

Imaginez un site distant qui perd sa connexion à la plateforme centrale alors que les opérateurs doivent encore s’appeler, joindre des contacts d’urgence et maintenir les communications essentielles.
C’est précisément là que la survivabilité locale prend de la valeur. Elle n’est pas conçue pour des conditions réseau idéales, mais pour le moment où le chemin principal est interrompu, où le lien WAN devient instable, où le serveur central est inaccessible ou où le service cloud ne peut plus être atteint depuis le site.
Maintenir les communications essentielles pendant l’isolement réseau
La survivabilité locale désigne la capacité d’une agence, station de terrain, installation industrielle ou d’un nœud de communication distant à continuer d’exécuter les services essentiels lorsque sa connexion au système central est interrompue. Dans les réseaux de communication, cela signifie généralement que les utilisateurs locaux peuvent encore s’appeler, accéder à des numéros d’urgence prédéfinis, utiliser des lignes ou trunks locaux et conserver les services vocaux critiques sans attendre le rétablissement de la plateforme centrale.
Son avantage pratique est la continuité. De nombreux systèmes distribués dépendent de serveurs centraux pour l’enregistrement, le routage, le contrôle des politiques, l’enregistrement audio ou la gestion des utilisateurs. Ce modèle centralisé est efficace en fonctionnement normal, mais il crée aussi une dépendance. Si le lien WAN échoue, les terminaux du site distant peuvent perdre l’accès au serveur d’appels principal, au PBX cloud, à la plateforme de dispatching ou au centre de contrôle des communications. Sans survivabilité, le site peut devenir opérationnellement isolé.
Avec la survivabilité locale, une passerelle, un serveur, un contrôleur ou un nœud de service embarqué local peut reprendre temporairement certaines fonctions de communication. Il ne remplace pas forcément toute la plateforme centrale. Il préserve plutôt les services les plus importants pour l’exploitation locale : appels internes, communication d’urgence, routage local, trunks de secours, repli d’enregistrement des terminaux et parfois des fonctions limitées de dispatching ou de diffusion.
Cette capacité est particulièrement importante dans les usines, stations de transport, sites énergétiques, campus, parcs logistiques, mines, tunnels, aéroports et sites de service public. Ces environnements ne peuvent pas arrêter les communications simplement parce qu’un lien principal est coupé. La survivabilité locale fournit un état de repli contrôlé au lieu d’une panne complète de service.
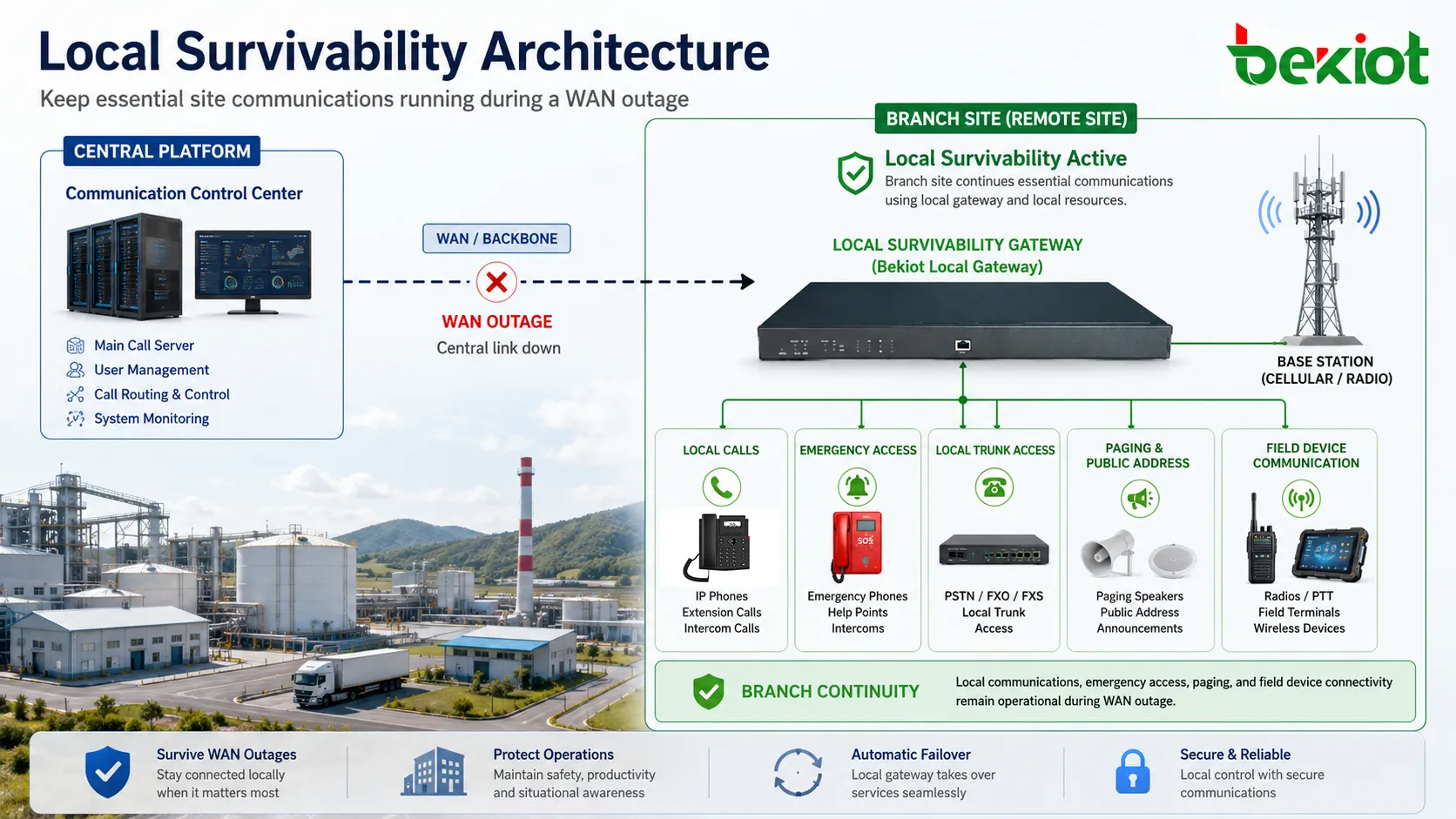
Réduire la dépendance à une seule plateforme centrale
Les plateformes de communication centralisées simplifient l’administration, mais elles peuvent devenir un point unique de dépendance si les sites distants n’ont aucun repli local. Dans une architecture classique, l’enregistrement des terminaux, le routage des appels, l’authentification, la traduction des numéros et les politiques de service peuvent tous être traités par le système central. Si chaque action de communication doit passer par cette plateforme, une panne de liaison peut même empêcher deux appareils du même bâtiment de s’appeler localement.
La survivabilité locale modifie ce modèle de dépendance. Elle permet à certaines fonctions locales de rester disponibles dans des conditions prédéfinies. Par exemple, les extensions locales peuvent se réenregistrer sur une passerelle survivable, ou la passerelle peut conserver un plan de numérotation en cache pour les appels locaux. Les numéros d’urgence peuvent être routés par des trunks locaux. Les postes de sécurité, équipes de maintenance, salles de contrôle de production et terminaux de terrain peuvent continuer à communiquer à l’intérieur du site même si le serveur principal est inaccessible.
Cela ne signifie pas tout décentraliser. Une bonne conception continue d’utiliser la gestion centralisée en fonctionnement normal, car elle offre configuration unifiée, supervision, contrôle des politiques et maintenance simplifiée. La survivabilité ajoute un second état d’exploitation. Le système fonctionne de manière centralisée quand le réseau est sain et bascule vers le contrôle local seulement quand le chemin central échoue.
L’avantage est l’équilibre. Les organisations profitent de l’architecture centralisée sans accepter une perte totale de service pendant l’isolement réseau. C’est particulièrement utile dans les déploiements multisites où chaque agence, station, usine ou nœud de terrain possède ses propres responsabilités opérationnelles.
Maintenir les appels d’urgence lorsque la route principale échoue
Les appels d’urgence sont l’une des raisons les plus importantes de déployer la survivabilité locale. Dans de nombreux environnements, les utilisateurs peuvent devoir contacter la sécurité, les pompiers, le support médical, les opérateurs de salle de contrôle ou les services d’urgence locaux précisément lors d’un incident qui perturbe aussi la connectivité. Si le système dépend entièrement d’une plateforme centrale, l’appel d’urgence peut échouer au moment où il est le plus nécessaire.
Un nœud local survivable peut préserver le routage d’urgence via des numéros locaux, lignes analogiques, trunks SIP, passerelles radio ou terminaux de réponse prédéfinis. La conception dépend du site, mais le principe reste le même : la communication d’urgence doit disposer d’un chemin local qui ne dépend pas complètement d’une infrastructure distante. Cela est essentiel pour les sites industriels isolés, stations de transport, installations souterraines, plateformes offshore et environnements de sécurité publique.
La survivabilité locale rend aussi le comportement d’urgence plus prévisible. Lorsque la plateforme centrale est indisponible, les utilisateurs ne doivent pas deviner quels numéros fonctionnent encore. Le système doit définir quels numéros d’urgence restent disponibles, où ces appels sont routés, comment les opérateurs sont alertés et si le routage de repli est automatique. Un comportement clair en situation de panne vaut mieux qu’un système complexe qui ne fonctionne qu’en conditions normales.
Dans la planification du déploiement, le routage d’urgence doit être testé séparément des appels ordinaires. Les ingénieurs doivent vérifier que les appels d’urgence aboutissent pendant une panne WAN simulée, que l’emplacement ou l’identité du terminal est conservé si nécessaire, que les opérateurs locaux reçoivent l’appel et que les trunks de secours fonctionnent correctement. La survivabilité n’a de valeur que si le chemin de repli a été vérifié avant un incident réel.
Soutenir les opérations locales sur les sites industriels et distants
Certains sites ne peuvent pas suspendre leurs opérations parce que le réseau central devient indisponible. Une ligne de production peut encore nécessiter une coordination entre la salle de contrôle et le personnel de terrain. Une gare peut devoir maintenir la communication interne entre quai, sécurité et maintenance. Une mine peut avoir besoin d’un contact vocal entre les points souterrains et la supervision locale. Un poste électrique peut nécessiter des échanges entre opérateurs et techniciens. Ce sont des workflows locaux, et beaucoup doivent rester disponibles pendant la déconnexion centrale.
La survivabilité locale répond à ce besoin en gardant la communication près des personnes et des équipements qui en dépendent. Au lieu de faire passer chaque appel par un centre de données distant ou une plateforme cloud, certains appels locaux peuvent être traités dans le site. Cela réduit la dépendance aux longs chemins réseau et donne à l’installation une capacité de base en mode dégradé.
Dans les environnements industriels, la valeur n’est pas seulement technique. Elle soutient aussi la sécurité et la discipline de production. Les opérateurs peuvent signaler des défauts, les équipes de maintenance coordonner les réparations, les agents de sécurité communiquer avec les portails ou patrouilles, et les téléphones d’urgence joindre les postes locaux de réponse. Le site peut fonctionner en mode réduit, mais il ne devient pas silencieux.
C’est particulièrement utile dans les lieux où la réparation du WAN peut prendre du temps. Sites isolés, armoires extérieures, parcours souterrains et liaisons louées ne sont pas toujours rétablis immédiatement. Une couche de survivabilité locale donne du temps aux équipes de réparation tout en maintenant la coordination interne essentielle.
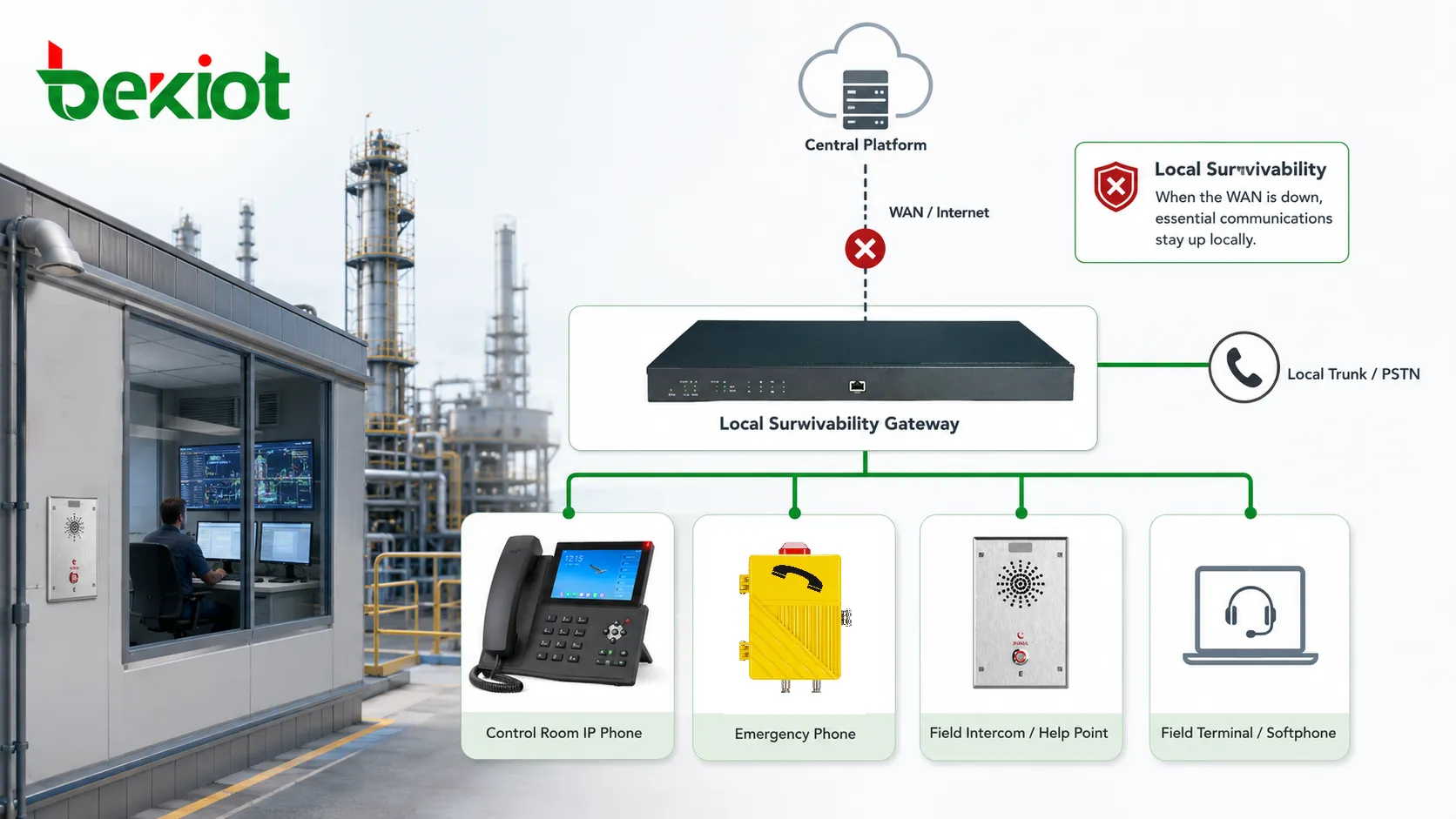
Améliorer la résilience sans complexifier tout le réseau
La résilience est souvent associée à une redondance complète : serveurs doublés, liens doublés, centres de données de secours, opérateurs multiples et systèmes parallèles. Ces conceptions peuvent être nécessaires pour de grands réseaux ou des applications critiques, mais elles peuvent aussi être coûteuses et complexes. La survivabilité locale offre une méthode ciblée de résilience en protégeant les fonctions de communication les plus importantes du site sans dupliquer toute la plateforme centrale à chaque emplacement.
Elle est donc attractive pour les organisations distribuées. Une agence n’a pas forcément besoin d’un serveur de communication complet avec toutes les fonctions avancées. Une station ou une usine n’a pas toujours besoin d’une duplication complète de plateforme. Ce qu’elle doit conserver, ce sont les appels de base, le routage d’urgence et l’accès aux services locaux pendant la déconnexion. La survivabilité cible ce besoin pratique.
L’architecture peut être dimensionnée selon le risque. Une agence à faible risque peut seulement nécessiter des appels d’urgence locaux et un repli d’extensions internes. Un site industriel critique peut nécessiter enregistrement local, trunks locaux, téléphones d’urgence, accès à la sonorisation et repli de console opérateur. Un réseau de transport peut exiger une continuité au niveau station et une reconnexion contrôlée au centre de commande lorsque le lien revient.
En adaptant la profondeur de survivabilité à l’importance du site, les organisations améliorent la résilience sans construire partout une infrastructure inutilement lourde. Le but n’est pas de rendre chaque site totalement indépendant, mais de s’assurer que chaque site conserve les fonctions de communication réellement nécessaires en conditions réseau anormales.
Réduire le temps de reprise après une interruption
La survivabilité locale peut réduire l’impact opérationnel des pannes parce que les services ne s’effondrent pas complètement pendant l’incident. Lorsque le chemin central est restauré, le système peut revenir du repli local au fonctionnement centralisé. Cette transition peut être automatique ou contrôlée selon la conception de la plateforme et les exigences du projet.
Sans survivabilité, une panne WAN peut déclencher de nombreux problèmes secondaires. Les utilisateurs répètent des appels qui échouent, les opérateurs reçoivent des plaintes, le routage d’urgence devient incertain et les équipes de maintenance doivent expliquer pourquoi des appareils proches ne peuvent pas communiquer. La reprise ne consiste pas seulement à rétablir le lien réseau ; elle consiste aussi à restaurer la confiance des utilisateurs et l’ordre du service.
Avec la survivabilité, le site continue à fonctionner dans un mode limité mais organisé. Les utilisateurs locaux peuvent constater que certains services centraux sont indisponibles, mais la communication essentielle reste possible. Lorsque la plateforme principale revient, enregistrements, routage et contrôle de politique peuvent être resynchronisés vers l’état normal. La panne devient plus facile à gérer et moins perturbatrice.
La planification de reprise doit aussi inclure ce qui se passe après la fin de la panne. Le système doit éviter les doubles enregistrements, la confusion de routage, les états utilisateurs incohérents ou la restauration retardée. Les équipes de maintenance doivent voir quand le site est entré en mode survivable, quels appels ont été traités localement et quand le mode normal a repris. Ces journaux vérifient le bon comportement du basculement.
Préserver l’expérience utilisateur en conditions dégradées
Les utilisateurs ne pensent généralement pas aux serveurs d’appels, au routage WAN, à l’enregistrement SIP ou au repli des trunks. Ils s’attendent à ce que le téléphone, le terminal d’urgence, l’interphone ou la console fonctionne au moment nécessaire. La survivabilité locale préserve cette expérience en gardant disponibles les actions de communication les plus familières lorsque le réseau global est dégradé.
Par exemple, un utilisateur peut encore composer une extension locale, contacter le poste de sécurité, joindre la salle de contrôle ou activer un point d’appel d’urgence. Le système fonctionne peut-être en mode de repli, mais l’expérience reste assez proche de la normale pour les tâches critiques. Cela réduit la confusion et évite que les personnes abandonnent les procédures officielles au profit de solutions informelles.
Préserver l’expérience réduit également l’effort de formation. Si le comportement de repli suit les schémas de numérotation et les routes de réponse habituels, les utilisateurs n’ont pas à mémoriser une méthode spéciale pour les pannes réseau. Le système doit s’adapter à la panne, et non obliger chaque utilisateur à changer de comportement dans un moment stressant.
Toutes les fonctions ne peuvent toutefois pas rester disponibles localement. Les services avancés comme les annuaires centralisés, l’enregistrement distant, la conférence intersite, la messagerie vocale cloud ou le routage global peuvent être indisponibles pendant l’isolement. Un bon déploiement définit clairement les fonctions garanties localement et celles qui dépendent du système central.
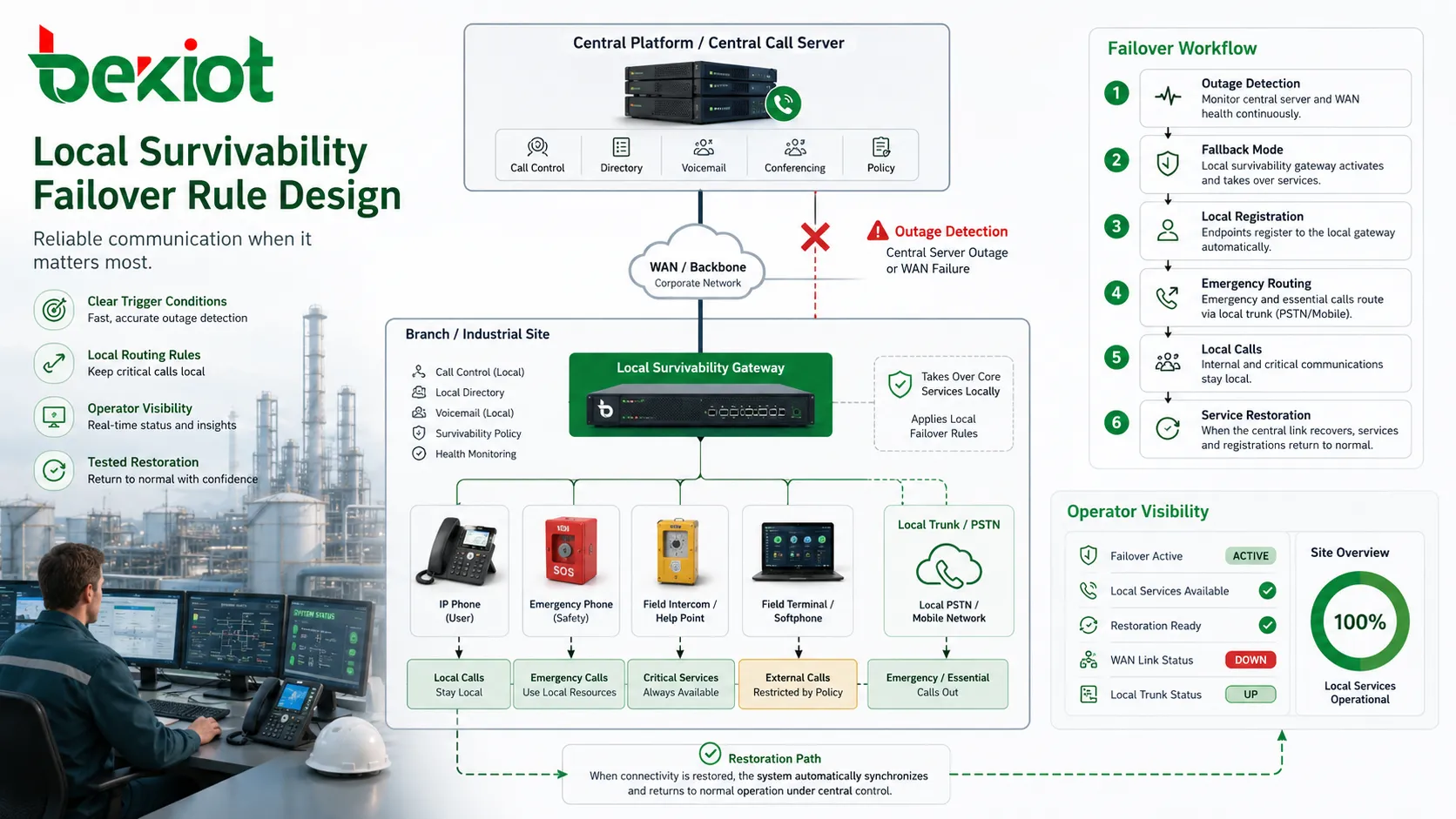
Concevoir des règles de basculement fiables pour les opérateurs
La survivabilité dépend de règles. Le système doit savoir quand entrer en mode de repli, quels services doivent être repris localement, quels numéros doivent utiliser les ressources locales et quand le fonctionnement normal doit reprendre. Si ces règles sont floues, la survivabilité peut créer de la confusion plutôt que de la stabilité.
Les conditions de déclenchement constituent la première question de conception. Un site peut passer en mode survivable lorsqu’il perd le contact avec le serveur d’appels central, lorsque l’enregistrement SIP échoue, lorsque la latence WAN dépasse un seuil ou lorsqu’un trunk principal devient indisponible. Le déclencheur doit être assez précis pour éviter les basculements inutiles, mais assez sensible pour réagir avant une défaillance généralisée.
Les règles de routage sont tout aussi importantes. Les appels locaux doivent rester locaux lorsque c’est approprié. Les appels d’urgence peuvent être envoyés à des opérateurs locaux ou à des trunks de secours. Les appels externes peuvent être limités aux numéros essentiels si la capacité locale est réduite. Les appels vers d’autres sites peuvent être bloqués, reroutés ou traités par des chemins alternatifs. Les opérateurs doivent comprendre ces règles avant une panne.
La confiance vient des tests et de la documentation. Si le personnel ne sait pas ce que signifie le mode survivable, il peut croire que le système est en panne alors qu’il fonctionne correctement. Des indicateurs d’état clairs, des journaux de maintenance, des guides opérateur et des tests réguliers de basculement renforcent la confiance. Une conception que personne ne comprend ne livrera pas toute sa valeur opérationnelle.
Planifier le déploiement pour les architectures de branches et multisites
La survivabilité locale doit être planifiée selon le rôle du site. Une petite agence, une grande usine, une station de transport public, un bâtiment de campus, une installation distante de services publics et un poste de commandement d’urgence n’ont pas besoin du même design. La première étape consiste à identifier quelles fonctions de communication doivent rester disponibles si la plateforme centrale est inaccessible.
Les questions clés sont les suivantes : les extensions locales doivent-elles encore s’appeler ? Les appels d’urgence doivent-ils aller vers un poste local ou un trunk externe ? L’accès au réseau public est-il requis ? Les annonces ou la sonorisation locale sont-elles nécessaires ? Les liens radio ou interphone doivent-ils rester actifs ? Combien d’appels simultanés faut-il supporter ? Combien de temps le site peut-il rester isolé ? Ces questions définissent la taille et la fonction du nœud local de survivabilité.
La conception réseau doit aussi être revue. Les dispositifs locaux doivent pouvoir atteindre le nœud de repli même lorsque le WAN est coupé. La commutation locale, les VLAN, l’adressage IP, le comportement DHCP, la dépendance DNS, l’alimentation de secours et l’emplacement de la passerelle comptent donc tous. Une fonction de survivabilité ne peut pas fonctionner si les terminaux locaux perdent simultanément réseau ou alimentation.
Dans les déploiements multisites, la cohérence de configuration est importante. Chaque site peut avoir ses propres règles de repli, mais la conception globale doit suivre un modèle standard lorsque c’est possible. Les modèles réduisent les erreurs d’ingénierie et facilitent la maintenance. Des exceptions spécifiques peuvent être ajoutées pour les sites à haut risque ou à usage particulier.
Valeur de la supervision opérationnelle et de la maintenance
La survivabilité locale ne doit pas être considérée comme une fonction configurée une fois puis oubliée. Sa valeur dépend de la santé permanente du chemin de repli local. Les équipes de maintenance doivent surveiller l’état des passerelles locales, trunks de secours, comportements d’enregistrement, conditions d’alimentation et versions logicielles. Un nœud hors ligne ou mal configuré peut passer inaperçu jusqu’à une panne réelle.
Les tests réguliers sont essentiels. Les ingénieurs doivent simuler de manière contrôlée l’indisponibilité du serveur central ou la coupure WAN, puis vérifier que les appels locaux, appels d’urgence et routes de repli se comportent comme prévu. Ces tests doivent être documentés, surtout dans les environnements où la sécurité ou la continuité opérationnelle est importante.
La supervision doit aussi inclure les enregistrements d’événements. Lorsqu’un site entre en mode survivable, le système doit générer des journaux ou alarmes pour que les équipes comprennent ce qui s’est produit. Si le basculement se déclenche fréquemment, le problème peut venir d’une instabilité WAN, d’un accès irrégulier au serveur central, de seuils incorrects ou d’un problème réseau local. La survivabilité protège le service, mais une activation fréquente indique une cause sous-jacente à corriger.
Après une panne réelle, les journaux aident à évaluer la performance. Les appels locaux sont-ils restés disponibles ? Les appels d’urgence ont-ils été correctement routés ? Les utilisateurs ont-ils signalé de la confusion ? Le système est-il revenu proprement au mode normal ? Ces questions permettent d’affiner la conception et d’améliorer la résilience future.
Limites courantes à comprendre avant le déploiement
La survivabilité locale est précieuse, mais ce n’est pas une duplication complète du système. Certains services centralisés peuvent être indisponibles pendant l’isolement. Selon l’architecture, cela peut inclure les appels intersites, l’enregistrement centralisé, la recherche dans un annuaire cloud, la conférence avancée, la messagerie vocale centralisée, les files d’appels globales ou le contrôle administrateur distant. Ces limites doivent être expliquées avant le déploiement.
La capacité peut aussi être limitée. Un nœud local de survivabilité peut ne prendre en charge qu’un nombre défini d’utilisateurs, d’appels, de trunks ou de fonctions. Si le site s’attend à ce que tous les utilisateurs travaillent normalement pendant une panne WAN, le système de repli doit être dimensionné en conséquence. Si seules les communications essentielles et d’urgence sont requises, un design plus réduit peut suffire.
Une autre limite concerne la cohérence des données. Pendant le repli, certains journaux d’appels, états de terminaux ou changements de configuration peuvent être stockés localement et synchronisés plus tard, ou ne pas être totalement disponibles pour la plateforme centrale. Le projet doit définir la manière de traiter ces enregistrements et les informations requises pour l’audit ou le reporting.
Comprendre ces limites ne diminue pas l’intérêt de la survivabilité. Cela rend le déploiement plus réaliste. Les meilleures conceptions définissent clairement ce qui survit localement, ce qui dépend du système central et comment utilisateurs et opérateurs doivent agir pendant le fonctionnement dégradé.
Valeur métier à long terme de la résilience au niveau site
La valeur à long terme de la survivabilité locale provient de la réduction du risque opérationnel dans les environnements distribués. Une panne unique peut être rare, mais son coût peut être élevé. La perte de communication peut retarder la maintenance, perturber la production, affecter le service client, affaiblir la réponse d’urgence ou créer des risques de sécurité. La survivabilité réduit la probabilité qu’une panne réseau devienne une défaillance opérationnelle complète.
Pour les organisations possédant de nombreux sites, la valeur augmente encore. Même si chaque site ne subit que des problèmes occasionnels de connectivité, le risque global du réseau peut être important. La capacité de repli local crée un modèle d’exploitation plus résilient, surtout lorsque les sites sont géographiquement dispersés ou dépendants de liens WAN loués.
La survivabilité soutient également la modernisation. Les organisations peuvent évoluer vers des plateformes centralisées ou cloud tout en conservant une protection locale pour les sites critiques. Cela rend la migration moins risquée, car la nouvelle architecture ne supprime pas toute indépendance locale. Elle combine efficacité centralisée et continuité au niveau du site.
En pratique, la survivabilité locale n’est pas seulement une fonction technique. C’est une mesure de continuité d’activité, une couche de soutien à la sécurité et un moyen de rendre l’architecture de communication distribuée plus tolérante aux problèmes réels du réseau.
FAQ
La survivabilité locale est-elle réservée aux grandes organisations ?
Non. Elle est utile pour tout site où la communication doit continuer pendant une panne WAN ou une défaillance du serveur central. Petites agences, installations distantes, stations industrielles, campus et sites de transport peuvent nécessiter un repli local si l’impact métier d’une perte de communication est élevé.
La survivabilité locale remplace-t-elle la redondance centrale ?
Non. La redondance centrale protège la plateforme principale, tandis que la survivabilité locale protège la communication au niveau du site lorsque celui-ci ne peut pas atteindre la plateforme centrale. Elles résolvent deux parties différentes de la résilience et peuvent être utilisées ensemble.
Quels services restent généralement disponibles en mode survivable ?
Les services courants comprennent les appels entre extensions locales, le routage d’urgence, l’accès aux trunks locaux, un repli limité d’enregistrement et des chemins de communication essentiels prédéfinis. Les services centralisés avancés peuvent rester indisponibles s’ils ne sont pas conçus pour fonctionner localement.
À quelle fréquence faut-il tester le basculement de survivabilité ?
La fréquence dépend du niveau de risque, mais les sites critiques doivent tester régulièrement et après des changements majeurs de réseau ou de configuration. Les tests doivent vérifier les appels locaux, routes d’urgence, accès aux trunks, comportement de restauration et visibilité opérateur.
Quelle est l’erreur de déploiement la plus fréquente ?
L’erreur la plus fréquente consiste à activer une fonction de survivabilité sans concevoir tout le workflow de repli. Le projet doit définir les déclencheurs, le routage local, le comportement d’urgence, la capacité, les attentes des utilisateurs, la supervision et les procédures de reprise avant de s’y fier.







