

Maintenir les services en marche lorsqu’un élément tombe en panne
Le basculement est un mécanisme de fiabilité qui transfère automatiquement ou manuellement les opérations d’un composant principal défaillant vers un composant de secours. Il sert à maintenir disponibles les applications, réseaux, serveurs, bases de données, systèmes de communication, services cloud et plateformes industrielles lorsque du matériel, des logiciels, des liens ou des services cessent de fonctionner.
En termes simples, le basculement répond à une question essentielle : si le système principal tombe en panne, qu’est-ce qui prend le relais ? Une architecture bien conçue réduit les temps d’arrêt, protège la continuité de service et aide les organisations à se remettre plus vite des pannes, surcharges, opérations de maintenance ou interruptions imprévues.
Le basculement n’empêche pas toutes les pannes. Sa valeur est d’offrir au système un chemin de reprise préparé lorsque la panne survient.
Signification de base et rôle dans le système
Le basculement est couramment utilisé dans les conceptions à haute disponibilité. Une ressource principale assure le fonctionnement normal, tandis qu’une ou plusieurs ressources de secours restent prêtes à prendre le relais si la ressource principale devient indisponible. Le secours peut être un autre serveur, routeur, nœud de base de données, lien réseau, centre de données, région cloud, système de stockage ou instance applicative.
L’objectif est de réduire l’interruption de service. Au lieu d’attendre que les techniciens réparent le composant défaillant avant de poursuivre, le système redirige le trafic, les charges de travail, les sessions ou les requêtes vers une autre ressource disponible.
Ressources principales et de secours
La ressource principale est le composant actif qui fournit normalement le service. La ressource de secours est prête à prendre le relais lorsque la ressource principale tombe en panne. Dans certains systèmes, elle reste passive jusqu’au déclenchement du basculement. Dans d’autres, plusieurs ressources partagent activement le trafic en même temps.
Par exemple, un site web peut fonctionner sur deux serveurs d’applications. Si le premier serveur échoue, le trafic peut être envoyé au second. Un routeur peut utiliser un lien WAN de secours si la connexion internet principale tombe. Une base de données peut promouvoir une réplique comme nouveau nœud principal lorsque le nœud principal d’origine échoue.
Détection des pannes
Le basculement dépend de la détection des pannes. Le système doit savoir quand le composant principal est en mauvais état. La détection peut utiliser des signaux de battement, des contrôles de santé, la surveillance des liens, des sondes de service, l’état de réplication de la base de données, des tests de réponse applicative ou des contrôles d’accessibilité réseau.
Une bonne détection doit être assez rapide pour réduire l’arrêt de service, mais pas si sensible qu’elle déclenche un basculement inutile lors d’un bref retard ou d’une perte temporaire de paquets. Cet équilibre est important dans la conception réelle des réseaux et des applications.
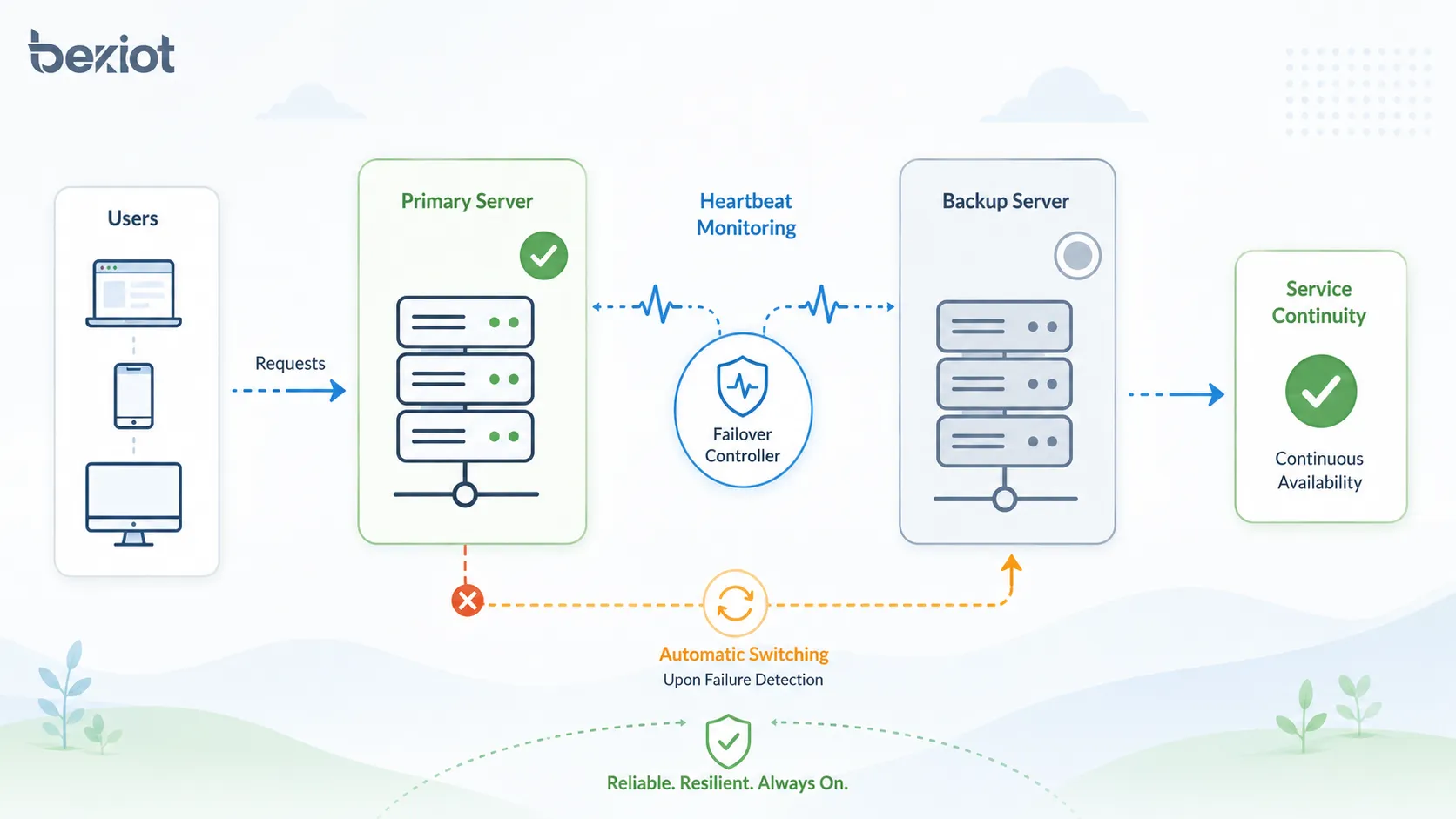
Fonctionnement du processus de basculement
Le processus de basculement comprend généralement la surveillance, la détection de panne, la prise de décision, le changement de service, la redirection du trafic, la vérification de reprise et la journalisation des événements. Les détails varient selon le type de système, mais la logique de base reste similaire.
Lorsque le mécanisme de surveillance détecte que le système principal est indisponible ou dégradé, le contrôleur de basculement active le chemin de secours. Les utilisateurs peuvent subir une courte interruption, mais le service doit continuer via le composant de secours.
Surveillance et contrôles de santé
Les contrôles de santé servent à confirmer qu’un service fonctionne correctement. Un contrôle simple peut seulement vérifier si un serveur répond au ping. Un contrôle plus avancé peut vérifier si l’application traite les requêtes, se connecte à la base de données et renvoie des réponses valides.
Les contrôles au niveau applicatif sont généralement plus fiables que de simples tests réseau. Un serveur peut encore répondre au ping alors que l’application qu’il héberge est figée, surchargée ou incapable d’accéder aux services backend nécessaires.
Passage aux ressources de secours
Une fois la panne confirmée, le système transfère l’exploitation vers la ressource de secours. Cela peut impliquer la modification de tables de routage, la mise à jour d’enregistrements DNS, le déplacement d’une adresse IP virtuelle, la promotion d’une réplique de base de données, l’activation d’un serveur de secours ou la redirection du trafic via un répartiteur de charge.
La méthode de commutation doit correspondre aux exigences métier. Certains systèmes tolèrent quelques minutes d’interruption, tandis que les systèmes critiques peuvent exiger un basculement presque instantané avec un impact minimal sur les utilisateurs.
Vérification du service après la commutation
Après le basculement, le service de secours doit être vérifié. Le système doit confirmer que les utilisateurs peuvent se connecter, que les transactions peuvent continuer, que les données sont disponibles et que les services dépendants fonctionnent correctement.
Cette vérification est importante, car envoyer le trafic vers un composant de secours ne garantit pas automatiquement un fonctionnement normal. Le secours doit être correctement synchronisé, bien configuré et capable de supporter la charge.
Principaux types de basculement
Le basculement peut être conçu de différentes manières selon la criticité du système, le budget, les exigences de performance et les objectifs de reprise. Les modèles les plus courants sont actif-passif, actif-actif, manuel, automatique, local et géographique.
Basculement actif-passif
Dans un basculement actif-passif, un système gère activement le trafic de production tandis qu’un autre attend en mode veille. Si le système actif échoue, le système passif devient actif et prend en charge le service.
Ce modèle est relativement simple et largement utilisé pour les serveurs, pare-feu, bases de données, systèmes PBX, contrôleurs de stockage et passerelles réseau. Son principal avantage est la séparation claire des rôles. Sa limite est que les ressources en veille peuvent être sous-utilisées en fonctionnement normal.
Basculement actif-actif
Dans un basculement actif-actif, deux systèmes ou plus traitent le trafic simultanément. Si l’un échoue, les systèmes restants continuent à servir les utilisateurs et absorbent la charge supplémentaire.
Ce modèle peut améliorer l’utilisation des ressources et l’évolutivité, mais il exige une conception rigoureuse. L’équilibrage de charge, la synchronisation des données, la gestion des sessions, le contrôle des conflits et la planification de capacité deviennent plus complexes.
Basculement manuel et automatique
Le basculement manuel exige qu’un opérateur ou administrateur déclenche la commutation. Il offre un contrôle humain et peut être utile pendant la maintenance, une migration planifiée ou des changements sensibles du système.
Le basculement automatique est déclenché par des règles système. Il est plus rapide et plus adapté aux environnements à haute disponibilité, mais il doit être configuré avec soin pour éviter les faux basculements, les situations de split-brain ou les allers-retours répétés entre nœuds.
Basculement local et géographique
Le basculement local se produit dans le même site, rack, centre de données ou zone réseau. Il protège contre les défaillances locales de serveur, de lien, de module d’alimentation ou d’équipement.
Le basculement géographique transfère le service vers un autre centre de données, une autre région cloud ou un site distant. Il protège contre des incidents plus larges comme l’arrêt d’un centre de données, une perturbation régionale du réseau, une perte d’énergie, un incendie, une inondation ou un incident majeur d’infrastructure.
Fonctions clés d’une conception fiable
Un bon système de basculement ne doit pas seulement commuter vite. Il doit commuter de manière sûre, cohérente et prévisible. Les fonctions les plus importantes incluent la surveillance, la redondance, la synchronisation, le contrôle du trafic, la journalisation et la planification de reprise.
Composants redondants
La redondance signifie disposer de composants de secours avant qu’une panne ne survienne. Ces composants peuvent inclure serveurs, alimentations, liens réseau, routeurs, commutateurs, chemins de stockage, bases de données, instances applicatives et régions cloud.
La redondance doit être réelle. Un serveur de secours connecté à la même alimentation défaillante ou au même commutateur unique n’apporte pas forcément de résilience. Les concepteurs doivent éviter les points de défaillance uniques cachés.
Battement et surveillance d’état
Les signaux de battement aident les systèmes à vérifier si le nœud principal est vivant. Si le nœud de secours cesse de recevoir les messages de battement pendant une période définie, il peut supposer que le nœud principal a échoué.
La conception du battement doit tenir compte du délai réseau, de la perte de paquets et de la fiabilité du lien de gestion. Une mauvaise configuration peut provoquer un split-brain, où deux nœuds pensent tous deux devoir être actifs.
Synchronisation des données
De nombreux systèmes de basculement nécessitent une synchronisation des données entre les nœuds principal et de secours. Cela peut inclure la réplication de base de données, la synchronisation de fichiers, le miroir de stockage, la sauvegarde de configuration ou le partage d’état.
La synchronisation influence la qualité de reprise. Si le secours contient des données anciennes, le basculement peut restaurer le service tout en perdant des transactions récentes. Si la synchronisation est trop lente, les objectifs de point de reprise peuvent ne pas être atteints.
Redirection automatique du trafic
La redirection du trafic permet aux utilisateurs ou systèmes d’atteindre le service de secours après le basculement. Elle peut être réalisée par des répartiteurs de charge, adresses IP virtuelles, protocoles de routage, basculement DNS, politiques SD-WAN ou passerelles applicatives.
La méthode de redirection doit correspondre au temps de reprise attendu. Le basculement DNS peut être simple, mais plus lent à cause du cache. Le répartiteur de charge ou l’IP virtuelle peut être plus rapide dans les environnements locaux à haute disponibilité.
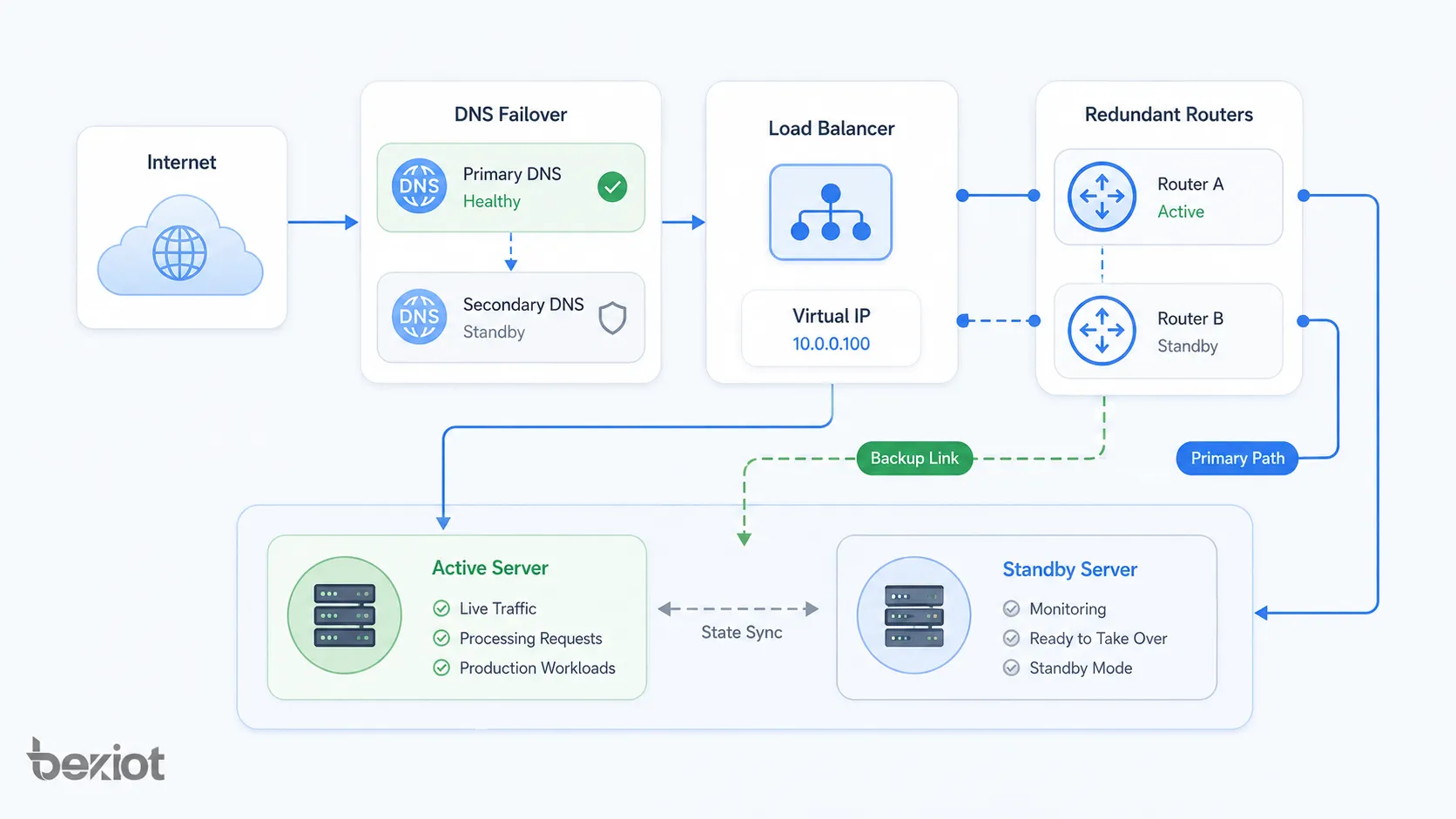
Modèles d’architecture réseau
L’architecture de basculement peut s’appliquer à différentes couches d’un réseau et d’une pile système. Elle peut protéger les liens physiques, chemins de routage, clusters de serveurs, bases de données, régions cloud ou services applicatifs.
Basculement au niveau serveur
Le basculement au niveau serveur utilise deux serveurs ou plus pour fournir le même service. Si un serveur échoue, un autre prend le relais. C’est courant pour les serveurs d’applications, serveurs web, serveurs de fichiers, serveurs de communication et plateformes de gestion.
Il peut utiliser des logiciels de clustering, plateformes de virtualisation, répartiteurs de charge, orchestration de conteneurs ou services de haute disponibilité. La cohérence de configuration entre serveurs est essentielle.
Basculement de lien réseau
Le basculement de lien réseau utilise des chemins réseau de secours lorsque la connexion principale échoue. Les exemples incluent double WAN, fibre de secours, LTE ou 5G de secours, connexions ISP redondantes et commutation de liens SD-WAN.
C’est important pour les agences, sites distants, chaînes de distribution, installations industrielles et systèmes connectés au cloud. Si le lien principal échoue, le lien de secours maintient la communication disponible, même si la bande passante ou la latence change.
Basculement de routeur et de pare-feu
Les routeurs et pare-feu prennent souvent en charge des paires à haute disponibilité. Un équipement peut être actif et l’autre en veille, ou les deux peuvent partager la charge selon la conception. Une adresse de passerelle virtuelle est souvent utilisée afin que les clients n’aient pas à savoir quel appareil physique est actif.
Le basculement de pare-feu doit synchroniser l’état des sessions lorsque c’est possible. Sans synchronisation des sessions, les connexions existantes peuvent être interrompues pendant le basculement, même si les nouvelles connexions continuent normalement.
Basculement de base de données
Le basculement de base de données protège les services de données en passant d’une base principale défaillante à une réplique ou base de secours. Il est utilisé dans les applications d’entreprise, plateformes e-commerce, systèmes financiers, services cloud et plateformes opérationnelles critiques.
Il exige une gestion attentive du retard de réplication, de la cohérence transactionnelle, des conflits d’écriture et de la reconnexion applicative. Une mauvaise conception peut entraîner une perte de données ou des erreurs d’application.
Basculement cloud et multirégion
Le basculement cloud peut transférer les services entre zones, régions ou fournisseurs cloud. Il protège contre les défaillances d’infrastructure locale et soutient les stratégies de reprise après sinistre.
Le basculement multirégion peut nécessiter une gestion globale du trafic, des bases de données répliquées, la synchronisation du stockage objet, la disponibilité du service d’identité et des procédures de reprise testées. La conception doit correspondre aux objectifs de temps et de point de reprise.
Métriques et objectifs de planification
La planification du basculement est souvent guidée par des métriques de disponibilité et de reprise. Ces métriques aident les organisations à déterminer le niveau de redondance nécessaire et le temps d’arrêt ou la perte de données acceptable.
| Métrique | Signification | Pourquoi c’est important |
|---|---|---|
| RTO | Objectif de temps de reprise | Temps maximal acceptable pour restaurer le service après une panne |
| RPO | Objectif de point de reprise | Quantité maximale acceptable de perte de données mesurée dans le temps |
| MTTR | Temps moyen de réparation | Temps moyen nécessaire pour restaurer un composant défaillant |
| MTBF | Temps moyen entre pannes | Temps moyen de fonctionnement entre deux pannes |
| Disponibilité | Pourcentage de temps pendant lequel un service est opérationnel | Indique la performance globale de disponibilité du service |
Objectif de temps de reprise
L’objectif de temps de reprise définit la rapidité avec laquelle un service doit être restauré après une panne. Un outil interne de reporting non critique peut tolérer plusieurs heures d’arrêt, tandis qu’un système de paiement, une plateforme d’urgence ou un système de contrôle de production peut exiger une reprise en secondes ou en minutes.
Un RTO plus faible exige généralement davantage d’investissement dans l’automatisation, la redondance, la surveillance et l’infrastructure. La conception doit correspondre à l’impact métier, plutôt que supposer que tous les systèmes nécessitent le même niveau de protection.
Objectif de point de reprise
L’objectif de point de reprise définit la quantité de perte de données acceptable. Si une organisation ne peut tolérer que quelques secondes de données perdues, elle peut nécessiter une réplication quasi temps réel. Si elle peut tolérer plusieurs heures, une sauvegarde planifiée peut suffire.
Le RPO est particulièrement important pour les bases de données, systèmes de fichiers, plateformes transactionnelles, dossiers clients et journaux opérationnels. Un basculement sans planification des données peut restaurer le service tout en créant une perte métier inacceptable.
Avantages pour l’activité et l’exploitation
Le basculement apporte de la valeur parce que l’arrêt de service affecte le chiffre d’affaires, la sécurité, la productivité, la confiance des clients et la continuité opérationnelle. Une stratégie bien conçue aide les organisations à maintenir le service lors de pannes imprévues et de maintenances planifiées.
Meilleure disponibilité du service
Le principal avantage est l’amélioration de la disponibilité. Quand un composant principal échoue, le composant de secours continue le service. Cela réduit l’arrêt et aide les utilisateurs à continuer leur travail.
La haute disponibilité est importante pour les services en ligne, systèmes de communication, plateformes de santé, réseaux de transport, automatisation industrielle, systèmes financiers et applications destinées au public.
Réduction du risque opérationnel
Le basculement réduit le risque qu’une seule défaillance arrête tout le système. C’est particulièrement important pour les systèmes avec point de défaillance unique, comme un seul lien internet, serveur, base de données ou passerelle.
En ajoutant des chemins de secours et une logique de reprise automatisée, les organisations réduisent l’impact des pannes matérielles, interruptions réseau, crashs logiciels et coupures de maintenance.
Plus de flexibilité de maintenance
Le basculement peut soutenir la maintenance planifiée. Les administrateurs peuvent déplacer le service d’un nœud à un autre, mettre à jour le système principal, tester les changements puis revenir lorsque le travail est terminé.
Cela réduit le besoin de longues fenêtres de maintenance. Les mises à niveau deviennent aussi plus sûres, car le service peut rester disponible grâce aux ressources de secours.
Confiance utilisateur renforcée
Les utilisateurs ne voient pas forcément le processus de basculement, mais ils remarquent que les services restent disponibles. Les systèmes fiables améliorent la confiance client, la productivité des employés et la confiance dans l’infrastructure numérique.
Pour les plateformes critiques de communication, industrielles et métier, la disponibilité n’est pas seulement une métrique technique. Elle fait partie de l’expérience de service.
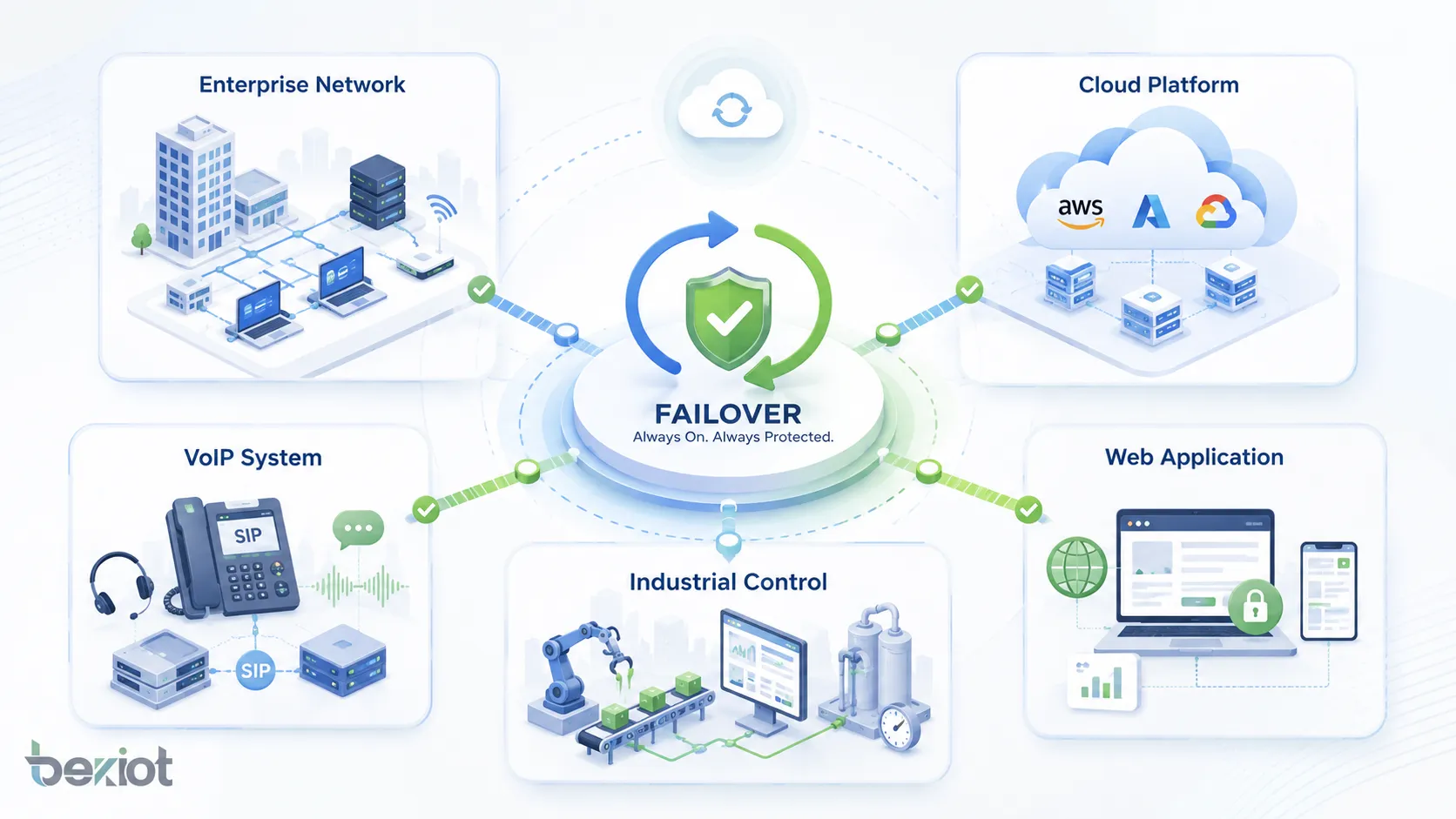
Applications dans différents systèmes
Le basculement est utilisé partout où la continuité compte. La conception exacte dépend du type de système, mais l’objectif reste le même : éviter l’interruption du service lorsqu’un élément échoue.
Réseaux d’entreprise
Les réseaux d’entreprise utilisent le basculement pour les liens internet, pare-feu, routeurs, commutateurs, tunnels VPN, contrôleurs sans fil et connectivité des agences. Si un chemin échoue, le trafic peut passer à un autre chemin.
Dans les organisations multisites, il aide les bureaux distants à rester connectés aux services cloud, centres de données, systèmes de communication et applications métier.
Centres de données et plateformes cloud
Les centres de données utilisent le basculement pour les serveurs, le stockage, les bases de données, les clusters de virtualisation, les systèmes électriques, le refroidissement et les fabrics réseau. Les plateformes cloud utilisent zones de disponibilité, basculement régional, répartiteurs de charge, groupes d’auto-scaling et répliques de bases de données gérées.
Ces conceptions aident les applications à survivre aux défaillances matérielles, d’hôte, de rack ou même de service régional lorsqu’elles sont correctement planifiées.
Systèmes VoIP et de communication
Les systèmes VoIP et SIP peuvent utiliser le basculement pour les serveurs SIP, plateformes PBX, passerelles, SBC, trunks SIP, enregistrements DNS SRV, serveurs média et liens réseau. Si un serveur ou un trunk échoue, les appels peuvent être routés par un chemin de secours.
C’est important pour les communications d’entreprise, car une panne des services vocaux peut affecter le contact client, la coordination interne, les appels d’urgence et les opérations de service.
Technologies industrielles et opérationnelles
Les environnements industriels peuvent utiliser le basculement pour les serveurs SCADA, réseaux de contrôle, plateformes de surveillance, postes HMI, historians, passerelles industrielles et liens de communication. L’objectif est de maintenir disponibles la production, la surveillance et les opérations liées à la sécurité.
La conception industrielle doit tenir compte des communications déterministes, de la compatibilité des équipements, des conditions environnementales et des procédures sûres. La commutation automatique ne doit pas créer un comportement machine dangereux.
Applications web et services en ligne
Les applications web utilisent le basculement via répartiteurs de charge, serveurs applicatifs répliqués, répliques de bases de données, services CDN, basculement DNS et déploiement multirégion. Ces méthodes aident les sites et API à rester disponibles pendant une panne serveur ou réseau.
Pour l’e-commerce, la banque, le SaaS, le streaming et les portails clients, le basculement peut protéger le chiffre d’affaires et l’expérience utilisateur pendant les interruptions imprévues.
Défis et risques courants
Le basculement améliore la résilience, mais une mauvaise conception peut créer de nouveaux problèmes. Le système de secours doit être testé, mis à jour, synchronisé et correctement dimensionné. Sinon, le basculement peut échouer au moment où il est le plus nécessaire.
Faux basculement
Un faux basculement se produit lorsque le système passe au secours alors que le service principal n’est pas réellement en panne. Il peut être causé par une perte temporaire de paquets, une réponse lente, une surveillance surchargée ou des seuils trop agressifs.
Il peut interrompre les utilisateurs inutilement. Les contrôles de santé doivent confirmer une vraie panne de service avant la commutation.
Situation de split-brain
Une situation de split-brain survient lorsque deux nœuds pensent tous deux être le principal actif. Cela peut arriver lorsque la communication de battement échoue alors que les deux systèmes continuent de fonctionner.
Le split-brain est dangereux dans les bases de données, le stockage et les systèmes en cluster, car il peut causer une corruption de données ou des écritures conflictuelles. Le quorum, le fencing et une bonne conception de cluster réduisent ce risque.
Problèmes de capacité du secours
Une ressource de secours doit avoir assez de capacité pour gérer la charge après le basculement. Si elle est trop petite, le service peut rester techniquement en ligne mais fonctionner lentement.
La planification de capacité doit tenir compte du pic de charge, de la croissance, du mode dégradé et de la possibilité que plusieurs pannes se produisent en même temps.
Plans de reprise non testés
Une conception de basculement jamais testée n’est pas fiable. Dérive de configuration, certificats expirés, sauvegardes obsolètes, changements de pare-feu, cache DNS, licences manquantes ou versions logicielles anciennes peuvent empêcher une reprise réussie.
Des exercices réguliers sont nécessaires. Les tests doivent inclure, lorsque c’est possible, des scénarios de basculement planifié et de panne non planifiée.
Bonnes pratiques pour un déploiement fiable
Le basculement doit être conçu comme une partie d’une stratégie plus large de haute disponibilité et de reprise après sinistre. Il doit inclure planification d’architecture, surveillance, documentation, tests et amélioration continue.
Identifier d’abord les services critiques
Tous les systèmes n’ont pas besoin du même niveau de basculement. Les organisations doivent identifier quels services sont critiques, comment l’arrêt affecte les opérations et quels objectifs de reprise sont requis.
Cela aide à prioriser les investissements. Les systèmes critiques peuvent nécessiter basculement automatique et redondance géographique, tandis que les systèmes moins critiques peuvent seulement demander sauvegarde et reprise manuelle.
Supprimer les points de défaillance uniques cachés
Le basculement peut être affaibli par des dépendances cachées. Un serveur de secours peut dépendre du même stockage, de la même alimentation, du même commutateur réseau, du même service DNS ou du même système d’authentification que le serveur principal.
La revue d’architecture doit identifier ces dépendances. La résilience réelle exige une redondance sur tout le chemin de service, et pas seulement sur la couche applicative visible.
Maintenir les configurations synchronisées
Les systèmes principal et de secours doivent utiliser une configuration cohérente. Des différences de version logicielle, règles de pare-feu, certificats, politiques de routage, données utilisateurs ou paramètres applicatifs peuvent provoquer l’échec du basculement.
Les outils de gestion de configuration, modèles, sauvegardes et contrôles de changement aident à maintenir l’alignement. Après tout changement majeur, l’état de préparation au basculement doit être vérifié à nouveau.
Tester régulièrement le basculement
Les tests réguliers confirment que le basculement fonctionne en conditions réelles. Ils doivent vérifier temps de détection, temps de commutation, cohérence des données, comportement applicatif, accès utilisateur, journalisation et procédure de retour.
Les tests doivent être documentés. Chaque test doit consigner ce qui a été testé, ce qui s’est passé, ce qui a échoué et quelles améliorations sont nécessaires.
Retour arrière et reprise après basculement
Le basculement n’est qu’une partie du processus de reprise. Après réparation du système principal, l’organisation doit décider si le service doit revenir en arrière et comment procéder. Ce processus s’appelle le retour arrière ou failback.
Quand revenir au système principal
Le retour ne doit pas être trop rapide. Le système principal d’origine doit être entièrement réparé, testé, synchronisé et vérifié avant que le trafic soit renvoyé. Un retour précipité peut provoquer une nouvelle panne et une autre interruption.
Certaines organisations choisissent de garder le système de secours actif jusqu’à la prochaine fenêtre de maintenance. Cela permet un retour contrôlé plutôt qu’une commutation immédiate.
Synchronisation des données et de l’état
Avant le retour, les données créées pendant l’exploitation du secours doivent être synchronisées vers le système principal d’origine. C’est particulièrement important pour les bases de données, fichiers, transactions, sessions utilisateur et changements de configuration.
Sans synchronisation correcte, le retour peut causer une perte de données, des enregistrements obsolètes ou un comportement de service incohérent.
Revue après incident
Après un événement de basculement, les équipes doivent examiner ce qui s’est passé. La revue doit inclure la cause de la panne, le temps de détection, le résultat de la commutation, l’impact utilisateur, la performance du secours, le processus de communication et les actions d’amélioration.
Cela transforme le basculement d’un événement ponctuel de reprise en un processus continu d’amélioration de la fiabilité.
FAQ
Qu’est-ce que le basculement ?
Le basculement est un mécanisme de fiabilité qui transfère services, trafic, charges de travail ou opérations d’un composant principal défaillant vers un composant de secours. Il sert à réduire les temps d’arrêt et à maintenir la continuité de service.
Quelle est la différence entre basculement et sauvegarde ?
La sauvegarde conserve des données ou configurations pour la récupération. Le basculement transfère le service actif vers une autre ressource lorsqu’une panne se produit. La sauvegarde aide à restaurer les informations, tandis que le basculement aide à garder le service en marche.
Qu’est-ce que le basculement actif-passif ?
Le basculement actif-passif utilise un système actif et un système en veille. Le système en veille prend le relais uniquement lorsque le système actif échoue ou est mis hors ligne pour maintenance.
Qu’est-ce que le basculement actif-actif ?
Le basculement actif-actif utilise plusieurs systèmes qui traitent le trafic en même temps. Si l’un échoue, les autres continuent à servir les utilisateurs et prennent la charge supplémentaire.
Où le basculement est-il couramment utilisé ?
Il est couramment utilisé dans les réseaux d’entreprise, plateformes cloud, centres de données, bases de données, applications web, systèmes VoIP, pare-feu, routeurs, systèmes de stockage et plateformes de contrôle industriel.
Comment tester le basculement ?
Il peut être testé en simulant la panne du système principal, en déconnectant des chemins réseau de façon contrôlée, en arrêtant des nœuds de test, en déclenchant un basculement de maintenance, en vérifiant la commutation du service, en contrôlant la cohérence des données et en examinant les journaux après reprise.







