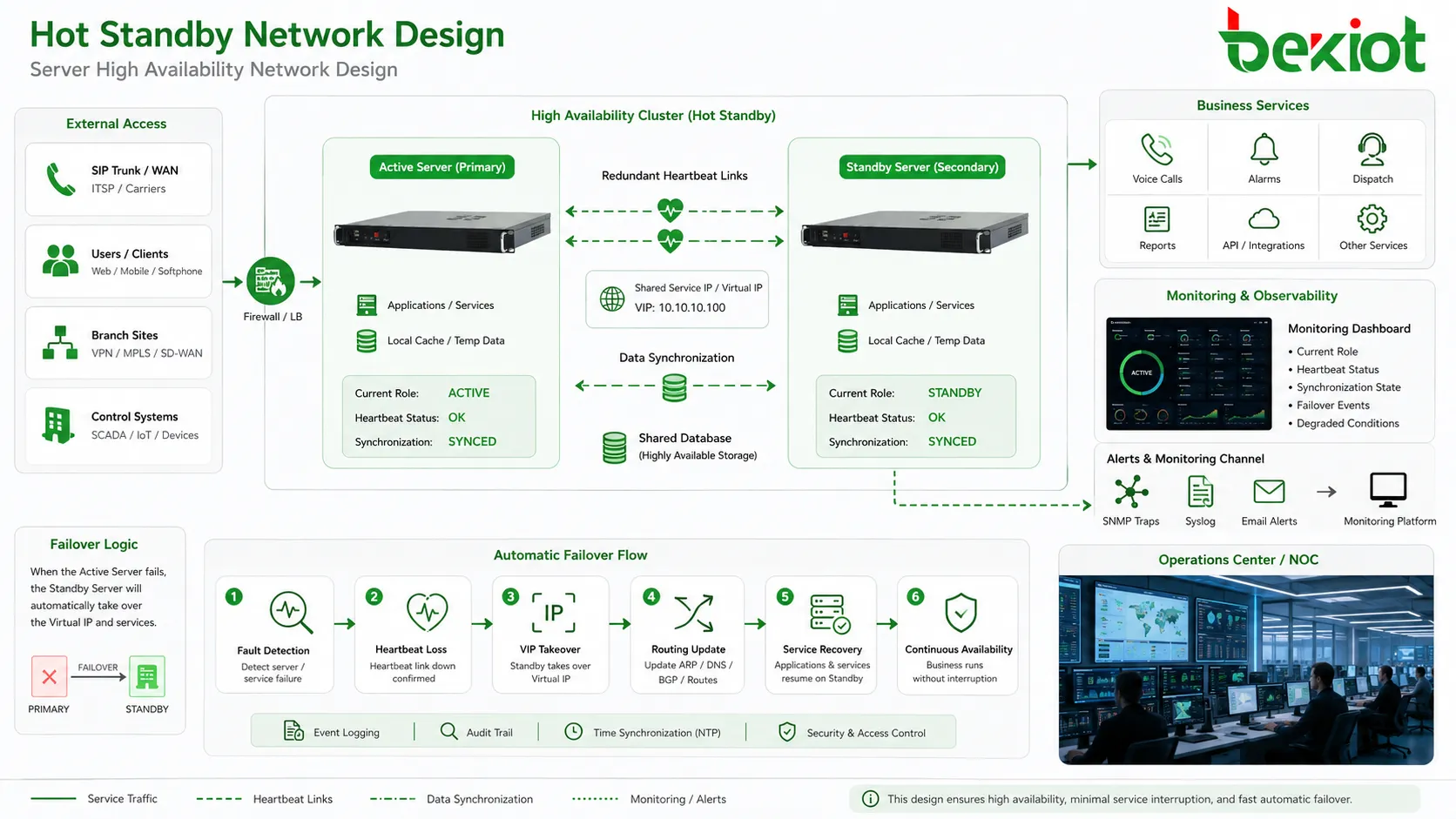
Les nœuds actif et de secours échangent généralement des signaux de heartbeat. Ces signaux confirment que chaque côté est vivant et que le nœud primaire reste responsable du service. Le trafic heartbeat peut passer par un câble dédié, un réseau de gestion, un VLAN privé ou un chemin réseau redondant.
Si le nœud de secours cesse de recevoir des messages heartbeat valides dans une fenêtre définie, il peut supposer que le nœud actif a échoué. Le système lance alors la logique de failover. Cette logique doit être soigneusement réglée, car une réaction trop rapide à un simple retard réseau peut provoquer un basculement inutile.
Synchronisation d’état
Pour une transition fluide, le côté en veille a besoin d’informations à jour : fichiers de configuration, données utilisateur, tables de routage, enregistrements de session, états d’appel, alarmes, entrées de base de données, licences, informations d’enregistrement des appareils ou logique de contrôle.
Certains systèmes ne synchronisent que la configuration, tandis que d’autres synchronisent l’état de service en temps réel. Plus la synchronisation est profonde, plus le failover peut être transparent, mais la synchronisation temps réel augmente aussi la complexité et la dépendance au réseau.
Décision de panne
Après avoir détecté une panne possible, le système doit décider si le nœud actif est réellement indisponible. Il peut vérifier la perte de heartbeat, l’état des processus, le disque, les interfaces, la réponse de la base de données, la charge CPU, les alarmes d’alimentation ou une entrée de supervision externe.
Une bonne conception évite les décisions fondées sur une seule condition. Par exemple, la perte d’un lien heartbeat ne doit pas déclencher automatiquement la reprise si un autre chemin de gestion confirme encore que le nœud actif est sain.
Changement de rôle
Lorsque le failover est confirmé, le nœud de secours change de rôle et devient actif. Il peut reprendre une adresse IP virtuelle, démarrer des services, annoncer des routes, s’enregistrer auprès de systèmes pairs, activer des trunks, prendre le rôle maître de la base de données ou traiter les appels et alarmes.
L’ancien nœud actif peut être isolé, redémarré, réparé ou replacé plus tard comme nœud de secours. Son retour dans l’architecture doit être contrôlé afin d’éviter un conflit de service.
Modèles d’architecture essentiels
Paire actif-veille
Le modèle le plus courant repose sur un nœud actif et un nœud de secours. Le côté actif traite le service de production, tandis que le côté en veille attend et se synchronise. Lorsque le côté actif tombe, le côté en veille prend la main.
Ce modèle est facile à comprendre et largement utilisé dans les PBX, pare-feu, routeurs, contrôleurs, bases de données, baies de stockage et plateformes industrielles. Sa limite est que la ressource de secours peut rester peu utilisée en fonctionnement normal.
Double actif avec logique de secours
Certains environnements utilisent les deux nœuds activement tout en conservant un mécanisme de failover entre eux. Chaque côté peut traiter une partie de la charge en temps normal, puis absorber davantage de trafic lorsque l’autre côté échoue.
Cette conception améliore l’utilisation des ressources, mais exige un équilibrage de charge, une synchronisation, une gestion des sessions et une planification de capacité plus stricts. Si chaque nœud fonctionne déjà presque à pleine charge, il peut manquer de réserve en cas de panne.
Redondance par cluster
Les grands systèmes peuvent utiliser un cluster au lieu d’une simple paire à deux nœuds. Plusieurs nœuds partagent des services, se surveillent mutuellement et redistribuent les charges lorsqu’un membre tombe en panne.
Les architectures en cluster offrent une meilleure évolutivité et une plus grande résilience, mais elles sont plus complexes à déployer et à maintenir. Elles exigent une coordination forte, un contrôle de quorum, des contrôles de santé et une gestion cohérente de la configuration.
Protection géographiquement séparée
Certains systèmes critiques placent les ressources de secours dans un autre bâtiment, campus, centre de données ou région. Cela protège contre une coupure locale de courant, un incendie, une inondation, une panne de salle technique ou une interruption au niveau du site.
La protection géographique améliore la reprise après sinistre, mais elle introduit des défis de latence, de cohérence des données, de routage réseau et de coordination opérationnelle. Tous les services ne peuvent pas basculer correctement sur de longues distances.
| Modèle | Meilleure utilisation | Point principal de conception |
|---|---|---|
| Actif-veille | Paires haute disponibilité simples pour serveurs, passerelles, PBX et contrôleurs. | Utilisation de la ressource de veille et délai de basculement. |
| Double actif | Systèmes nécessitant partage de charge et redondance simultanément. | Réserve de capacité, distribution des sessions et contrôle du retour. |
| Cluster | Grandes plateformes avec plusieurs nœuds de service et charges évolutives. | Quorum, synchronisation, prévention du split-brain et complexité opérationnelle. |
| Protection de site distant | Reprise après sinistre et résilience au niveau du site. | Latence, cohérence des données, routage réseau et procédure de reprise. |
Éléments réseau qui déterminent la fiabilité
Chemin heartbeat
Le lien heartbeat doit être fiable et de préférence redondant. Si ce trafic utilise le même réseau instable que le trafic de service ordinaire, le nœud de secours peut mal interpréter l’état du service pendant une congestion ou une panne de switch.
Pour les déploiements critiques, les concepteurs utilisent souvent deux chemins heartbeat, des liens physiques séparés ou des chemins de commutation différents. Cela réduit le risque qu’une seule panne réseau provoque une reprise incorrecte.
Adresse virtuelle de service
De nombreux systèmes utilisent une adresse IP virtuelle ou une adresse de service flottante. Les utilisateurs et systèmes pairs se connectent à cette adresse stable plutôt qu’à l’adresse physique d’un nœud. Pendant le failover, l’adresse se déplace vers le côté en veille.
Cette méthode simplifie la configuration des clients, mais les équipements réseau doivent mettre à jour ARP, routage, DNS ou tables de session assez rapidement. Une mise à jour lente peut donner l’impression que le failover est retardé même lorsque le nœud de secours est actif.
Données partagées ou répliquées
Certains systèmes reposent sur un stockage partagé, d’autres répliquent les données entre nœuds. Le stockage partagé facilite la cohérence mais peut devenir un point de défaillance unique s’il n’est pas protégé. La réplication accroît l’indépendance mais demande de gérer les retards, conflits et écritures incomplètes.
La bonne méthode dépend du besoin : continuité de configuration, cohérence transactionnelle, intégrité des enregistrements, préservation des sessions ou simple redémarrage du service.
Comportement du routage et des trunks
Les systèmes de communication peuvent se connecter à des trunks SIP, gateways radio, gateways PSTN, consoles de dispatch, API externes, plateformes de supervision et terminaux distants. Ces systèmes externes doivent savoir où envoyer le trafic après le failover.
Si le nœud de secours devient actif mais que les trunks, routes ou enregistrements pairs ne sont pas mis à jour, les utilisateurs peuvent encore subir une interruption. Les essais de failover doivent donc inclure les systèmes amont et aval, pas seulement les deux nœuds locaux.
Couche de gestion et de supervision
La haute disponibilité doit être visible pour les administrateurs. Tableaux de bord, journaux, alarmes, traps SNMP, syslog, alertes e-mail ou plateformes de monitoring doivent afficher le rôle actuel, le heartbeat, la synchronisation, les événements de failover et les états dégradés.
Sans supervision, un système peut fonctionner silencieusement sur le nœud de secours pendant des semaines. Si une autre panne survient ensuite, il peut ne plus rester aucune protection.
Fonctions techniques importantes
Basculement automatique
Le failover automatique permet au côté en veille de devenir actif sans intervention manuelle. C’est essentiel lorsque le système prend en charge des communications en temps réel, des alarmes de sécurité, des opérations de contrôle ou des services client.
Le seuil de failover doit être réglé avec soin. S’il est trop sensible, des basculements injustifiés peuvent apparaître ; s’il est trop lent, les utilisateurs subissent une indisponibilité inutile.
Basculement manuel
La commutation manuelle permet aux administrateurs de déplacer le service d’un nœud à l’autre pendant la maintenance, les mises à jour, les tests ou une réparation planifiée. Elle est utile pour remplacer du matériel, appliquer des correctifs ou vérifier la disponibilité du standby.
Une commutation contrôlée est plus sûre que l’attente d’une panne imprévue, car l’équipe peut planifier l’action, observer le résultat et revenir en arrière si nécessaire.
Contrôle du retour arrière
Après la réparation du nœud initialement actif, le système doit décider si le service revient automatiquement ou reste sur le nœud actuel jusqu’à une fenêtre planifiée. Le retour automatique peut restaurer rapidement le schéma d’origine, mais peut aussi causer une nouvelle interruption.
De nombreux systèmes critiques préfèrent un retour manuel afin que les opérateurs vérifient la santé, la synchronisation et le trafic avant de déplacer à nouveau le service.
Prévention du split-brain
Le split-brain survient lorsque les deux nœuds croient être actifs en même temps. Il peut provoquer des services doublés, des conflits de base de données, des erreurs de routage d’appels, des conflits d’adresse IP ou une corruption de données.
Les moyens de prévention incluent quorum, nœud témoin, fencing, règles de priorité, liens heartbeat redondants et contrôle strict des rôles. La protection contre le split-brain est l’un des éléments les plus importants d’une architecture haute disponibilité.
Protection de l’intégrité des données
Pendant le failover, le système doit protéger les données de configuration et d’exploitation, notamment transactions de base de données, CDR, journaux d’alarme, état d’enregistrement des appareils, enregistrements audio et historique d’événements.
L’intégrité des données est particulièrement importante lorsque le système prend en charge la conformité, la facturation, les dossiers d’urgence, les journaux de dispatch ou les pistes d’audit.
Domaines d’utilisation de cette conception
Plateformes de communication d’entreprise
Les serveurs PBX, plateformes SIP, messageries vocales, serveurs d’enregistrement, centres de contact et plateformes de communications unifiées peuvent utiliser une protection standby pour maintenir les appels métier. Si le serveur actif échoue, le côté de secours peut poursuivre les enregistrements, appels, règles de routage et logiques de service.
Dans les projets de communication critique, Becke Telcom applique une approche de haute disponibilité à la planification des systèmes de communication, en aidant les clients à considérer la redondance serveur, la continuité des gateways, la disponibilité du dispatch et les chemins de failover dans la conception globale.
Contrôle industriel et SCADA
Les systèmes industriels utilisent souvent des contrôleurs standby, serveurs SCADA redondants, doubles gateways de communication et postes opérateur de secours. Ces systèmes soutiennent la production, la sécurité, l’énergie, les utilités et la surveillance des processus.
Le failover doit être testé dans des conditions réelles de procédé. Un système de contrôle qui change correctement de rôle en laboratoire peut se comporter autrement lorsqu’il est connecté aux équipements de terrain, PLC, historiseurs, alarmes et consoles opérateur.
Systèmes de sécurité et vidéosurveillance
Les serveurs de gestion vidéo, plateformes de contrôle d’accès, serveurs d’alarme, nœuds de stockage et systèmes de salle de contrôle peuvent nécessiter une protection standby afin d’éviter des angles morts ou des retards de réponse sécurité.
Dans ces environnements, la conception du failover doit prendre en compte la vidéo en direct, la continuité d’enregistrement, la commande des portes, l’acquittement des alarmes, les journaux d’événements et les droits des opérateurs.
Centres de données et services cloud
Les serveurs, bases de données, pare-feu, équilibreurs de charge, baies de stockage, routeurs et plateformes applicatives utilisent souvent une architecture haute disponibilité. La protection standby peut exister au niveau matériel, virtualisation, conteneur, base de données ou application.
Plus il y a de couches, plus il est important de définir quelle couche est responsable du failover. Plusieurs mécanismes indépendants peuvent entrer en conflit s’ils ne sont pas planifiés ensemble.

Sécurité publique et transport
Les centres d’urgence, systèmes ferroviaires, salles de contrôle de tunnels, opérations aéroportuaires, centres de commandement portuaire et plateformes de gestion du trafic exigent une grande disponibilité. Une panne de communication peut retarder la réponse, réduire la connaissance de situation ou interrompre la coordination.
Pour ces systèmes, la redondance doit couvrir non seulement les serveurs, mais aussi l’alimentation, les switches réseau, trunks, terminaux, postes opérateur et interfaces externes.
Avantages de déploiement au-delà de la réduction d’arrêt
Le bénéfice le plus évident est la continuité du service. Quand le nœud primaire échoue, les utilisateurs continuent à travailler avec moins d’interruption, ce qui est essentiel pour la voix, les alarmes, la supervision, l’accès aux données et les fonctions de contrôle.
Un autre avantage est la flexibilité de maintenance planifiée. Les administrateurs peuvent déplacer le service vers le standby, maintenir le nœud d’origine puis rétablir le rôle normal après vérification, ce qui réduit les longues fenêtres d’arrêt.
La conception standby augmente aussi la confiance lors des mises à niveau. Si une mise à jour crée un problème d’un côté, l’organisation peut disposer d’un chemin contrôlé pour restaurer le service, à condition que l’architecture et le plan de retour arrière soient correctement conçus.
Pour les équipes de direction, la haute disponibilité améliore la maîtrise des risques. Elle transforme la panne d’un seul appareil, d’une coupure totale, en événement géré qui peut être analysé et réparé avec moins d’impact métier.
Scénarios de défaillance pratiques
Défaillance matérielle
Un serveur, une alimentation, un disque, une carte d’interface, un gateway ou un contrôleur peut tomber en panne. Le nœud standby doit détecter que le service actif n’est plus sain et prendre le relais selon la politique configurée.
La panne matérielle est souvent le scénario le plus simple à comprendre, mais ce n’est pas toujours la cause la plus fréquente d’interruption de service.
Arrêt du processus applicatif
La machine peut rester alimentée alors que l’application de service ne répond plus. Un bon contrôle de santé doit vérifier non seulement que le serveur est vivant, mais aussi que le service lui-même fonctionne.
Le simple test ping est généralement insuffisant. Le système peut répondre au ping alors que le moteur d’appel, la base de données, le processus d’alarme ou le service web est en panne.
Isolement réseau
Un nœud peut être isolé des utilisateurs tout en croyant qu’il est sain. Cette situation est dangereuse, car le système peut ne plus savoir quel côté doit être actif.
Des chemins réseau redondants et une logique de quorum aident à éviter les mauvaises décisions lors des événements d’isolement.
Corruption de base de données
Si les données sont corrompues côté actif puis répliquées immédiatement côté standby, la redondance seule ne résout pas le problème. Des sauvegardes et une récupération versionnée restent nécessaires.
La haute disponibilité n’est pas la même chose qu’une sauvegarde. Le nœud standby protège la continuité du service, tandis que la sauvegarde protège la récupération historique.
Erreur opérateur
Une mauvaise configuration, une suppression accidentelle, un mauvais routage ou une mise à jour échouée peuvent toucher les deux nœuds si la configuration est synchronisée automatiquement.
Le contrôle des changements, les circuits d’approbation, l’export de configuration et les plans de retour arrière sont essentiels pour réduire l’impact des erreurs humaines.
La haute disponibilité réduit les arrêts dus aux défaillances de composants, mais elle ne remplace pas les sauvegardes, la cybersécurité, le contrôle des changements, la supervision ni une maintenance disciplinée.
Stratégie de test et d’acceptation
Le failover doit être testé avant la mise en production. Le test doit confirmer que le standby détecte la panne, assume le service, met à jour les chemins réseau, rétablit les connexions externes, conserve les données nécessaires et génère les alarmes appropriées.
Les tests doivent inclure une commutation planifiée, l’arrêt du nœud actif, l’échec d’un processus de service, la perte de lien réseau, une panne de courant lorsque c’est sûr, et la récupération après réparation. Chaque test doit définir le comportement attendu et l’interruption maximale acceptable.
Les dossiers d’acceptation doivent contenir le temps de failover, le résultat de cohérence des données, la disponibilité du service, les alarmes, les journaux, la confirmation opérateur et les problèmes non résolus. Sans trace, un système peut sembler redondant sans être prouvé.
Consignes d’exploitation et de maintenance
L’état standby doit être surveillé en continu. Un nœud de secours allumé mais désynchronisé n’est pas prêt. Les administrateurs doivent surveiller heartbeat, retard de réplication, ressources, état des services, licences, stockage et cohérence des versions.
Les deux côtés doivent être mis à jour avec prudence. Une différence de version peut faire échouer le failover ou provoquer un comportement inattendu ; les mises à jour doivent donc être échelonnées et testées pour éviter de casser les deux nœuds à la fois.
Il faut réaliser périodiquement des exercices de commutation. Un système jamais testé dans des conditions contrôlées peut ne pas fonctionner lors d’une vraie panne, et les exercices aident aussi les opérateurs à comprendre la procédure et le délai de réponse.
Après chaque failover, les journaux doivent être examinés. Même si le service semble normal, la cause doit être recherchée, car des basculements répétés peuvent indiquer une instabilité réseau, une surcharge, un matériel dégradé ou des seuils de santé mal réglés.
FAQ
Le hot standby est-il identique à une sauvegarde ?
Non. Un nœud standby sert à la continuité du service, tandis qu’une sauvegarde sert à la récupération des données. Un système a généralement besoin des deux, car le failover ne restaure pas les anciennes versions de données corrompues ou supprimées.
À quelle vitesse le basculement doit-il se produire ?
Le délai acceptable dépend de l’application. Les systèmes de voix, de contrôle, d’alarme et de sécurité publique exigent souvent une reprise plus rapide que les systèmes ordinaires de reporting ou d’archivage.
Un système de veille protège-t-il contre les bogues logiciels ?
Seulement dans certains cas. Si le même bogue existe sur les deux nœuds, le failover ne résoudra pas le problème. La gestion des versions, les tests, le retour arrière et les sauvegardes restent importants.
Qu’est-ce qui provoque le split-brain ?
Le split-brain est souvent causé par la perte de heartbeat, l’isolement réseau, une conception de quorum faible ou des règles de failover incorrectes. Il survient lorsque plus d’un nœud croit devoir être actif.
Que vérifier après un basculement ?
Après un failover, il faut vérifier le rôle actif, la santé du standby, l’état de synchronisation, les journaux de service, l’impact utilisateur, l’intégrité des données, les trunks ou interfaces externes, les alarmes et la cause racine.