

Dans de nombreuses pannes réseau, le premier problème visible n’est pas un commutateur cœur défaillant ni un serveur hors service. Il s’agit souvent d’une seule interface réseau instable. Comme les interfaces se trouvent au bord de chaque connexion, leur état influence directement la stabilité du service, la joignabilité des équipements et la rapidité de rétablissement. La maintenance quotidienne des interfaces réseau n’est donc pas une simple inspection de routine. C’est une méthode pratique pour éviter que de petits problèmes physiques ou logiques ne deviennent des défaillances de communication plus larges. Dans les réseaux de bureau, les centres de données, les salles de contrôle industriel, les systèmes de transport, les campus et les locaux techniques, le principe reste identique : si la couche d’interface n’est pas saine, les services supérieurs ne peuvent pas rester fiables longtemps.
Ce qu’il faut vérifier chaque jour
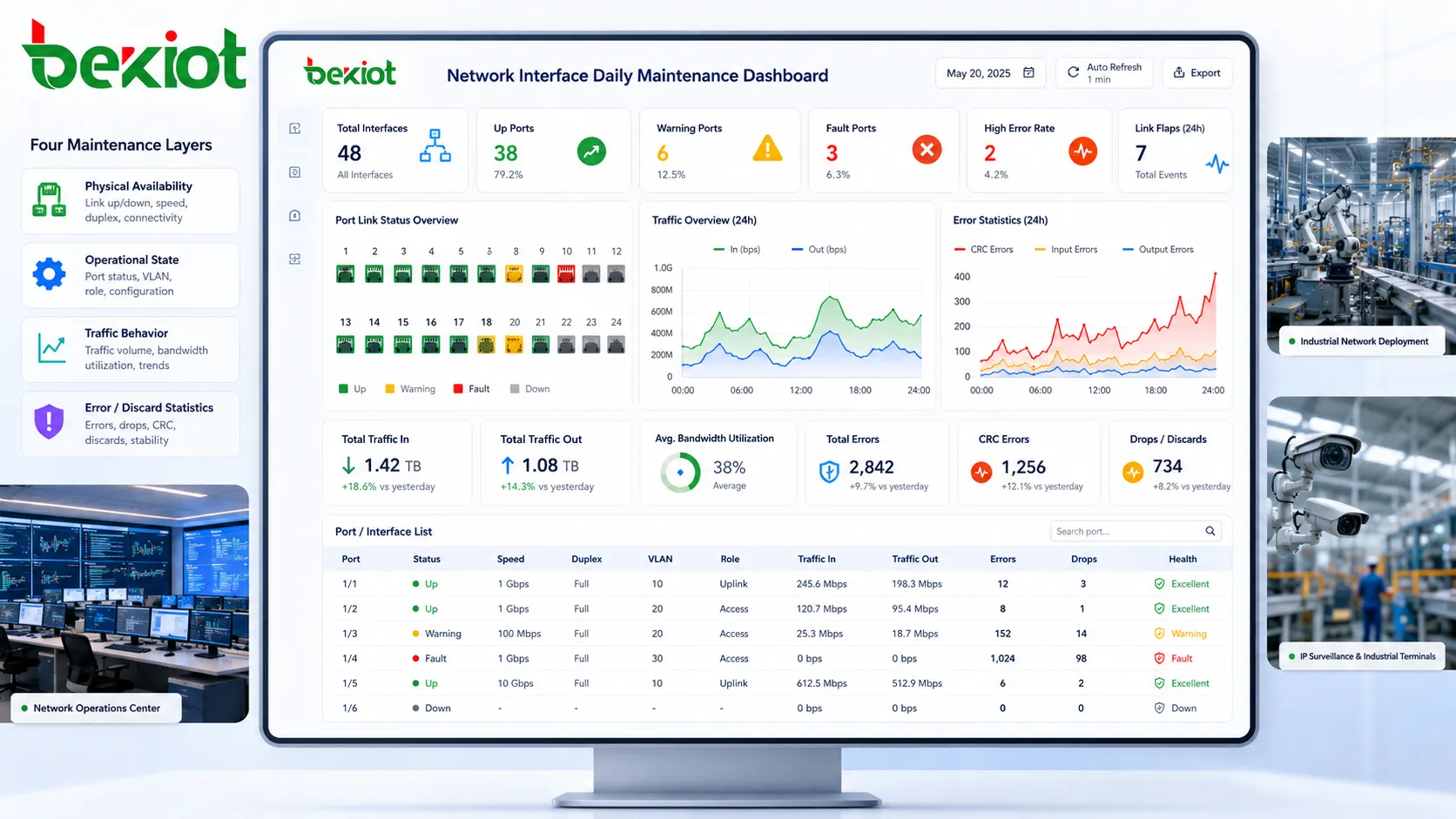
La maintenance quotidienne commence par la compréhension du fonctionnement attendu d’une interface réseau en situation normale. Un port peut sembler simple, mais il transporte plusieurs niveaux d’information : connectivité physique, qualité du signal électrique, vitesse négociée, mode duplex, appartenance VLAN, volume de trafic, statistiques d’erreurs, politique de sécurité et rôle de service. Vérifier seulement que le voyant de lien est allumé ne suffit pas pour une démarche professionnelle.
Le premier niveau est la disponibilité physique. Les ingénieurs doivent vérifier si l’interface est active, si le câble est correctement enfiché, si les voyants correspondent à la plateforme de supervision et si l’équipement connecté est censé être en ligne. Un port connecté mais désactivé administrativement, ou un port activé qui perd le lien de façon répétée, doit être analysé avant d’affecter le trafic de production.
Le deuxième niveau est l’état opérationnel. Il comprend la vitesse négociée, le mode duplex, la stabilité du lien, la description du port, l’affectation VLAN et le rôle de l’interface. Si un port gigabit négocie soudainement à 100 Mbps, la cause peut être la qualité du câble, un connecteur endommagé, la configuration du terminal ou un échec d’auto-négociation. Si le port appartient au mauvais VLAN, l’équipement peut être joignable physiquement mais isolé au niveau service.
Le troisième niveau est le comportement du trafic. Une interface saine doit présenter un modèle cohérent avec sa fonction. Un port utilisateur, serveur, uplink, caméra, terminal industriel ou point d’accès Wi-Fi n’aura pas le même profil normal. La maintenance quotidienne doit comparer le comportement actuel à une référence, et non uniquement à des seuils génériques.
Le quatrième niveau concerne les erreurs et les rejets. Les erreurs CRC, erreurs d’entrée, erreurs de sortie, erreurs d’alignement, collisions tardives, pertes de paquets et réinitialisations d’interface doivent être contrôlées régulièrement. Quelques compteurs historiques ne sont pas forcément urgents, mais une hausse continue pendant l’exploitation quotidienne est un signal d’alerte.
L’inspection physique reste plus importante que beaucoup d’équipes ne l’imaginent
Les plateformes de supervision peuvent afficher l’état des liens et les statistiques de trafic, mais elles ne montrent pas toujours l’état réel des câbles, panneaux de brassage, capuchons anti-poussière, contraintes dans la baie, rayons de courbure ou oxydation des connecteurs. Un port peut encore transmettre du trafic tout en présentant déjà des signes de défaillance future. L’inspection sur site reste donc importante, surtout dans les environnements soumis aux vibrations, à la poussière, à l’humidité, à la chaleur ou à des interventions fréquentes.
L’état des câbles est l’une des causes les plus courantes d’instabilité. Les câbles à paires torsadées peuvent avoir des clips cassés, des courbures excessives, un sertissage médiocre, des paires étirées, une catégorie inadaptée ou des dommages dus aux mouvements répétés. Les liens fibre peuvent souffrir de faces optiques sales, de rayon de courbure insuffisant, de jarretières de mauvaise qualité ou de connecteurs incompatibles. Ces défauts ne coupent pas toujours le service immédiatement, mais ils peuvent générer des pertes intermittentes ou des anomalies de négociation.
Les panneaux de brassage et répartiteurs doivent aussi être contrôlés. Les étiquettes doivent rester lisibles, les câbles doivent correspondre à la documentation et les ports inutilisés doivent être protégés de la poussière lorsque c’est nécessaire. Dans un local technique très sollicité, des changements de câblage non documentés compliquent les diagnostics futurs. Un environnement propre et bien identifié réduit le temps d’isolement des pannes en situation d’urgence.
Dans les sites industriels, l’environnement physique demande encore plus d’attention. Les interfaces proches des machines, armoires extérieures, tunnels, postes électriques, ateliers ou lignes de production peuvent subir bruit électrique, humidité, chocs mécaniques et variations de température. Le personnel doit vérifier les presse-étoupes, gaines de protection, points de terre et joints d’armoire. Dans ces environnements, une interface réseau fait partie du système terrain, pas seulement de l’informatique.
Une bonne inspection physique n’a pas besoin d’être complexe, mais elle doit être constante. Il faut rechercher les connexions lâches, gaines abîmées, courbures trop serrées, mélanges de câbles, équipements en surchauffe, accumulation de poussière, étiquettes manquantes et câbles suspendus sans support. Ces vérifications simples préviennent souvent des pannes que la supervision logicielle seule ne peut pas anticiper.
Vérification de l’état des ports et comparaison avec la référence
La vérification quotidienne des ports ne doit pas se limiter à savoir si une interface est up ou down. Une routine utile compare l’état actuel à l’état attendu. Si un port doit relier un serveur, il doit rester actif avec la vitesse et le VLAN prévus. S’il doit être inutilisé, il ne doit pas devenir actif sans raison. S’il porte un uplink, son trafic et ses erreurs doivent rester dans la plage attendue.
Les références sont importantes car les interfaces n’ont pas toutes le même comportement normal. Un uplink cœur peut maintenir un trafic élevé permanent. Un port caméra peut montrer un flux vidéo montant stable. Un port imprimante peut rester presque silencieux. Une interface PLC industrielle peut envoyer de petits paquets réguliers. Un port de secours peut rester inactif jusqu’au basculement. Sans référence, les ingénieurs risquent d’ignorer de vrais problèmes ou d’analyser inutilement des situations normales.
La vitesse et le duplex doivent être examinés avec attention. L’auto-négociation fonctionne généralement bien quand les câbles et terminaux sont sains, mais des anomalies restent possibles. Une différence entre la vitesse attendue et la vitesse réelle indique souvent un problème de câblage, une limite du terminal ou une erreur de configuration. Les désaccords duplex sont moins fréquents dans les réseaux modernes, mais peuvent encore provoquer une forte dégradation.
Les descriptions d’interface doivent aussi être entretenues. Des libellés comme « PLC Ligne 2 Armoire A », « CCTV Porte Nord », « Uplink cœur vers Switch-B » ou « Port 1 passerelle VoIP » accélèrent l’action. Les ports sans description ralentissent les contrôles quotidiens et augmentent le risque en dépannage d’urgence. La documentation doit refléter l’usage réel, et non un plan obsolète.
Dans les grands réseaux, des rapports automatisés peuvent signaler les écarts par rapport à la référence. Un port qui change de vitesse, change d’état, dépasse des seuils d’erreur ou s’active de manière inattendue doit être examiné. Le but n’est pas de multiplier les alarmes, mais de rendre visibles les changements anormaux avant les réclamations utilisateurs.
Les compteurs de trafic révèlent la pression cachée sur les liens
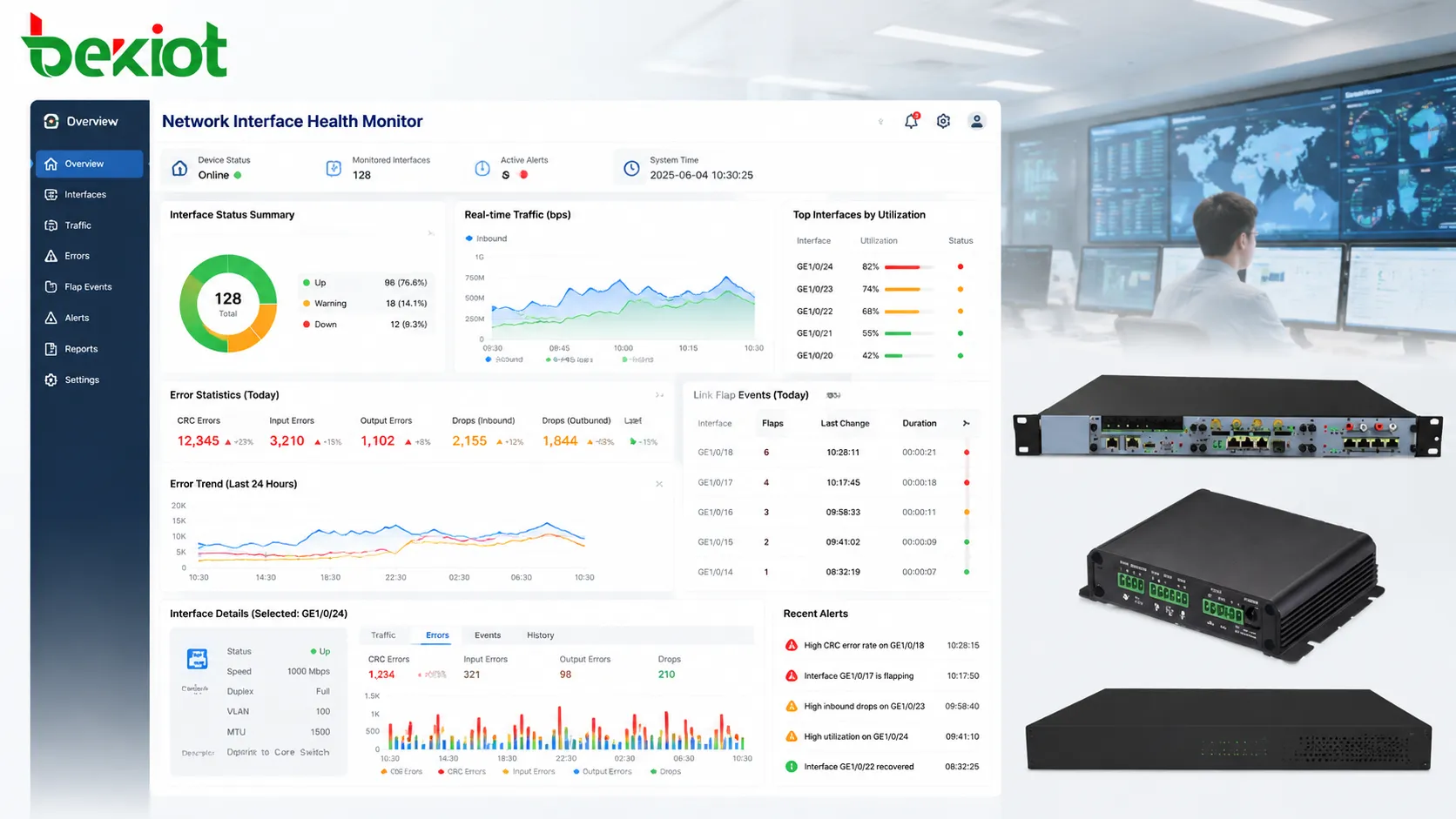
Les compteurs de trafic sont précieux parce qu’ils montrent l’utilisation réelle d’une interface. La maintenance quotidienne doit inclure l’usage de bande passante, le sens du trafic, les pics de charge, le broadcast, le multicast et les croissances inhabituelles. Ces indicateurs aident à identifier congestion, équipements mal configurés, boucles, applications anormales ou changements de service non prévus.
Une forte utilisation de bande passante n’est pas forcément une panne. Une sauvegarde, un flux vidéo, une synchronisation de fichiers ou un système de supervision peut consommer du trafic légitimement. La question est de savoir si le trafic correspond au rôle du port et à son horaire habituel. Si un port d’accès se comporte soudainement comme un uplink, ou si un équipement habituellement silencieux envoie beaucoup de trafic, la source doit être analysée avant d’impacter les services voisins.
Le broadcast et le multicast doivent être surveillés dans les réseaux comportant de nombreux équipements d’accès. Un broadcast excessif peut indiquer une boucle, un protocole de découverte mal configuré, une activité malveillante ou une segmentation insuffisante. Le multicast peut être normal pour la vidéo, la sonorisation ou le contrôle industriel, mais il doit être maîtrisé par des politiques de commutation et de routage adaptées. Le contrôle quotidien évite que ces flux dépassent leur périmètre prévu.
Les rejets de paquets sont un autre signal important. Ils peuvent provenir de congestion, de limites de mémoire tampon, de politiques QoS, d’erreurs d’interface ou de surabonnement. Quelques rejets ponctuels ne sont pas toujours urgents, mais des rejets continus ou croissants indiquent une pression sur le lien ou une classification de trafic inadaptée. Pour la voix, la vidéo, le contrôle et la communication d’urgence, même une perte modérée peut nuire à l’expérience.
Combinés au suivi temporel, les compteurs permettent d’identifier des motifs récurrents. Si un port sature chaque matin, la cause peut être une synchronisation planifiée. Si les pertes apparaissent seulement lors des changements d’équipe, elles peuvent venir du comportement utilisateur ou de pics d’authentification. Si le trafic augmente lentement sur plusieurs semaines, le site a peut-être besoin de planification de capacité plutôt que de réparation.
Les compteurs d’erreurs doivent être considérés comme des alertes précoces
Les compteurs d’erreurs sont souvent ignorés jusqu’aux plaintes des utilisateurs, alors qu’ils font partie des meilleurs indicateurs précoces de santé d’interface. Erreurs CRC, erreurs de trame, erreurs d’alignement, erreurs d’entrée, erreurs de sortie, collisions tardives et transitions de porteuse peuvent signaler des câbles défectueux, transceivers en panne, interférences électriques, vieillissement matériel ou incohérence de configuration.
Les erreurs CRC indiquent généralement que des trames sont corrompues avant d’être reçues correctement. Les causes courantes incluent câbles dégradés, connecteurs fibre sales, transceivers défectueux, interférences électromagnétiques ou instabilité de couche physique. Si les erreurs CRC continuent d’augmenter, il ne faut pas simplement effacer le compteur ; le chemin physique doit être inspecté, testé ou remplacé.
Les rejets d’entrée et de sortie doivent être interprétés avec prudence. Ils peuvent être liés à la congestion, au comportement QoS, à la pression des buffers ou à des limites matérielles. Sur un port d’accès, une hausse des rejets peut indiquer des rafales anormales d’un terminal. Sur un uplink, elle peut révéler un surabonnement ou une capacité insuffisante. Le sens dépend de la position de l’interface dans le réseau.
Les événements de flapping sont particulièrement importants. Un port qui monte et descend à répétition peut perturber les appels voix, flux vidéo, sessions de contrôle et enregistrements de dispositifs. Le flapping peut venir de connecteurs lâches, câbles fatigués, alimentation instable du terminal, carte réseau défectueuse ou problème de port switch. Même si le lien revient vite, les interruptions répétées dégradent la fiabilité.
La revue quotidienne doit se concentrer sur les tendances plutôt que sur des valeurs isolées. Un compteur qui a augmenté de plusieurs milliers depuis hier mérite attention. Un port avec la même valeur historique depuis des mois peut simplement porter d’anciens enregistrements. Les équipes doivent noter les remises à zéro de compteurs et les réparations afin de distinguer les nouvelles pannes des anciennes données.
Câbles, transceivers et liens optiques doivent être traités séparément
Les différents médias d’interface exigent des méthodes de maintenance différentes. Les liens Ethernet cuivre, les liens fibre optique et les liens à modules enfichables apparaissent tous comme des interfaces réseau, mais leurs modes de défaillance ne sont pas les mêmes. Les traiter avec une checklist unique peut faire manquer des détails importants.
Pour les liens cuivre, la catégorie du câble, la longueur, la qualité de terminaison, l’environnement de mise à la terre et l’exposition électromagnétique sont essentiels. Un câble Cat5e peut suffire au gigabit dans de nombreux cas, mais une terminaison médiocre ou une courbure excessive peut encore causer des anomalies de négociation. Les câbles proches de moteurs, de lignes électriques ou d’équipements industriels doivent être routés avec soin.
Pour les liens fibre, la propreté et les niveaux de puissance optique sont centraux. De la poussière sur la face d’un connecteur peut causer perte, réflexion ou erreurs intermittentes. Les équipes doivent utiliser des outils de nettoyage adaptés plutôt que toucher les connecteurs à la main. Les puissances d’émission et de réception doivent être comparées à la plage acceptable du module et du design du lien. Un lien encore actif mais proche de la limite basse peut tomber avec la température ou le vieillissement.
Les transceivers doivent être vérifiés pour la compatibilité, la température, les journaux d’erreurs et les diagnostics optiques disponibles. Les informations DDM peuvent révéler puissance reçue, puissance émise, température, tension et courant de polarisation laser. Ces valeurs aident à identifier les modules vieillissants ou les liens marginaux avant la panne totale.
La gestion des pièces de rechange compte également. Les câbles, modules SFP, jarretières et adaptateurs doivent correspondre au parc réel du site. En maintenance d’urgence, une pièce inadaptée peut rétablir provisoirement le lien tout en créant une instabilité durable. Des contrôles d’inventaire quotidiens ou hebdomadaires garantissent la disponibilité des bons composants.
L’hygiène de configuration évite les problèmes silencieux
Toutes les pannes d’interface ne sont pas physiques. Beaucoup de problèmes proviennent de dérives de configuration : VLAN modifié pendant un dépannage puis jamais restauré, trunk sans VLAN autorisé, port d’accès dans le mauvais segment, fonction de sécurité désactivée ou description obsolète. L’hygiène de configuration consiste à garder des paramètres exacts, intentionnels et documentés.
La maintenance quotidienne doit inclure l’examen des changements récents. Si la configuration d’un port a été modifiée, la raison doit être enregistrée. Si un réglage temporaire a servi à résoudre une urgence, il doit ensuite être revu puis officialisé ou retiré. Les corrections temporaires sont utiles en urgence, mais deviennent des risques lorsqu’elles sont oubliées.
Les VLAN demandent une attention particulière. Un port peut être link-up et pourtant ne pas fournir le service s’il est dans le mauvais VLAN. Un trunk peut laisser passer certains services et en bloquer d’autres si la liste des VLAN autorisés est incomplète. VLAN voix, gestion, caméras, contrôle industriel et invités doivent être vérifiés avec les documents de conception. Une petite erreur VLAN peut isoler des équipements ou les exposer au mauvais réseau.
La sécurité de port, le storm control, la protection de boucle, le spanning tree, LLDP, PoE et QoS doivent aussi être révisés selon le rôle du port. Un port caméra, point d’accès Wi-Fi, téléphone VoIP, PLC, serveur et uplink n’a pas nécessairement besoin du même modèle. Une bonne maintenance confirme que chaque interface est configurée pour son usage réel.
La sauvegarde de configuration fait partie de cette hygiène. Si un équipement tombe en panne ou si une configuration est écrasée, une sauvegarde récente réduit le temps de restauration. Pour les commutateurs et routeurs importants, les sauvegardes quotidiennes ou planifiées doivent être considérées comme une partie de la maintenance des interfaces, car les paramètres de port sont souvent les premières informations nécessaires.
Contrôles de sécurité à la périphérie du réseau
Les interfaces réseau ne sont pas seulement des chemins de trafic ; ce sont aussi des points d’accès. Un port ouvert oublié, un équipement non autorisé, un commutateur non administré, un point d’accès pirate ou un ordinateur de maintenance mal utilisé peut créer un risque. La maintenance quotidienne doit donc inclure des contrôles de sécurité de base, surtout dans les réseaux critiques ou industriels.
Les ports inutilisés doivent être désactivés ou placés dans un VLAN isolé selon la politique du site. Les ports actifs doivent avoir une description claire et des équipements connus. Si la supervision signale une nouvelle adresse MAC sur un port sensible, il faut vérifier si elle est attendue. Dans les sites stricts, l’association MAC, l’authentification 802.1X, la sécurité de port ou le contrôle d’accès réseau peuvent être nécessaires.
La sécurité d’interface comprend aussi la surveillance du trafic anormal. Scans soudains, tempêtes broadcast inattendues, anomalies ARP ou échecs d’authentification répétés peuvent indiquer une mauvaise configuration, un malware ou une tentative d’accès non autorisé. La revue quotidienne ne remplace pas une plateforme de sécurité complète, mais elle aide à repérer les changements suspects à la périphérie physique.
L’accès d’administration doit être séparé de l’accès de service autant que possible. Les interfaces de gestion des commutateurs, ports hors bande, consoles et VLAN d’administration doivent être protégés. Un port de maintenance connecté au mauvais réseau peut devenir un point faible. La sécurité au niveau interface est souvent pratique, locale et facile à négliger.
Une bonne maintenance de sécurité ne consiste pas à rendre chaque port complexe. Elle consiste à rendre chaque interface active intentionnelle. Si un port est utilisé, l’équipe doit savoir ce qu’il relie, quel trafic il doit porter et quels contrôles s’appliquent. S’il n’est pas utilisé, il ne doit pas rester silencieusement disponible pour quiconque trouve un câble.

Les interfaces PoE exigent de vérifier alimentation et données ensemble
Les interfaces Power over Ethernet demandent une attention particulière car elles transportent données et alimentation sur le même câble. Les téléphones IP, points d’accès Wi-Fi, caméras, terminaux d’interphonie, contrôleurs d’accès et capteurs industriels peuvent dépendre entièrement du PoE. Si le port présente un problème d’alimentation, l’équipement peut redémarrer, perdre son enregistrement, perdre la vidéo ou disparaître de la supervision même si la configuration données est correcte.
Les contrôles PoE quotidiens doivent inclure consommation, puissance allouée, budget disponible du commutateur, état du port, classe du dispositif et cycles d’alimentation anormaux. Un commutateur peut avoir assez de ports mais pas assez de puissance pour tous les équipements en charge de pointe. Si plusieurs équipements puissants démarrent en même temps, certains ports peuvent ne pas fournir une alimentation stable sans planification correcte.
L’état du câble influence aussi la fiabilité PoE. Du cuivre de mauvaise qualité, de longues distances, des conducteurs abîmés ou des terminaisons faibles peuvent causer chute de tension ou alimentation instable. Un équipement peut fonctionner à faible charge puis redémarrer lorsque la demande augmente. C’est fréquent avec les caméras PTZ, points d’accès Wi-Fi ou dispositifs activant chauffage, haut-parleurs ou modules additionnels.
Pour les équipements critiques, il faut vérifier si le commutateur fournit journaux et alarmes PoE adaptés. Les coupures d’alimentation inattendues ne doivent pas être ignorées. Si un appareil redémarre souvent, la cause peut être l’alimentation instable plutôt que la perte de paquets. Remplacer l’équipement final sans examiner le comportement PoE peut ne pas résoudre le problème.
Dans les systèmes d’urgence et de communication, la planification PoE doit inclure l’alimentation de secours. Si les commutateurs ne sont pas reliés à un UPS ou à une alimentation redondante, les équipements alimentés tomberont lors d’une coupure. Maintenir les interfaces PoE signifie vérifier l’état du port et la conception globale de continuité électrique.
La documentation transforme les contrôles quotidiens en vraie maintenance
La maintenance quotidienne ne crée de valeur durable que si les constats sont enregistrés. Sans documentation, le même problème peut être analysé plusieurs fois par différents ingénieurs, des correctifs temporaires peuvent être oubliés et les changements d’interface deviennent difficiles à suivre. Une bonne documentation relie port physique, configuration logique, équipement connecté, rôle de service et historique de maintenance.
Un enregistrement utile doit inclure nom du commutateur, numéro de port, description du port, équipement connecté, emplacement, VLAN, vitesse, mode duplex, état PoE si applicable, chemin de câble, référence de panneau de brassage et responsable du service. Pour les liens importants, il faut aussi indiquer le trafic de référence, l’état attendu sans erreur et les informations de câble ou transceiver de rechange.
Les journaux de maintenance doivent noter les anomalies et les actions réalisées. Si un câble est remplacé, notez la date et la raison. Si un compteur est effacé, consignez-le afin de mesurer correctement les hausses futures. Si un VLAN est modifié, documentez l’approbation et l’objectif. Ces enregistrements ne sont pas de la paperasse ; ils améliorent les diagnostics futurs et réduisent les suppositions.
La documentation visuelle est également utile. Photos de baies, schémas de panneaux, cartes de ports et captures de topologie aident quand les ingénieurs doivent agir vite. Dans les sites distribués, le personnel local ne connaît pas toujours la conception complète ; des dossiers clairs aident les ingénieurs distants à guider le dépannage.
La meilleure documentation est pratique et à jour. Un schéma parfait mais vieux de six mois est moins utile qu’un simple tableau de ports fidèle à la réalité. La maintenance quotidienne des interfaces doit intégrer de petites mises à jour documentaires à chaque changement du réseau.
Construire une checklist quotidienne sans la rendre mécanique
Une checklist quotidienne est utile, mais elle ne doit pas devenir un formulaire rempli aveuglément. Son but est d’aider les ingénieurs à remarquer les changements, pas de répéter la même réponse chaque jour. Une bonne liste combine des points fixes avec de la place pour le jugement selon les conditions du site et les événements récents.
Les contrôles typiques incluent état up/down, changements de lien inattendus, vitesse et duplex, fortes hausses de compteurs d’erreur, forte utilisation, broadcast ou multicast anormal, alarmes PoE, ports actifs non autorisés et changements récents de configuration. Les uplinks critiques, liens serveurs, passerelles, ports de contrôle industriel, caméras de sécurité et ports voix doivent recevoir plus d’attention que les ports d’accès ordinaires à faible risque.
La priorité doit dépendre de l’impact métier. Un port relié à une imprimante du réseau visiteurs n’a pas le même risque qu’un port relié à un uplink cœur, une passerelle de communication d’urgence, un contrôleur de production ou un commutateur d’agrégation vidéo. La maintenance quotidienne doit d’abord viser les liens qui affectent la sécurité, la production, la continuité de communication ou de nombreux utilisateurs.
L’automatisation peut aider en collectant les compteurs, en comparant les références et en générant des rapports d’exception. Cependant, elle ne doit pas supprimer la perception terrain. Une plateforme peut indiquer qu’un port est up, alors qu’un technicien voit une jarretière tendue, mal étiquetée ou exposée aux dommages. Associer revue de données et inspection visuelle occasionnelle donne de meilleurs résultats que l’une ou l’autre seule.
L’objectif final est simple : rendre visibles tôt les interfaces anormales, réparer les petits problèmes avant qu’ils ne deviennent des interruptions et garder la périphérie réseau prévisible. La checklist doit servir cet objectif sans transformer les ingénieurs en lecteurs passifs de rapports.
Questions fréquentes
À quelle fréquence faut-il effacer les compteurs d’interface ?
Les compteurs ne doivent pas être effacés machinalement chaque jour, car les valeurs historiques aident à repérer les tendances longues. Effacez-les après avoir enregistré une référence, terminé une réparation ou commencé une période d’observation ciblée. Notez toujours l’heure d’effacement pour interpréter correctement les hausses futures.
Que vérifier en premier lorsqu’un port flappe ?
Commencez par le chemin physique : insertion du câble, état du connecteur, panneau de brassage, alimentation de l’équipement final et qualité du câble. Si la couche physique semble stable, vérifiez la négociation de vitesse, le comportement PoE, l’état de la carte réseau et les journaux du commutateur.
Les ports de commutateur inutilisés doivent-ils toujours être désactivés ?
Dans la plupart des réseaux administrés, oui. La désactivation des ports inutilisés réduit le risque d’accès non autorisé et évite les branchements accidentels. Si un site a besoin de ports temporaires de maintenance, ils doivent être clairement étiquetés, restreints et revus régulièrement.
Pourquoi une interface est-elle up alors que l’équipement ne communique pas ?
L’état link-up confirme seulement la connectivité physique. L’équipement peut encore être dans le mauvais VLAN, bloqué par une politique d’accès, sans adresse IP, affecté par une panne DHCP, associé au mauvais profil de port ou incapable d’atteindre la passerelle requise.
Quelles informations inclure dans un dossier de maintenance d’interface ?
Au minimum, indiquez nom de l’équipement, numéro de port, terminal connecté, emplacement, VLAN, vitesse, mode duplex, chemin de câble, rôle du port, changements récents, historique des pannes et paramètres spéciaux comme PoE, mode trunk, sécurité de port ou politique QoS.







