Un cluster est un groupe d’ordinateurs, de serveurs, de passerelles, d’équipements, d’applications ou de nœuds réseau connectés qui travaillent ensemble comme un système coordonné. Au lieu de dépendre d’une unité autonome, une conception en cluster répartit les charges, améliore la disponibilité, prend en charge la bascule et permet aux services de continuer lorsqu’une partie du système devient indisponible.
Le mot « cluster » est utilisé dans de nombreux domaines, notamment l’infrastructure IT, le cloud computing, les bases de données, les plateformes de communication, la téléphonie, les réseaux radio, l’automatisation industrielle, le stockage et l’edge computing. Même si la conception technique varie, l’idée reste la même : plusieurs composants coopèrent pour rendre l’ensemble plus fiable, plus extensible et plus facile à gérer.

L’idée de base derrière les systèmes groupés
Dans un système autonome simple, un seul serveur ou équipement assure le service. Si cette unité tombe en panne, le service peut s’arrêter. Si la demande augmente, elle peut être surchargée. Si une maintenance est nécessaire, il peut être difficile d’éviter une interruption.
Un système en cluster modifie ce modèle. Plusieurs nœuds sont reliés par le réseau et gérés selon des règles communes. Un nœud peut traiter la charge actuelle, un autre peut attendre en secours, ou tous les nœuds peuvent traiter le trafic ensemble. Le choix dépend de l’objectif du système.
Par exemple, dans une plateforme de communication d’entreprise, plusieurs serveurs peuvent partager l’enregistrement des utilisateurs, le routage d’appels, l’enregistrement ou le traitement média. Dans un environnement Radio over IP, plusieurs passerelles peuvent relier des canaux radio distribués, des centres de dispatching et des réseaux IP pour maintenir la communication entre sites.
Comment les nœuds groupés travaillent ensemble
Participation des nœuds
Un nœud est une unité participante dans le système. Il peut s’agir d’un serveur physique, d’une machine virtuelle, d’une passerelle, d’un contrôleur, d’un équipement de stockage, d’un terminal de communication ou d’un service logiciel. Chaque nœud possède un rôle défini et communique avec les autres par le réseau.
Certains nœuds peuvent remplir la même fonction, tandis que d’autres ont des tâches spécialisées. Dans une base de données, un nœud peut accepter les écritures et d’autres répliquer les données. Dans un système de communication, un nœud peut gérer la signalisation tandis qu’un autre traite le média, l’enregistrement ou l’accès passerelle.
Heartbeat et contrôle de santé
De nombreux clusters utilisent des signaux heartbeat pour vérifier que les nœuds sont actifs. Un heartbeat est un message d’état échangé régulièrement entre nœuds ou envoyé à un contrôleur de gestion. Si un nœud cesse de répondre, le système considère qu’il peut être défaillant.
Le contrôle de santé peut aussi surveiller l’utilisation CPU, la mémoire, l’état réseau, la réponse applicative, les processus, l’espace disque, la connexion de passerelle ou l’enregistrement des équipements. Cela aide à décider si un nœud doit continuer à servir le trafic ou être retiré temporairement.
Répartition de la charge
Certains clusters répartissent le travail entre plusieurs nœuds au moyen d’équilibreurs de charge, de politiques de routage, de files partagées, de bases distribuées ou d’une coordination applicative. L’objectif est d’éviter qu’un nœud soit saturé alors que d’autres restent inactifs.
La répartition de charge peut améliorer la performance et l’évolutivité. Elle nécessite toutefois une bonne gestion des sessions, de la synchronisation des données, de la capacité réseau et de la supervision. Une méthode mal conçue peut provoquer une charge inégale ou une instabilité de service.
Comportement de bascule
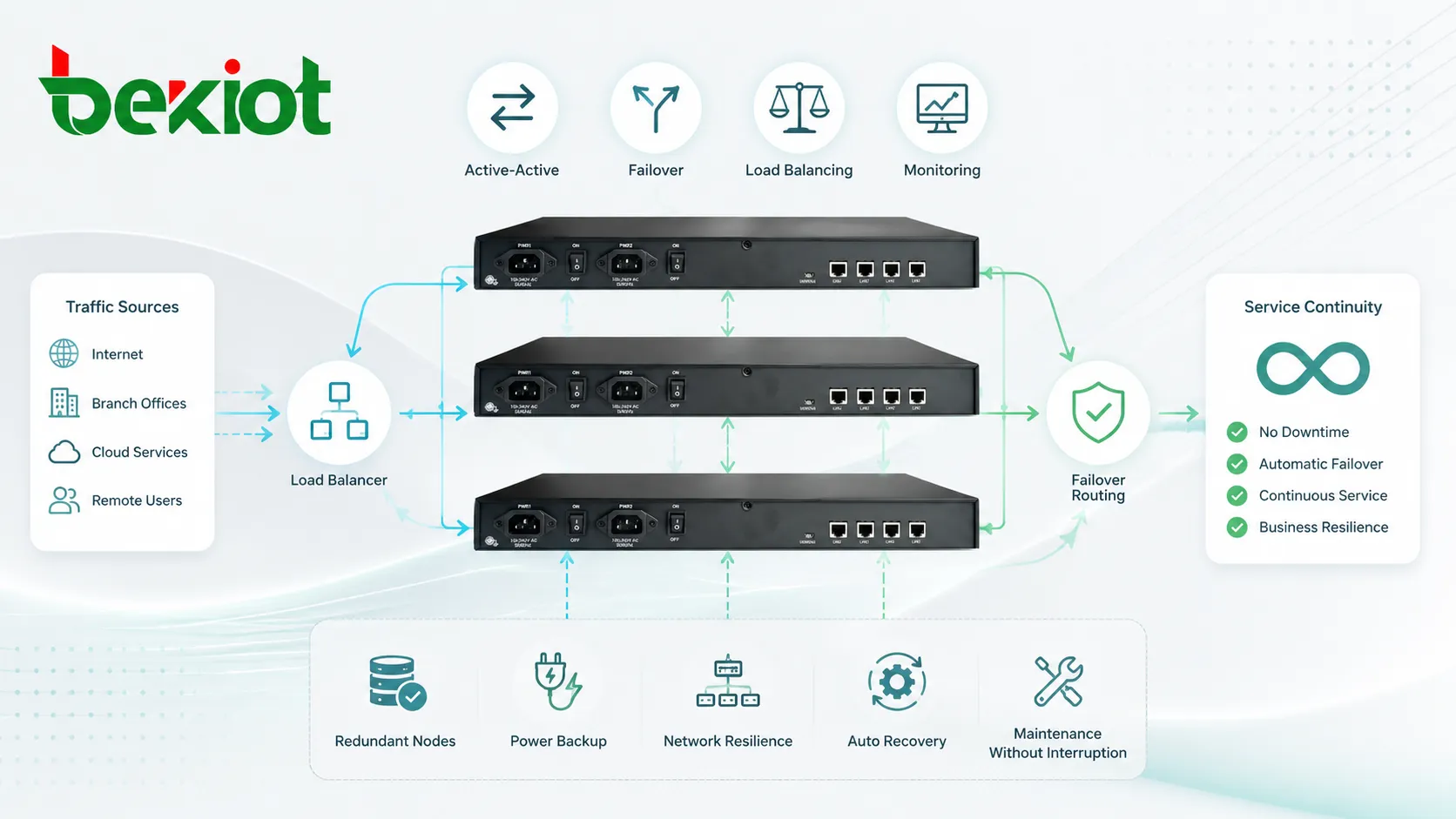
La bascule signifie que lorsqu’un nœud échoue, un autre reprend son rôle. Dans une conception actif-passif, le nœud de secours peut rester inactif jusqu’à la panne du nœud actif. Dans une conception actif-actif, plusieurs nœuds servent déjà le trafic et peuvent absorber une charge supplémentaire lorsqu’un nœud tombe hors ligne.
La bascule doit être testée soigneusement. Un nœud de secours n’est utile que s’il dispose de la bonne configuration, de données à jour, de l’accès réseau, de la capacité de licence et de l’état applicatif nécessaires pour continuer le service.
Une conception en cluster ne consiste pas seulement à ajouter du matériel. Elle consiste à coordonner les nœuds afin de gérer les pannes, la croissance et la maintenance sans interruption inutile.
Modèles d’architecture courants
Conception actif-passif
Dans une conception actif-passif, un nœud fournit le service pendant qu’un autre attend en secours. Si le nœud actif tombe en panne, le nœud passif prend le relais. Ce modèle est fréquent lorsque la cohérence et une bascule contrôlée sont plus importantes que l’utilisation simultanée de tous les nœuds.
Son avantage est la simplicité. Son inconvénient est que les ressources de secours peuvent rester sous-utilisées en fonctionnement normal. Pour les systèmes critiques, cette capacité réservée est souvent acceptable car elle améliore la continuité.
Conception actif-actif
Dans une conception actif-actif, plusieurs nœuds fournissent le service en même temps. Le trafic ou les tâches sont distribués entre eux. Si un nœud échoue, les autres continuent à servir les utilisateurs, même si la capacité totale peut diminuer.
Ce modèle améliore l’utilisation des ressources et l’évolutivité. Il est souvent utilisé dans les plateformes cloud, les applications web, les systèmes de communication, les bases de données distribuées et les plateformes de services multi-nœuds.
Déploiement avec équilibrage de charge
Un déploiement avec équilibrage de charge utilise un composant frontal pour distribuer le trafic vers plusieurs nœuds backend. L’équilibreur peut utiliser des règles comme le round-robin, le moins de connexions, l’état de santé, l’adresse source, la priorité de service ou la localisation géographique.
Cette conception est courante pour les services web, plateformes SIP, API, serveurs applicatifs, systèmes média et portails d’entreprise. L’équilibreur lui-même doit aussi être redondant, sinon il devient un point de défaillance unique.
Conception edge distribuée
Certains systèmes placent les nœuds dans différents lieux plutôt que dans un seul centre de données. C’est courant dans les communications de succursales, sites industriels, réseaux de transport, intégration radio, plateformes IoT et sécurité publique.
L’edge distribué réduit la dépendance à un site central et peut améliorer la réponse locale. Il exige cependant une synchronisation fiable, une supervision à distance, des contrôles de sécurité et des procédures de maintenance claires.
Pourquoi les organisations utilisent cette conception
Disponibilité plus élevée
La disponibilité est l’une des principales raisons d’utiliser des systèmes groupés. Si une unité autonome tombe en panne, le service peut s’arrêter. Si plusieurs nœuds coordonnés sont disponibles, un autre nœud peut poursuivre le service ou reprendre la charge affectée.
C’est important pour les plateformes de communication, services d’urgence, applications métier, systèmes financiers, systèmes de santé, contrôle industriel et services clients, où les interruptions ont un impact opérationnel ou commercial.
Évolutivité pour la croissance
Lorsque la demande augmente, les organisations peuvent avoir besoin de plus de traitement, de capacité d’appels, de débit de base de données, de stockage, de canaux passerelle ou de points de service. Un cluster permet d’augmenter la capacité en ajoutant des nœuds au lieu de remplacer tout le système.
L’évolutivité est particulièrement utile lorsque le trafic change dans le temps. Un système peut commencer petit et s’étendre à mesure que les sites, utilisateurs, canaux, services ou besoins clients augmentent.
Maintenance avec moins de perturbation
Les clusters facilitent la maintenance. Les administrateurs peuvent retirer un nœud du service, le mettre à jour, le tester puis le remettre en production pendant que les autres nœuds continuent à traiter le trafic.
Cela ne supprime pas la planification. La maintenance doit toujours considérer compatibilité, synchronisation, sessions utilisateurs, bascule et rollback. Mais la conception offre plus de souplesse qu’un système à nœud unique.
Meilleure utilisation des ressources
Dans les systèmes actif-actif ou équilibrés, plusieurs nœuds partagent le travail. Cela améliore l’utilisation des ressources car la capacité n’est pas limitée à une seule machine ou à un seul équipement.
Par exemple, plusieurs serveurs applicatifs peuvent servir plus d’utilisateurs qu’un seul serveur. Plusieurs passerelles média peuvent prendre en charge plus de canaux vocaux. Plusieurs nœuds de stockage peuvent offrir plus de capacité et de résilience.
Résilience de service renforcée
La résilience signifie que le système peut continuer à fonctionner sous stress, panne partielle, maintenance ou variation de trafic. Le cluster aide en répartissant les responsabilités et en réduisant la dépendance à un composant unique.
Dans les environnements critiques, la résilience doit aussi inclure alimentation de secours, redondance réseau, séparation géographique, supervision, durcissement de sécurité et procédures de reprise testées.
Composants techniques importants
Configuration partagée
Les nœuds ont besoin d’une configuration cohérente pour se comporter de façon prévisible. Cela peut inclure paramètres réseau, données utilisateurs, règles de routage, certificats, paramètres de service, informations de licence et politiques applicatives.
Si les configurations divergent, la bascule ou le partage de charge peuvent devenir peu fiables. Une gestion centralisée de configuration ou un déploiement automatisé réduit ce risque.
Synchronisation des données
Certains systèmes exigent une synchronisation des données entre nœuds. Cela peut inclure sessions utilisateurs, états d’appels, enregistrements de base de données, état des files, enregistrements d’équipements, messagerie vocale, permissions ou alarmes.
La conception de synchronisation est critique. Si les données ne sont pas à jour, un nœud de secours peut reprendre sans fournir l’état attendu. Si la synchronisation est trop lourde, elle peut créer une surcharge de performance.
Quorum et protection split-brain
Dans certains clusters, le quorum sert à déterminer quels nœuds sont autorisés à prendre des décisions. Cela aide à éviter les situations de split-brain, où deux parties du système pensent être actives en même temps après une séparation réseau.
Le split-brain peut être dangereux car il peut provoquer données contradictoires, contrôle de service dupliqué ou bascule instable. Un bon quorum, le fencing et la redondance réseau réduisent ce risque.
Supervision et alertes
La supervision est essentielle car les clusters peuvent masquer des pannes partielles. Un service peut paraître en ligne même si un nœud, lien, disque, passerelle ou processus a échoué.
Les administrateurs doivent surveiller santé des nœuds, distribution du trafic, événements de bascule, synchronisation, ressources, journaux d’erreurs et indicateurs de service. Les alertes doivent indiquer non seulement qu’un problème existe, mais aussi quel composant nécessite une action.
Contrôle de sécurité
Les systèmes groupés ont généralement plus de communications internes que les systèmes autonomes. Les nœuds peuvent échanger état, configuration, données, identifiants ou messages de contrôle. Ces canaux doivent être protégés par authentification, chiffrement, segmentation et contrôle d’accès.
L’accès administratif doit également être contrôlé. Si un nœud est compromis, l’attaquant ne doit pas obtenir automatiquement le contrôle de tout l’environnement.
Scénarios de communication et de passerelles
Dans les réseaux de communication, le concept de cluster apparaît souvent dans les plateformes PBX, serveurs SIP, systèmes de dispatching, passerelles, réseaux Radio over IP, plateformes d’enregistrement, centres de contact et systèmes de communication d’urgence. Ces services exigent de la continuité, car une panne de communication peut affecter les opérations, la sécurité ou le service client.
Pour l’intégration radio et dispatching, une conception de passerelles en cluster peut relier plusieurs canaux radio, réseaux IP et centres de contrôle. Un groupe de passerelles peut fournir extension de canaux, bascule, accès distant et gestion centralisée entre sites.
Par exemple, la passerelle en cluster de la série BK-ROIP de Becke Telcom peut être utilisée dans des projets où les systèmes radio doivent se connecter à des plateformes de dispatching IP, à des centres de commandement multi-sites ou à des réseaux d’entreprise. Dans ces scénarios, la couche passerelle relie voix radio, transmission IP et workflows de dispatching tout en gardant la solution évolutive et plus facile à gérer.
Applications dans différents secteurs
Systèmes IT d’entreprise
Les entreprises utilisent des serveurs en cluster pour applications métier, bases de données, services fichiers, e-mail, plateformes d’identité et portails internes. Ces systèmes doivent rester disponibles lors de pannes matérielles, mises à jour ou pics de trafic.
Pour l’IT d’entreprise, les objectifs principaux sont le temps de fonctionnement, la performance prévisible, la maintenance plus facile et la continuité d’activité. La conception doit correspondre à l’importance de chaque application.
Cloud et centres de données
Les plateformes cloud dépendent fortement de ressources groupées. Nœuds de calcul, nœuds de stockage, contrôleurs réseau et services applicatifs sont distribués afin que les charges puissent évoluer et se rétablir après panne.
Dans les centres de données, cette conception prend en charge haute disponibilité, mutualisation des ressources, virtualisation, orchestration de conteneurs et migration automatique de charges.
Téléphonie et communications unifiées
Les plateformes vocales peuvent utiliser des serveurs groupés pour l’enregistrement, le routage d’appels, les services média, la messagerie vocale, l’enregistrement, les files de centre de contact ou le contrôle de trunks SIP. Cela réduit le risque qu’une panne de serveur interrompe tous les utilisateurs.
Pour les entreprises multi-sites, les nœuds de communication distribués améliorent aussi la survivabilité locale. Une succursale peut continuer ses communications internes même si la connexion au site central est temporairement indisponible.
Installations industrielles et énergétiques
Les usines, utilities, sites pétroliers et gaziers, mines, ports et installations électriques peuvent utiliser des systèmes groupés pour supervision, dispatching, gestion d’alarmes, intégration radio, contrôle d’accès et communication de salle de contrôle.
Dans ces environnements, disponibilité et résilience sont particulièrement importantes. Le système doit être planifié avec alimentation redondante, protection réseau, conditions environnementales et procédures de maintenance.
Sécurité publique et réponse d’urgence
Les organisations d’urgence peuvent utiliser serveurs de communication groupés, plateformes de dispatching, passerelles radio, systèmes d’enregistrement et outils de notification. L’objectif est de maintenir la communication lorsque la demande augmente ou qu’une partie de l’infrastructure échoue.
Ces systèmes doivent être testés en conditions réalistes, avec bascule, alimentation de secours, volume d’appels élevé, coordination multi-agences et perturbation réseau.

Planifier la bonne configuration
Définir d’abord l’objectif du service
Avant de choisir une conception en cluster, les organisations doivent définir l’objectif du service. Il peut s’agir de haute disponibilité, partage de charge, redondance géographique, flexibilité de maintenance, extension de canaux, reprise après sinistre ou intégration multi-sites.
Chaque objectif conduit à une architecture différente. Un système conçu surtout pour la bascule n’est pas forcément identique à un système conçu pour l’échelle de performance.
Identifier les points de défaillance
Un cluster peut encore échouer si d’autres composants ne sont pas redondants. Alimentation, commutateurs, routeurs, stockage, pare-feu, équilibreurs, licences, bases de données et plateformes de gestion peuvent devenir des points uniques de défaillance.
La planification doit aller au-delà des nœuds eux-mêmes. Le chemin complet du service doit être examiné.
Vérifier la compatibilité applicative
Toutes les applications ou tous les équipements ne sont pas conçus pour le clustering. Certains systèmes nécessitent licences spéciales, support de base de données, logique de synchronisation, stockage partagé ou architecture propre au fournisseur.
La compatibilité doit être confirmée avant le déploiement. Une conception attrayante sur papier peut échouer si l’application ne prend pas en charge l’actif-actif ou la synchronisation d’état.
Tester le comportement de reprise
La bascule doit être testée avant la production. Les tests doivent inclure panne de nœud, interruption réseau, redémarrage de service, retard de base de données, perte d’alimentation, mode maintenance et retour à l’état normal.
Les tests de reprise révèlent des problèmes cachés comme bascule lente, synchronisation incomplète, routage incorrect ou perte de session utilisateur.
Défis courants
Un défi fréquent est la complexité. Plus de nœuds, plus de liens et plus de règles de synchronisation créent plus d’éléments à configurer et surveiller. Un cluster mal géré peut devenir plus difficile à dépanner qu’un système autonome simple.
Un autre défi est la fausse confiance. Certaines organisations pensent qu’ajouter des nœuds crée automatiquement de la haute disponibilité. En réalité, la conception complète doit inclure redondance, supervision, logique de bascule, reprise testée et maintenance qualifiée.
Le coût doit aussi être pris en compte. Nœuds supplémentaires, licences, stockage, commutateurs, passerelles, modules logiciels et support peuvent augmenter le coût du projet. L’investissement doit correspondre au risque métier lié à l’indisponibilité ou à une capacité limitée.
Un système en cluster doit être conçu autour d’exigences réelles de service, et non autour de l’idée que plus de nœuds signifient automatiquement plus de fiabilité.
Maintenance et opérations
La maintenance régulière doit inclure contrôle de santé des nœuds, revue de configuration, validation des sauvegardes, tests de bascule, analyse des journaux, supervision de performance et mises à jour de sécurité. Un cluster jamais testé peut échouer au moment le plus critique.
Les administrateurs doivent aussi surveiller la dérive de configuration. Si un nœud est mis à jour manuellement et pas un autre, le comportement peut devenir incohérent. Les outils automatisés et le contrôle de changement documenté réduisent ce risque.
La capacité doit être revue dans le temps. Si un nœud tombe en panne, les nœuds restants doivent avoir assez de capacité pour les charges critiques. Sinon, la bascule peut maintenir le service en ligne avec une performance inacceptable.
Comment choisir une solution adaptée
La bonne solution dépend du type de charge, de l’importance du service, de l’échelle des utilisateurs, de la distribution des sites, des exigences de reprise et du budget. Une petite application de bureau peut nécessiter une simple sauvegarde, tandis qu’une plateforme de communication carrier-grade peut exiger une redondance actif-actif multi-sites.
Pour les projets de communication, le choix doit considérer capacité d’appels, capacité de canaux, compatibilité SIP, traitement média, intégration radio, redondance de passerelles, gestion centralisée, journalisation et comportement de bascule. Si la solution relie radio, dispatching IP et communications d’entreprise, l’évolutivité des passerelles et la résilience par site deviennent essentielles.
Les organisations doivent également envisager la maintenance à long terme. Une solution doit être compréhensible, documentée, supervisée et supportable par l’équipe responsable de l’exploitation quotidienne.
FAQ
Une petite entreprise peut-elle utiliser des systèmes en cluster ?
Oui. Une petite entreprise n’a pas forcément besoin d’une plateforme multi-nœuds complexe, mais elle peut utiliser des conceptions simples de haute disponibilité comme pare-feu redondants, serveurs de secours, stockage répliqué ou services cloud managés.
Le clustering exige-t-il toujours du matériel identique ?
Pas toujours. Certains systèmes exigent du matériel ou des versions logicielles identiques, tandis que d’autres acceptent des nœuds mixtes. Toutefois, des différences de capacité ou de version peuvent affecter performance, bascule et supportabilité.
Quelle est la différence entre redondance et clustering ?
La redondance signifie disposer de composants de secours. Le clustering est une conception coordonnée où plusieurs composants travaillent sous une logique commune. Un cluster inclut généralement de la redondance, mais la redondance seule ne signifie pas toujours que le système est en cluster.
Pourquoi la bascule prend-elle parfois plus de temps que prévu ?
La bascule peut être retardée par temporisateurs de contrôle de santé, synchronisation de base de données, démarrage de service, convergence de routage, cache DNS, récupération de session ou étapes d’approbation manuelle. Ces facteurs doivent être testés avant la production.
Que faut-il documenter après le déploiement ?
La documentation doit inclure rôles des nœuds, adresses IP, dépendances de service, règles de bascule, comptes d’administration, seuils de supervision, procédures de sauvegarde, fenêtres de maintenance, étapes de reprise et responsabilités de contact.