Dans les systèmes de communication modernes fondés sur IP, l’idée d’une adressabilité globale directe a progressivement été remplacée par des architectures de routage en couches qui séparent l’identité du réseau interne de la visibilité externe. La traduction d’adresses réseau (NAT) est l’un des mécanismes essentiels qui rendent cette séparation possible. Elle opère à l’intersection du routage, du suivi de session et de la manipulation de la couche transport, permettant à plusieurs équipements internes de communiquer avec des réseaux externes à travers une frontière de traduction contrôlée et consciente de l’état.
Plutôt que de fonctionner comme un simple outil de substitution d’adresse IP, le NAT agit comme un système de décision dynamique intégré aux passerelles de périphérie. Chaque paquet entrant ou sortant d’un réseau protégé est évalué, transformé et suivi selon l’état de session en temps réel. Cela crée une asymétrie contrôlée entre les domaines d’adressage interne et externe, ce qui modifie en profondeur la manière dont les réseaux IP modernes évoluent et fonctionnent.
Séparation entre l’adressage interne et les domaines de routage externes
Le premier principe structurel du NAT est la séparation entre les espaces d’adresses privées et publiques. Les réseaux internes s’appuient généralement sur les plages RFC1918, volontairement non routables sur l’Internet mondial. Ces adresses peuvent être réutilisées par différentes organisations, ce qui élimine l’exigence d’unicité globale mais les isole des tables de routage externes.
Lorsqu’un équipement situé dans ce type de réseau initie une communication, son adresse IP privée n’a aucune signification en dehors de son domaine local. Le NAT comble cet écart en convertissant, à la frontière du réseau, les adresses source internes en adresses externes valides au niveau mondial. Ce processus permet aux réseaux privés de fonctionner indépendamment des contraintes d’allocation d’adresses IP publiques tout en conservant une connectivité complète.
Cette séparation apporte aussi un avantage structurel : la topologie du réseau interne reste invisible pour les observateurs externes. Ainsi, même si le NAT n’est pas conçu comme un mécanisme de sécurité, il contribue indirectement à réduire l’exposition directe de l’infrastructure interne.
Mécanisme de transformation de paquets avec état en bordure de réseau
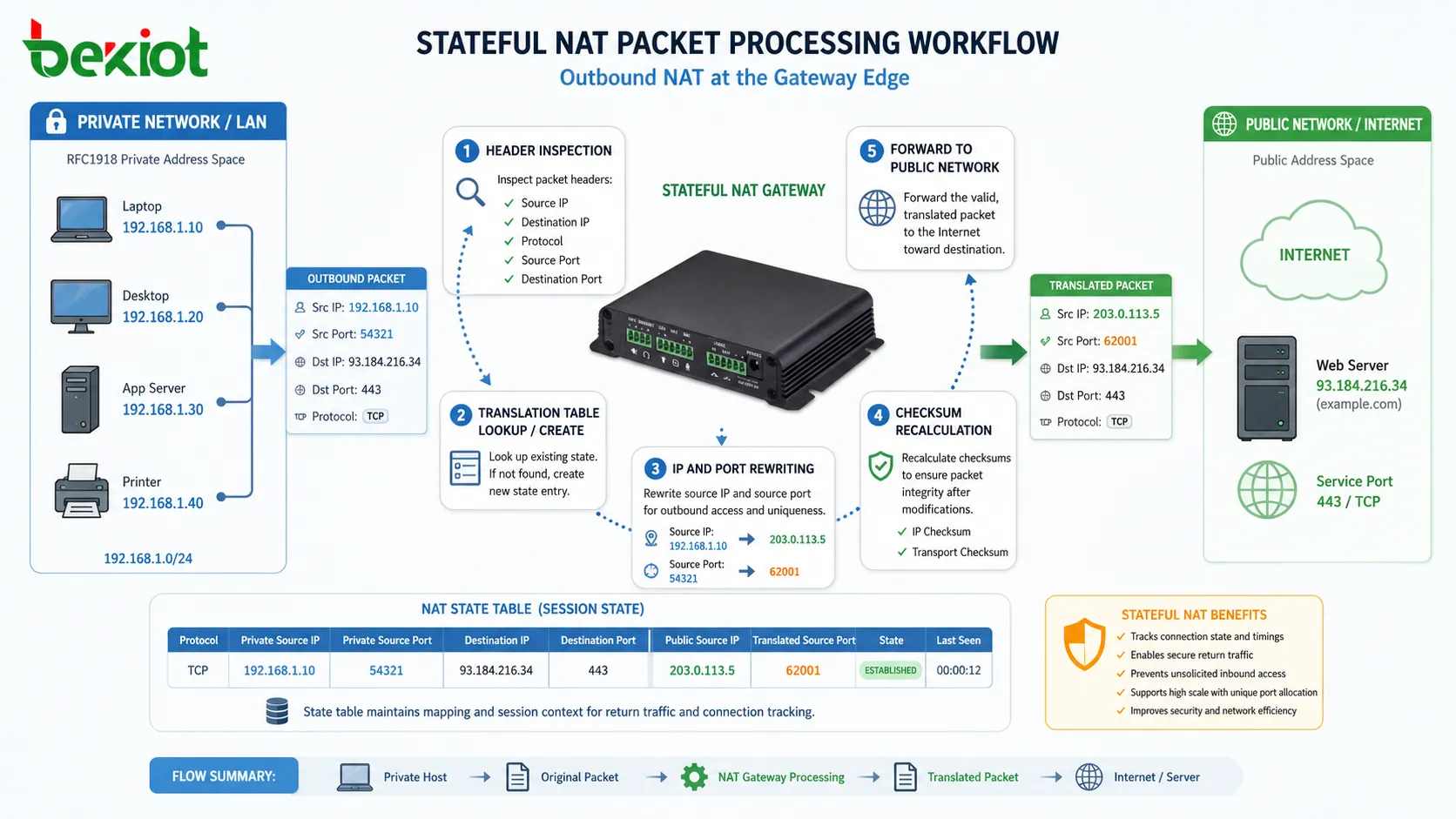
Au cœur du fonctionnement du NAT se trouve un moteur de traitement de paquets avec état, situé dans un équipement passerelle tel qu’un routeur, un pare-feu ou une appliance NAT dédiée. Lorsqu’un paquet sortant arrive, l’équipement inspecte plusieurs champs d’en-tête, notamment l’adresse IP source, l’adresse IP de destination, le type de protocole et les numéros de port de la couche transport.
À partir de cette inspection, le système génère ou récupère une entrée de traduction dans sa table d’état interne. L’adresse IP source est alors remplacée par une adresse IP orientée vers le réseau public et, dans la plupart des implémentations modernes, le port source est également réécrit afin de garantir l’unicité des sessions concurrentes.
Cette transformation doit aussi préserver l’intégrité du paquet. Après modification des champs d’en-tête, les sommes de contrôle sont recalculées au niveau IP et au niveau transport afin de garantir que le paquet reste valide dans les systèmes de routage en aval.
Construction et cycle de vie des tables d’état de traduction
Un composant fondamental du NAT est la table d’état de traduction, qui conserve les correspondances entre les sessions internes et leurs représentations externes. Chaque flux de communication actif génère une entrée unique liant les informations d’adressage interne aux identifiants externes traduits.
Une entrée NAT typique comprend l’adresse IP interne, le port source interne, l’adresse IP publique traduite, le port externe attribué, le type de protocole et les métadonnées de délai d’expiration de session. Ce mappage structuré garantit que le trafic de retour peut être acheminé avec précision vers l’hôte interne d’origine.
Le cycle de vie de ces entrées est strictement contrôlé. Lorsqu’une session est initiée, un nouveau mappage est créé. Pendant la communication active, l’entrée est rafraîchie en fonction de l’activité du trafic. Lorsque la session devient inactive ou est explicitement fermée, l’entrée est supprimée afin de libérer les ressources du système.
| Champ | Fonction |
|---|---|
| IP interne | Identité de l’équipement source dans le réseau privé |
| IP externe | Représentation publique utilisée pour le routage Internet |
| Mappage de ports | Permet de multiplexer plusieurs sessions sur une seule IP |
| Identifiant de protocole | Distingue les flux TCP, UDP ou ICMP |
| Politique de délai d’expiration | Contrôle l’expiration des sessions et le nettoyage des ressources |
Traduction d’adresse de port et comportement de multiplexage des connexions
L’une des formes les plus déployées de NAT est la traduction d’adresse de port (PAT), également appelée surcharge NAT. Dans ce modèle, plusieurs équipements internes partagent une seule adresse IP publique. La différenciation des sessions est réalisée par l’allocation dynamique de numéros de port source.
Lorsque plusieurs hôtes internes initient simultanément des connexions sortantes, le système NAT attribue à chaque session un identifiant de port externe unique. Cela garantit que le trafic de retour peut être correctement associé au point de terminaison interne approprié, sans ambiguïté.
Ce mécanisme améliore fortement l’efficacité d’utilisation des adresses IPv4. Au lieu d’exiger une adresse IP publique par équipement, des milliers d’équipements peuvent fonctionner simultanément avec un même pool d’adresses visible de l’extérieur.
Reconstruction du trafic de retour et logique de mappage inverse
Le traitement du trafic entrant dans le NAT est fondamentalement symétrique à la traduction sortante, mais il repose entièrement sur une reconstruction par recherche. Lorsqu’un paquet de réponse arrive depuis un serveur externe, la passerelle NAT examine la combinaison adresse IP de destination et port de destination.
Elle effectue ensuite une recherche dans la table d’état de traduction afin d’identifier l’entrée de mappage interne correspondante. Une fois l’entrée trouvée, le système restaure l’adresse IP et le port de destination d’origine avant de transmettre le paquet au réseau interne.
Ce processus de mappage inverse garantit la continuité complète de la session. Ni les serveurs externes ni les clients internes ne perçoivent la couche de traduction, qui reste transparente au niveau applicatif.
Contrôle des délais d’expiration et stratégie d’optimisation des ressources
Comme le NAT est fondamentalement un système avec état, il doit gérer efficacement la mémoire et les ressources de traitement. Chaque session active consomme une partie de la table de traduction, et une croissance non maîtrisée peut provoquer une dégradation des performances ou l’épuisement de la table.
Pour limiter ce risque, les implémentations NAT appliquent des politiques de délai d’expiration propres à chaque protocole. Les sessions TCP sont généralement conservées jusqu’à réception de signaux explicites de terminaison, tandis que les sessions UDP dépendent de temporisateurs d’expiration basés sur l’inactivité. Les mappages ICMP sont en général de courte durée en raison de leur nature sans état.
Architecture de traduction de niveau opérateur dans les réseaux à grande échelle
Dans les réseaux de fournisseurs de services à grande échelle, les implémentations NAT traditionnelles ne suffisent plus face au très grand nombre d’abonnés simultanés. Le NAT de niveau opérateur (CGNAT) étend le modèle NAT de base vers une architecture de traduction distribuée et à haute capacité, capable de traiter des millions de sessions simultanées.
Contrairement au NAT d’entreprise, qui fonctionne généralement sur une seule passerelle de périphérie, les systèmes CGNAT répartissent les charges de traduction entre des nœuds en cluster. Chaque nœud prend en charge une partie du pool d’adresses et de la table de sessions, ce qui permet l’extension horizontale et la tolérance aux pannes. Cette architecture est essentielle dans les réseaux mobiles, les FAI haut débit et les environnements de diffusion de contenu où l’épuisement d’IPv4 est le plus marqué.
Dans les déploiements CGNAT, la persistance de session et le mappage déterministe deviennent plus complexes en raison de l’équilibrage de charge entre les nœuds de traduction. Pour y répondre, des algorithmes NAT déterministes ou des mécanismes de hachage fondés sur l’abonné sont utilisés afin que les sessions d’un même hôte interne soient associées de manière cohérente au même contexte de traduction externe.
Impact sur les systèmes de communication en temps réel et les protocoles de transport
La traduction d’adresses réseau introduit des défis particuliers pour les systèmes de communication en temps réel tels que la VoIP, la visioconférence et les réseaux de dispatching industriel. Ces systèmes dépendent fortement de la connectivité de bout en bout et intègrent souvent des informations d’adresse IP directement dans les charges utiles applicatives.
Les protocoles tels que SIP (Session Initiation Protocol) et H.323 peuvent rencontrer des problèmes de connectivité lorsque le NAT modifie l’adressage de la couche transport. En effet, les messages de négociation de session peuvent contenir des références à des adresses IP privées, invalides dans les réseaux externes.
Pour atténuer ce problème, des techniques de traversée NAT telles que STUN (Session Traversal Utilities for NAT), TURN (Traversal Using Relays around NAT) et ICE (Interactive Connectivity Establishment) sont couramment déployées. Elles permettent aux terminaux de découvrir leurs adresses visibles publiquement et d’établir des chemins médias à travers les frontières NAT.
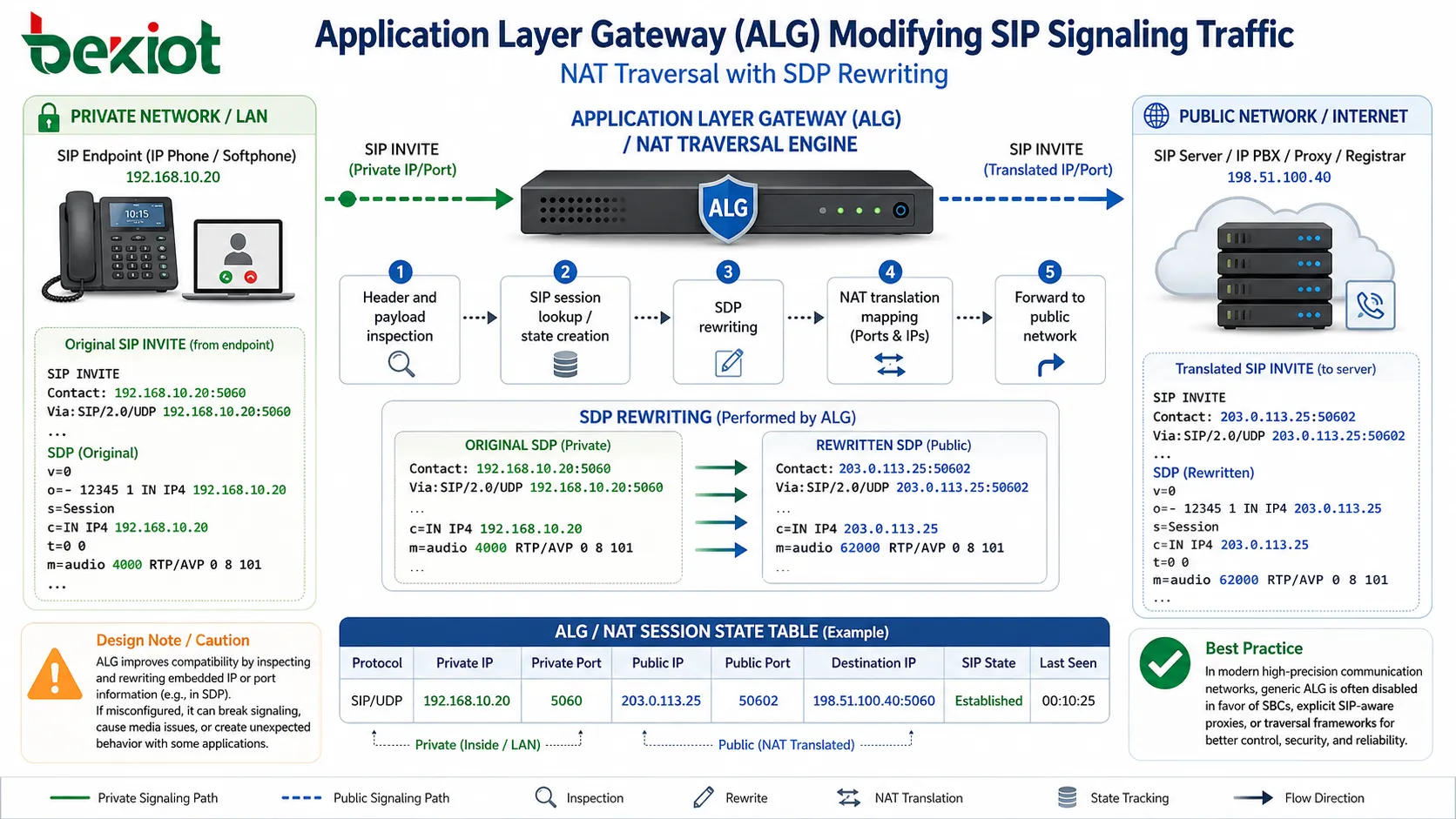
Comportement de passerelle de couche application et adaptation de protocole
Certaines implémentations NAT incluent une fonction de passerelle de couche application (ALG), qui inspecte et modifie les charges utiles applicatives afin de maintenir la cohérence du protocole. C’est particulièrement important pour les protocoles qui incorporent des informations d’adresse IP ou de port dans la charge utile elle-même.
Par exemple, SIP ALG peut réécrire des champs SDP (Session Description Protocol) intégrés afin de remplacer des adresses IP privées par des adresses publiques traduites. Si cela améliore la compatibilité, une mauvaise configuration peut aussi introduire de la complexité et des effets secondaires indésirables.
Les conceptions réseau modernes désactivent souvent les fonctions ALG génériques au profit de proxys explicitement conscients des applications ou de cadres de traversée, surtout dans les environnements de communication exigeant une grande précision.
Transition IPv6 et diminution du rôle du NAT
L’introduction d’IPv6 modifie fortement le rôle à long terme du NAT dans l’architecture mondiale des réseaux. Grâce à un espace d’adressage élargi, IPv6 élimine le besoin de stratégies de conservation d’adresses telles que PAT.
Cependant, le NAT n’a pas disparu. Il a évolué vers des mécanismes de transition tels que NAT64 et les systèmes de traduction double pile, qui assurent l’interopérabilité entre réseaux IPv4 et IPv6.
Dans de nombreux déploiements réels, IPv4 et IPv6 coexistent, ce qui exige des couches de traduction capables de relier des modèles d’adressage fondamentalement différents. Cette phase de transition garantit la compatibilité ascendante tout en permettant une migration progressive vers des infrastructures natives IPv6.
Contraintes de performance et modèles d’optimisation à haut débit
Le traitement NAT introduit une surcharge de calcul liée à l’inspection des paquets, à la réécriture des en-têtes et à la gestion des tables d’état. Dans les environnements à haut débit, cela peut devenir un goulot d’étranglement si l’optimisation est insuffisante.
Pour répondre à ces contraintes, les implémentations NAT modernes utilisent l’accélération matérielle, le traitement multicœur et les tables de session distribuées. Les processeurs réseau (NPU) et les moteurs de transfert fondés sur ASIC sont couramment employés pour décharger les tâches de traduction des processeurs généralistes.
Une autre technique d’optimisation consiste à utiliser le cache de flux, où les entrées de traduction fréquemment utilisées sont stockées en mémoire rapide afin de réduire la latence de recherche pendant le traitement des paquets.
Modes de défaillance et comportement de diagnostic des systèmes NAT
Lorsque les systèmes NAT rencontrent un épuisement des ressources ou des incohérences de configuration, plusieurs modes de défaillance peuvent apparaître. Le problème le plus courant est l’épuisement des ports, lorsqu’aucun port externe n’est disponible pour l’allocation de nouvelles sessions.
Un autre scénario fréquent est le routage asymétrique, où le trafic de retour contourne le dispositif NAT à cause d’une configuration de routage incorrecte, ce qui rompt l’état de session et entraîne la suppression de paquets.
L’analyse de diagnostic consiste généralement à examiner les tables de traduction, les journaux de session et les compteurs d’interface afin d’identifier les anomalies de mappage ou d’utilisation des ressources.
Stratégies de déploiement opérationnel en environnement d’entreprise
Dans les réseaux d’entreprise, le déploiement du NAT est généralement aligné sur les stratégies de zonage de sécurité et de segmentation. Les réseaux internes sont divisés en zones de confiance, et les passerelles NAT sont placées sur des frontières contrôlées entre domaines internes et externes.
Des règles NAT fondées sur des politiques peuvent être appliquées à différentes classes de trafic, ce qui permet une traduction sélective selon le type d’application, la destination ou le groupe d’utilisateurs. Les organisations conservent ainsi un contrôle granulaire sur les flux de communication entrants et sortants.
Dans les systèmes de communication industrielle, le NAT est souvent combiné aux tunnels VPN et aux politiques de pare-feu afin d’imposer une isolation réseau multicouche tout en préservant la connectivité opérationnelle.
Relation entre le NAT et les architectures de communication industrielle
Dans les environnements industriels tels que les centres de dispatching, les systèmes électriques, les pôles de transport et les réseaux de communication d’urgence, le NAT joue un rôle critique pour établir une connectivité multisite entre domaines IP privés.
Ces systèmes reposent souvent sur des architectures hybrides où les réseaux de contrôle locaux fonctionnent de manière indépendante tout en nécessitant une coordination centralisée. Le NAT rend cela possible en abstraisant l’adressage interne et en maintenant des chemins de communication contrôlés entre nœuds distribués.
Toutefois, les exigences strictes de latence et de fiabilité dans ces systèmes imposent une configuration soigneuse du NAT afin d’éviter le jitter, la perte de session ou les retards de propagation de la signalisation.
Interprétation du comportement NAT au niveau système
Du point de vue de l’ingénierie système, le NAT peut être interprété comme une machine à états déterministe qui transforme l’identité des paquets selon des règles prédéfinies et un contexte de session dynamique.
Il opère à travers plusieurs couches d’abstraction : adressage réseau, multiplexage de transport, persistance de session et application des politiques. Ce comportement multicouche distingue le NAT des simples mécanismes de routage et le positionne comme un composant fondamental de l’architecture moderne des réseaux IP.
Questions fréquentes
Pourquoi le NAT existe-t-il encore dans les environnements IPv6 ?
Bien qu’IPv6 réduise le besoin de traduction d’adresses, le NAT subsiste dans des mécanismes de transition qui relient les réseaux IPv4 et IPv6 et assurent la compatibilité ascendante.
Le NAT peut-il affecter la latence dans les systèmes de communication à haute fréquence ?
Oui. Le traitement supplémentaire nécessaire à la réécriture des en-têtes et à la recherche d’état peut introduire une légère latence, surtout lorsque la charge de sessions est élevée.
Quelle est la différence entre le NAT et un pare-feu ?
Le NAT modifie les informations d’adressage à des fins de routage, tandis qu’un pare-feu applique des politiques de sécurité. Ils coexistent souvent, mais leurs rôles fonctionnels sont différents.
Pourquoi certaines applications échouent-elles derrière un NAT ?
Les applications qui intègrent des informations IP dans les données utiles ou qui exigent une connectivité directe pair à pair peuvent échouer si aucune technique de traversée NAT n’est appliquée.
Le CGNAT est-il réversible pour le dépannage ?
Les systèmes CGNAT conservent des journaux et des enregistrements de mappage, mais en raison de l’agrégation à grande échelle, le traçage inverse nécessite des systèmes centralisés de corrélation des journaux.